

No voy a explicar cómo funcionan los modelos de transformadores, sino a mostrar sus aplicaciones en casos de uso multilingüe. En este artículo voy a abordar la clasificación de textos en swahili mediante transformadores, para ello, voy a utilizar conjuntos de datos en swahili para entrenar transformadores multilingües y a los que se puede acceder desde el propio chatbot para entender el problema recogido para resolver.
Asumo que el lector tiene conocimientos previos de Machine learning clásico y Deep learning.
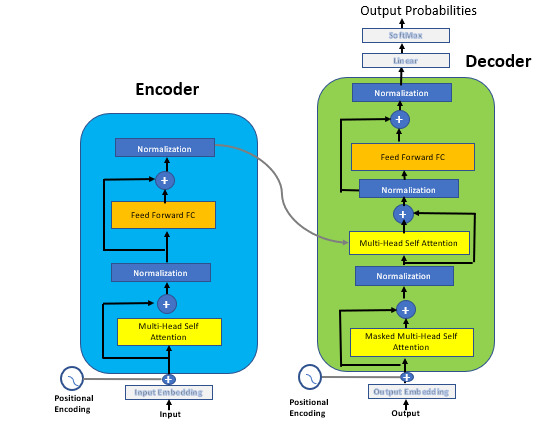
Los transformadores son modelos de deep learning de transferencia que se entrenan con un gran conjunto de datos para realizar diferentes casos de uso en el campo del procesamiento del lenguaje natural, como la clasificación de textos, la respuesta a preguntas, la traducción automática o el reconocimiento del habla, entre otros.
Según la Wikipedia, los transformadores son modelos de deep learning que adoptan el mecanismo de la autoatención, ponderando deferentemente la importancia de cada parte de los datos de entrada. Se utilizan principalmente en los campos del Procesamiento del Lenguaje Natural (NLP) y la Visión por Computador (CV).
El entrenamiento de los modelos de Deep Learning con conjuntos de datos pequeños tiene más probabilidades de enfrentarse a un sobreajuste, ya que el Deep Learning es esencial para el reconocimiento de patrones complejos con una gran cantidad de parámetros, por lo que requiere grandes conjuntos de datos para funcionar/generalizar bien con la naturaleza de los desafíos.
La ventaja de usar transformadores es el entrenamiento sobre un gran corpus de datos de Wikipedia y diferentes colecciones de libros, lo que facilita las cosas cuando se trata de validar este modelo con el nuevo conjunto de datos para su problema específico.
Algunas de las técnicas que conozco cuando se trata de trabajar con otros retos utilizando conjuntos de datos que no están en inglés, como los sentimientos en árabe, los sentimientos en swahili, los sentimientos en alemán, etc.
- Traduce tus datos (datos de tu propio idioma) al inglés y luego resuelve el reto utilizando modelos entrenados en inglés. Esto depende de la naturaleza del problema que intentas resolver o de si crees que hay un modelo perfecto para realizar la tarea de traducción.
- Aumenta tus datos de entrenamiento (datos de su propio idioma). Esto puede hacerse tomando un gran conjunto de datos en inglés y traduciéndolo a tu propio idioma para hacer frente a la naturaleza del reto que estás resolviendo y luego combinarlo con los pequeños datos de tu propio idioma y después afinar los modelos de los transformadores.
- La última técnica consiste en volver a entrenar los modelos grandes (transformadores) con los datos de tu propio idioma, lo que se conoce como Aprendizaje por Transferencia en el Procesamiento del Lenguaje Natural, y ésta es la técnica con la que trabajaré hoy.
Vamos a sumergirnos en el tema principal de este artículo, vamos a entrenar un modelo de transformador para la clasificación de noticias en swahili, ya que los transformadores son grandes para hacer la tarea simple tenemos que seleccionar una envoltura para trabajar, si eres bueno con PyTorch puedes utilizar PyTorch Lightning una envoltura para la investigación de alto rendimiento de la IA, para envolver los transformadores, pero hoy vamos a ir con ktrain de Tensorflow Python Library.
Ktrain es una librería de deep learning TensorFlow, Keras (y otras bibliotecas) para ayudar a construir, entrenar y desplegar redes neuronales y otros modelos de aprendizaje automático. Inspirado en extensiones de marcos de trabajo de ML como fastai y ludwig, ktrain está diseñado para hacer que el aprendizaje profundo y la IA sean más accesibles y fáciles de aplicar tanto para los recién llegados como para los profesionales experimentados.
Con sólo unas pocas líneas de código, ktrain te permite realizar tareas de forma fácil y rápida.Si quieres saber más sobre ktrain puedes acceder aquí. Recomiendo usar google colab o kaggle kernel, para hacer la tarea simple, y el poder computacional de estas plataformas puede hacer que las cosas sean un poco más sencillas.
La primera tarea es actualizar pip e instalar ktrain en tu entorno de trabajo, esto se puede hacer simplemente ejecutando algunos comandos:
# update pip package & install ktrain!pip install -U pip
!pip install ktrain
A continuación, importa todas las bibliotecas necesarias para el preprocesamiento de datos de texto y otros fines computacionales:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import os
from nltk import word_tokenize
import string
import reimport warnings
warnings.filterwarnings("ignore")
Es hora de cargar nuestro conjunto de datos e inspeccionar su aspecto y las características que contiene:
# loading datasets from data dir df = pd.read_csv("data/Train.csv")# Total Records print("Total Records: ", df.shape[0])# % preview data from top df.head() 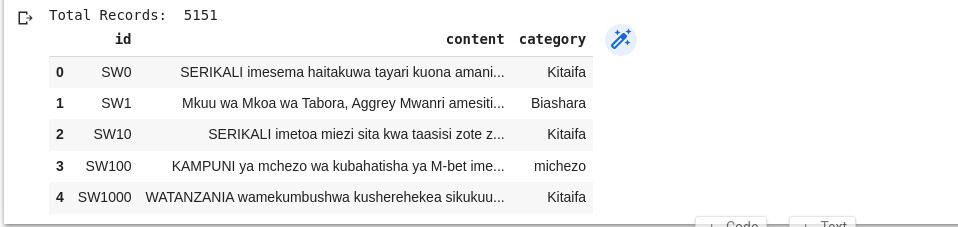
Puedes ver que los conjuntos de datos tienen 3 columnas ID como identificación única de cada sentimiento/noticia, contenido que contiene la noticia, y categoría que contiene etiquetas de cada noticia/sentimiento específico. A continuación, vamos a visualizar la columna de destino para entender la distribución de cada clase de noticias del conjunto de datos.
# Let's visualize the Label distiributions using seaborn plt.figure(figsize=(15,7)) sns.countplot(x='category',data=df) plt.title("DISTRIBUTION OF LABELS") plt.show() 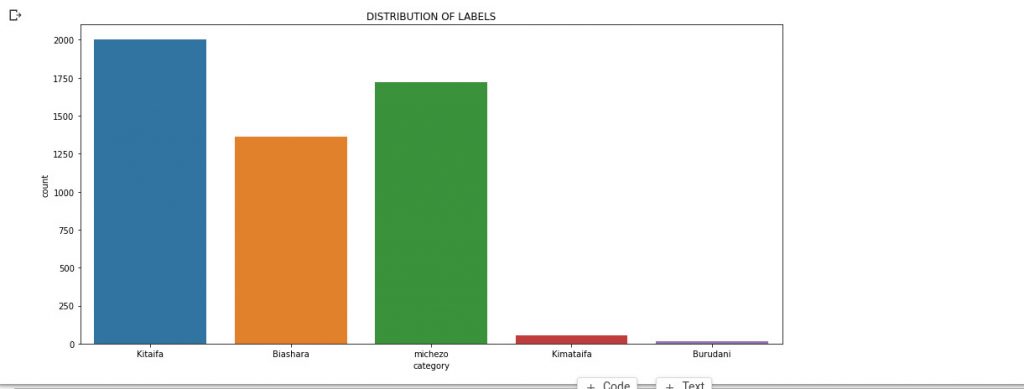
Se puede ver que el conjunto de datos con el que estamos trabajando contiene 5 clases (etiquetas) y no está bien equilibrado porque la mayoría de las noticias recogidas son de kitaifa mientras que una minoría de ellas eran de kimataifa y Burudani.
Entonces podemos considerar primero la limpieza del texto antes de ajustarlo a nuestro transformador, eliminando la puntuación, los dígitos, convirtiendo a minúsculas, eliminando los espacios en blanco innecesarios, eliminando los emojis, eliminando las palabras de parada, la tokenización, etc. He creado la función clean_text para realizar estas tareas:
# function to clean text
def clean_text(sentence):
'''
function to clean content column, make it ready for transformation and modeling
'''
sentence = sentence.lower() #convert text to lower-case
sentence = re.sub('‘','',sentence) # remove the text ‘ which appears to occur flequently
sentence = re.sub('[‘’“”…,]', '', sentence) # remove punctuation
sentence = re.sub('[()]', '', sentence) #remove parentheses
sentence = re.sub("[^a-zA-Z]"," ",sentence) #remove numbers and keep text/alphabet only
sentence = word_tokenize(sentence) # remove repeated characters (tanzaniaaaaaaaa to tanzania)
return ' '.join(sentence)
Entonces, es el momento de aplicar nuestro clean_text al contenido:
# Applying our clean_text function on contents df['content'] = df['content'].apply(clean_text) df.head()
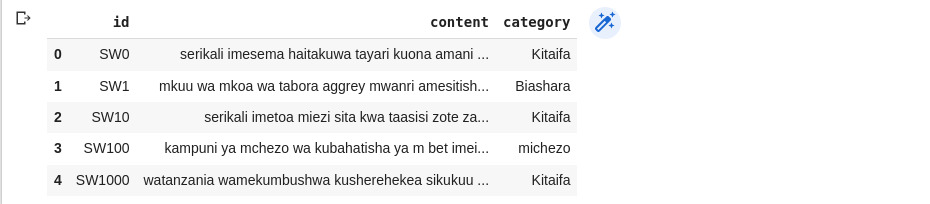
Ahora puedes notar la diferencia en el contenido de nuestros conjuntos de datos.
A continuación, vamos a dividir los conjuntos de datos en conjuntos de entrenamiento y validación, el conjunto de entrenamiento se utilizará para entrenar nuestro modelo, y el conjunto de validación para la validación del modelo de su rendimiento en los nuevos datos:
df = df[['category', 'content']]
SEED = 2020
df_train = df.sample(frac=0.85, random_state=SEED)
df_test = df.drop(df_train.index)
len(df_train), len(df_test)
El 85% de los conjuntos de datos se utilizará para entrenar el modelo y el 15% se utilizará para validar nuestro modelo para ver si se generaliza bien y evaluar el rendimiento. No olvides siempre establecer el valor de la semilla para ayudar a obtener resultados predecibles y repetibles cada vez. Si no establecemos la semilla, entonces obtendremos diferentes números aleatorios en cada invocación.
Con la API de transformadores en ktrain, podemos seleccionar cualquier modelo de transformadores Hugging Face apropiado para nuestros datos. Dado que estamos tratando con el swahili, utilizaremos el BERT multilingüe que normalmente utiliza ktrain para los conjuntos de datos no ingleses en la API text_classifier alternativa de ktrain. Pero se puede optar por cualquier otro modelo transformador multilingüe.
Vamos a importar ktrain y a establecer algunos parámetros comunes para nuestro modelo, lo importante es especificar qué modelo de transformador vas a utilizar, y luego asegurarte de que es compatible con el problema que estás resolviendo. Establezcamos nuestro modelo transformador como bert-base-multilingual-uncased y parámetros como:
- MAXLEN especifica que se consideren las primeras 128 palabras del contenido de cada noticia. Esto se puede ajustar dependiendo de la potencia de cálculo de su máquina, tenga cuidado con él siempre que lo ponga alto significa que quiere cubrir un contenido grande y si su máquina no es capaz de manejar tal cálculo llorará con «error de recurso agotado», así que asegúrese de tener esto en cuenta.
- batch_size como el número de ejemplos de entrenamiento utilizados en una iteración, vamos a utilizar 32
- learning_rate como la cantidad de pesos que se actualizan durante el entrenamiento, vamos a usar learning_rate de 5e-5, también puedes ajustarlo para ver cómo se comporta tu modelo, se recomienda que sea pequeño.
- epochs el número de pasadas del conjunto de datos de entrenamiento que el algoritmo tiene que completar, vamos a utilizar 3 epochs por ahora para que nuestro modelo utilice unos pocos minutos.
import ktrain
from ktrain import text# selecting transformer to use
MODEL_NAME = 'bert-base-multilingual-uncased'# %Common parameters
MAXLEN = 128
batch_size = 32
learning_rate = 5e-5
epochs = 3
Después de la configuración de los parámetros. Es el momento de entrenar nuestro primer transformador con conjuntos de datos en swahili, especificando el conjunto de entrenamiento y validación para que la función del preprocesador trabaje con el texto y después de ajustar nuestro modelo para que pueda aprender de los conjuntos de datos.
El proceso puede tardar un par de minutos en completarse, dependiendo de la potencia de cálculo de tu elección.
t = text.Transformer(MODEL_NAME, maxlen = MAXLEN)
trn = t.preprocess_train(df_train.content.values, df_train.category.values)
val = t.preprocess_test(df_test.content.values, df_test.category.values)
model = t.get_classifier()
learner = ktrain.get_learner(model, train_data=trn, val_data=val, batch_size=batch_size)
learner.fit(learning_rate, epochs)
Vaya, felicidades, la tarea de entrenar los transformadores para los conjuntos de datos en swahili ha terminado y ahora toca probar el rendimiento de nuestro modelo en swahili que hemos entrenado.

He copiado el primer contenido de la noticia del archivo Train.csv para ver cómo el modelo swahili puede trabajar con él y hace la clasificación correcta porque la frase es larga se puede comprobar en el cuaderno.
Intentemos predecir con contenidos cortos que estén dentro de esas categorías (Kitaifa, michezo, Biashara, Kimataifa, Burudani) de los conjuntos de datos utilizados para entrenar este modelo y luego veamos cuál será el resultado.
Swahili = “Simba SC ni timu bora kwa misimu miwili iliyopita katika ligi kuu ya Tanzania”
English = “Simba S.C are the best team for the last two seasons in the Tanzanian Premier League “

Es cierto que el contenido de este texto se basa en los deportes (Michezo), así es como puedes entrenar tu propio modelo transformador para la clasificación de noticias en swahili.
Si quieres acceder a los códigos completos utilizados en este artículo aquí tienes.
Gracias, espero que hayas disfrutado y aprendido mucho de este artículo, no dudes en compartirlo con otros.
Este artículo fue publicado en el blog Neurotech Africa.