

Escrito por Ezequiel Munoz Krsulovic en Planeta Chatbot.
Qué mejor que mostrar cosas concretas en relación a problemas reales. Bueno, en este artículo utilizo el post de Kimberly Coffey escrito en Agosto del 2016, y lo pueden encontrar completo en: http://www.kimberlycoffey.com/blog/2016/8/k-means-clustering-for-customer-segmentation. Alguna parte del código la he cambiado, pero esencialmente es el mismo documento, sólo que además he explicado cada línea que se está programando.
Quien no ha escuchado esas frases (1) “Amazon no mató a los minoristas, el mal servicio y la experiencia del cliente lo hicieron”; (2) “UBER no mató a los taxis, el acceso limitado, el mal servicio y el control de las tarifas lo hicieron”; (3) “Apple no mató a la industria de la música, el obligar a comprar álbumes completos lo hizo”; (4) “Netflix no mató a Blockbuster, los ridículos cargos por pagos atrasados lo hicieron”. Tras las frases hay una reflexión importante, y que no tiene que ver con la tecnología, ella sólo es un habilitante de la mirada que tienen estas compañías respecto del cliente, el no centrarse en el cliente es la mayor amenaza de cualquier negocio. En este artículo lo que quiero presentar es una mirada de cómo la tecnología me ayuda a entender una realidad compleja que hay detrás de las transacciones de nuestros clientes. Tenemos que aprender a trabajar en esta línea, seamos nosotros o con ayuda de otros, pero, sinceramente les digo, no hay alternativa, tenemos que utilizar los datos para generar mayor competitividad en los negocios.
Estamos en el caso equivalente de mi artículo anterior, que hablaba de la estrategia y analítica, con una situación de una empresa que tiene que hacer una acción de negocios respecto de sus clientes. El tema es cómo toma foco, a quiénes pone énfasis, cómo toma la decisión, todas preguntas válidas, pues tenemos presupuestos limitados y debemos ser certeros en las decisiones de marketing y ventas que realicemos.
Bueno, asumiré que el que quiera probar lo que mostraré tiene R y RStudio cargado. Sino, hay muchos post que hablan de ello, además de los sitios de R y RStudio. Esa no es una limitante, y la verdad que está muy bien documentado, y el que tenga algún problema me puede escribir y trataremos de solucionarlo. Por último, le pide a un amigo que sepa que lo haga por él, y ve lo interesante del tratamiento, modelamiento y resultados que se obtienen.
Primero referenciemos la fuente de datos, que está en esta dirección: https://archive.ics.uci.edu/ml/datasets/Online+Retail. Los datos están en formato de planilla, y el nombre de la fuente es: Online Retail.xlsx. Son 541.909 registros de transacciones entre 01/dic/2010 y 09/dic/2011. Copien el archivo de datos a un lugar conocido para que lo puedan referenciar desde su programa en R. Los atributos que se consideran según el sitio UCI son (coloco las definiciones originales de los atributos):
- InvoiceNo: Invoice number. Nominal, a 6-digit integral number uniquely assigned to each transaction. If this code starts with letter ‘c’, it indicates a cancellation.
- StockCode: Product (item) code. Nominal, a 5-digit integral number uniquely assigned to each distinct product.
- Description: Product (item) name. Nominal.
- Quantity: The quantities of each product (item) per transaction. Numeric.
- InvoiceDate: Invice Date and time. Numeric, the day and time when each transaction was generated.
- UnitPrice: Unit price. Numeric, Product price per unit in sterling.
- CustomerID: Customer number. Nominal, a 5-digit integral number uniquely assigned to each customer.
- Country: Country name. Nominal, the name of the country where each customer resides.
Con la segmentación dividiremos a los clientes en grupos que compartan ciertas características. La agrupación que elijamos dependerá del negocio, de lo que buscamos apoyar en el negocio, pues hay infinitas combinaciones. Tal como comenta el autor, la segmentación puede ser realizada en función de una variedad de características de los clientes:
- Región geográfica
- Demografía (edad, sexo, estado civil, ingresos, etc.)
- Psicográficas (valores, intereses, estilo de vida, pertenencia a grupos, etc.)
- Comportamiento de compra (compras previas, preferencias de despacho, páginas vistas en el website, etc.)
En el caso del dataset comentado arriba, contiene datos de comportamiento, que son en general los más fáciles de obtener. Nuestra meta será encontrar segmentos que sean de alto y bajo valor, desde la perspectiva de acciones de marketing a realizar.
Ahora la secuencia de código en R para lograr lo que nos hemos propuesto, con las explicaciones en cada caso y las salidas obtenidas (que están comentadas por si alguien toma el código y lo va copiando a un archivo R), para que sepan lo que estamos haciendo paso a paso:
# directorio de trabajo --------------------------- # # seteo del directorio por default, tengo que dejar las salidas en algún lugar común setwd("~/Data/LinkedIn/") # getwd() # [1] "/Users/ezequieltomas/Data/LinkedIn"# carga de datos --------------------------- # # carga de la librería para cargar archivos xlsx if (! ("readxl" %in% rownames(installed.packages()))) { install.packages("readxl", dependencies = TRUE) } library(readxl) # lectura de los datos raw.data <- read_excel("~/Data/LinkedIn/Online Retail.xlsx", sheet = "Online Retail", na = "NA") # # dejamos raw.data de respaldo y trabajamos con el dataset data que creamos a partir de raw.data data <- raw.data # nrow(data) # [1] 541909Visualicemos un poco por dentro el dataset:
# cómo está la estructura del dataset data?str(data)Classes ‘tbl_df’, ‘tbl’ and 'data.frame':541909 obs. of 8 variables: $ InvoiceNo : chr "536365" "536365" "536365" "536365" ... $ StockCode : chr "85123A" "71053" "84406B" "84029G" ... $ Description: chr "WHITE HANGING HEART T-LIGHT HOLDER" "WHITE METAL LANTERN" "CREAM CUPID HEARTS COAT HANGER" "KNITTED UNION FLAG HOT WATER BOTTLE" ... $ Quantity : num 6 6 8 6 6 2 6 6 6 32 ... $ InvoiceDate: POSIXct, format: "2010-12-01 08:26:00" ... $ UnitPrice : num 2.55 3.39 2.75 3.39 3.39 7.65 4.25 1.85 1.85 1.69 ... $ CustomerID : num 17850 17850 17850 17850 17850 ... $ Country : chr "United Kingdom" "United Kingdom" "United Kingdom" "United Kingdom" ...
Y ahora la estadística básica:
summary(data) InvoiceNo StockCode Length:541909 Length:541909 Class :character Class :character Mode :character Mode :character Description Quantity Length:541909 Min. :-80995.00 Class :character 1st Qu.: 1.00 Mode :character Median : 3.00 Mean : 9.55 3rd Qu.: 10.00 Max. : 80995.00 InvoiceDate UnitPrice Min. :2010-12-01 08:26:00 Min. :-11062.06 1st Qu.:2011-03-28 11:34:00 1st Qu.: 1.25 Median :2011-07-19 17:17:00 Median : 2.08 Mean :2011-07-04 13:34:57 Mean : 4.61 3rd Qu.:2011-10-19 11:27:00 3rd Qu.: 4.13 Max. :2011-12-09 12:50:00 Max. : 38970.00 CustomerID Country Min. :12346 Length:541909 1st Qu.:13953 Class :character Median :15152 Mode :character Mean :15288 3rd Qu.:16791 Max. :18287 NA's :135080
Requerimos tratar un poco a los datos:
# redefiniendo los tipos de datos --------------------------- # # los que son factores, los dejamos como factores data$InvoiceNo <- as.factor(as.character(data$InvoiceNo)) data$StockCode <- as.factor(as.character(data$StockCode)) data$Description <- as.factor(as.character(data$Description)) data$CustomerID <- as.factor(as.character(data$CustomerID)) data$Country <- as.factor(as.character(data$Country)) # revisión y ajuste del CustomerID --------------------------- # # cuántos valores únicos hay de CustomerID? length(unique(data$CustomerID)) # [1] 4373 # # cuántos CustomerID con NA? sum(is.na(data$CustomerID)) # [1] 135080 # # respaldamos antes de realizar la operación de limpieza de NAs dataold1<- data # # eliminamos los CustomerID con NAs data <- subset(data, !is.na(data$CustomerID)) # # cuántos registros quedan? nrow(data) # [1] 406829# revisión y ajuste de la fecha de la invoice --------------------------- # # no está en formato fecha, por lo que realizamos la creación de un nuevo atributo data$InvoiceDateFF<-as.Date(substr(as.character(data$InvoiceDate),1,10)) # # qué rango de fechas hay? range(data$InvoiceDateFF) # [1] "2010-12-01" "2011-12-09" # # eliminamos el atributo anterior de fecha data$InvoiceDate <-NULL
Seleccionaremos un año de datos para realizar nuestros cálculos:
# respaldamos antes de realizar la operación de selección de un año de datos dataold2<- data # # seleccionaremos los datos de un año, por lo que tomaremos el caso: InvoiceDate >= "2010-12-09" data <- data[which(data$InvoiceDateFF >= as.Date("2010-12-09","%Y-%m-%d")),] # # cuántos registros quedan? nrow(data) # [1] 393848 # # entonces el rango de fechas quedo como sigue range(data$InvoiceDateFF) # [1] "2010-12-09" "2011-12-09" # # cómo es el resumen ahora? summary(data) InvoiceNo StockCode 576339 : 542 85123A : 1984 579196 : 533 22423 : 1836 580727 : 529 85099B : 1615 578270 : 442 47566 : 1408 573576 : 435 84879 : 1364 567656 : 421 20725 : 1332 (Other):390946 (Other):384309 Description WHITE HANGING HEART T-LIGHT HOLDER: 1977 REGENCY CAKESTAND 3 TIER : 1836 JUMBO BAG RED RETROSPOT : 1615 PARTY BUNTING : 1408 ASSORTED COLOUR BIRD ORNAMENT : 1364 LUNCH BAG RED RETROSPOT : 1331 (Other) :384317 Quantity UnitPrice Min. :-80995.00 Min. : 0.00 1st Qu.: 2.00 1st Qu.: 1.25 Median : 5.00 Median : 1.95 Mean : 12.13 Mean : 3.47 3rd Qu.: 12.00 3rd Qu.: 3.75 Max. : 80995.00 Max. :38970.00 CustomerID Country 17841 : 7839 United Kingdom:349806 14911 : 5774 Germany : 9274 14096 : 5128 France : 8313 12748 : 4279 EIRE : 7351 14606 : 2660 Spain : 2528 15311 : 2396 Netherlands : 2369 (Other):365772 (Other) : 14207 InvoiceDateFF Min. :2010-12-09 1st Qu.:2011-04-17 Median :2011-08-05 Mean :2011-07-17 3rd Qu.:2011-10-23 Max. :2011-12-09Como hay estudios previos de que los segmentos varían por ciudad, seleccionaremos una en particular:
# tenemos las siguientes alternativas: table(data$Country) Australia Austria 1237 401 Bahrain Belgium 17 2057 Brazil Canada 32 151 Channel Islands Cyprus 758 622 Czech Republic Denmark 30 389 EIRE European Community 7351 61 Finland France 695 8313 Germany Greece 9274 146 Hong Kong Iceland 0 151 Israel Italy 250 778 Japan Lebanon 342 45 Lithuania Malta 0 127 Netherlands Norway 2369 939 Poland Portugal 333 1413 RSA Saudi Arabia 58 10 Singapore Spain 229 2528 Sweden Switzerland 462 1871 United Arab Emirates United Kingdom 68 349806 Unspecified USA 244 291 # seleccionaremos United Kingdom, que es la que más datos tiene # # repaldamos antes de reducir el data set dataold3 <- data # # y ahora seleccionamos la ciudad data <- subset(data, Country == "United Kingdom") # # las filas que quedan son: nrow(data) # [1] 349806 # # Y el número de Invoice y CustomerID únicos son: length(unique(data$InvoiceNo)) # [1] 19140 length(unique(data$CustomerID)) # [1] 3891
Bien, hasta ahí tenemos la data preparada para trabajar. Ahora procederemos a realizar el cálculo de las variables del modelo RFM: recency, frecuency y monetary. Asumimos que es un tema conocido (de igual forma en el sitio referido está la explicación).
# identificar los retornos --------------------------- # data$item.return <- grepl("C", as.character(data$InvoiceNo), fixed=TRUE) data$purchase.invoice <- ifelse(data$item.return=="TRUE", 0, 1)# creación de variables RFM --------------------------- # # primero crearemos un dataset de clientes que completaremos después customers <- as.data.frame(unique(data$CustomerID)) # dejamos la columna con el nombre de CustomerID names(customers) <- "CustomerID" # # ahora el cálculo del recency # data$recency <- as.Date("2011-12-10") - data$InvoiceDateFF # # removemos los retornos, sonsiderando sólo las compras: *purchase*, y lo dejamos en una tabla temporal temp <- subset(data, purchase.invoice == 1)# obtenemos el número de días desde la compra más reciente y lo dejamos en otra tabla temporal recency <- aggregate(recency ~ CustomerID, data=temp, FUN=min, na.rm=TRUE) # eliminamos la tabla temporal temp remove(temp)# agregamos el recency a la tabla de clientes que creamos customers <- merge(customers, recency, by="CustomerID", all=TRUE, sort=TRUE) # eliminamos la tabla temporal recency remove(recency) # dejamos como numérico el recency en la tabla de clientes customers$recency <- as.numeric(customers$recency) # # ahora el cálculo del frecuency # # seleccionamos algunos atributos customer.invoices <- subset(data, select = c("CustomerID","InvoiceNo", "purchase.invoice")) # eliminamos los duplicados customer.invoices <- customer.invoices[!duplicated(customer.invoices), ] # ordenamos con CustomerID customer.invoices <- customer.invoices[order(customer.invoices$CustomerID),] row.names(customer.invoices) <- NULL # obtenemos el número de facturas por año solo para las compras annual.invoices <- aggregate(purchase.invoice ~ CustomerID, data=customer.invoices, FUN=sum, na.rm=TRUE) #cambiamos el nombre de la columna que agregó los datos a frecuency names(annual.invoices)[names(annual.invoices)=="purchase.invoice"] <- "frequency" # lo agregamos a los datos del cliente customers <- merge(customers, annual.invoices, by="CustomerID", all=TRUE, sort=TRUE) # eliminamos los datasets que ya no necesitamos remove(customer.invoices, annual.invoices) # veamos cómo quedó frecuency range(customers$frequency) # [1] 0 196 table(customers$frequency) 0 1 2 3 4 5 6 7 8 9 10 28 1357 722 466 348 218 157 112 85 62 43 11 12 13 14 15 16 17 18 19 20 21 56 30 26 23 18 12 15 14 10 10 5 22 23 24 25 26 27 28 29 30 32 33 7 6 4 9 4 3 5 1 3 1 2 34 35 37 38 39 41 44 45 46 49 50 3 2 1 2 1 2 3 1 1 1 1 54 56 57 60 83 88 90 94 121 196 1 1 1 2 1 1 1 1 1 1 # removamos los clientes que no tienen ninguna compra en el año pasado customers <- subset(customers, frequency > 0) # veamos cuántos clientes nos quedan nrow(customers) # [1] 3863 # # ahora el cálculo del monetary # # calculemos el total gastado en cada item de cada factura data$Amount <- data$Quantity * data$UnitPrice # agreguemos el total de ventas por cliente annual.sales <- aggregate(Amount ~ CustomerID, data=data, FUN=sum, na.rm=TRUE) # cambiemos el nombre de la columna a monetary names(annual.sales)[names(annual.sales)=="Amount"] <- "monetary" # # agreguemos la columna monetary a nuestro dataset de clientes customers <- merge(customers, annual.sales, by="CustomerID", all.x=TRUE, sort=TRUE) # eliminemos el dataset temporal remove(annual.sales)Luego debemos identificar clientes con valor negativo en monetary, para eliminarlos de la data, ellos presumiblemente tienen retornos de compras del año anterior, miremos el siguiente histograma:
hist(customers$monetary)

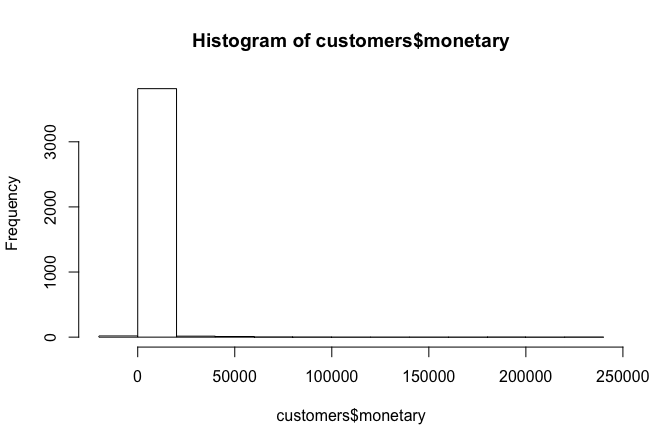
Efectivamente hay negativos. Eliminamos los valores negativos.
customers$monetary <- ifelse(customers$monetary < 0, 0, customers$monetary) # reset negative numbers to zero # ahí desaparecieron hist(customers$monetary)


Ahora aplicaremos la regla clásica del 80/20 para considerar a los clientes más importantes (del orden del 20%) que nos generan la mayor cantidad de ventas (del orden del 80%).
# ordenamos los clientes de mayor a menor monetary customers <- customers[order(-customers$monetary),] # calculamos el corte del 80% pareto.cutoff <- 0.8 * sum(customers$monetary) # de acuerdo a este corte clasificamos a los clientes customers$pareto <- ifelse(cumsum(customers$monetary) <= pareto.cutoff, "Top 20%", "Bottom 80%") # dejamos el atributo como factor customers$pareto <- factor(customers$pareto, levels=c("Top 20%", "Bottom 80%"), ordered=TRUE) # vemos los niveles levels(customers$pareto) # [1] "Top 20%" "Bottom 80%" # y vemos la proporción que nos quedaron round(prop.table(table(customers$pareto)), 2) Top 20% Bottom 80% 0.29 0.71 # eliminamos la variable que creamos para el corte remove(pareto.cutoff) # dejamos los datos ordenados por CustomerID customers <- customers[order(customers$CustomerID),]Ahora viene el tema del clustering. Para ello, tenemos que seleccionar un k para el número de clusters, por lo que démosle una vista a los datos:
# carguemos otras librerías para ver los datos if (! ("ggplot2" %in% rownames(installed.packages()))) { install.packages("ggplot2", dependencies = TRUE) } if (! ("scales" %in% rownames(installed.packages()))) { install.packages("scales", dependencies = TRUE) } library(ggplot2) library(scales) # visualicemos los datos con las variables frecuency y monetary, para ver si podemos ver algo razonable scatter.1 <- ggplot(customers, aes(x = frequency, y = monetary)) scatter.1 <- scatter.1 + geom_point(aes(colour = recency, shape = pareto)) scatter.1 <- scatter.1 + scale_shape_manual(name = "80/20 Designation", values=c(17, 16)) scatter.1 <- scatter.1 + scale_colour_gradient(name="Recency\n(Days since Last Purchase))") scatter.1 <- scatter.1 + scale_y_continuous(label=dollar) scatter.1 <- scatter.1 + xlab("Frequency (Number of Purchases)") scatter.1 <- scatter.1 + ylab("Monetary Value of Customer (Annual Sales)") scatter.1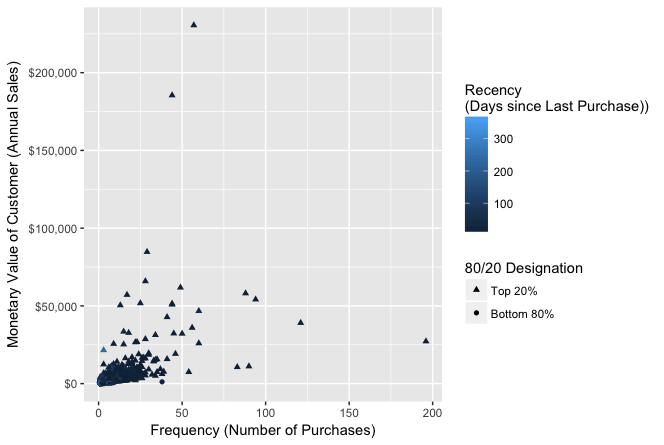
Está difícil para esta visualización, por lo que dado que vamos a utilizar el clustering del tipo k-means, realizaremos algún preprocesamiento para ello:
# transformación logarítmica de las variables RFM customers$recency.log <- log(customers$recency) customers$frequency.log <- log(customers$frequency) # no podemos tener logaritmo de 0 customers$monetary.log <- customers$monetary + 0.1 customers$monetary.log <- log(customers$monetary.log) # cálculo de los Z-scores para las variables RFM customers$recency.z <- scale(customers$recency.log, center=TRUE, scale=TRUE) customers$frequency.z <- scale(customers$frequency.log, center=TRUE, scale=TRUE) customers$monetary.z <- scale(customers$monetary.log, center=TRUE, scale=TRUE) # # visualización con los datos logarítmicos scatter.2 <- ggplot(customers, aes(x = frequency.log, y = monetary.log)) scatter.2 <- scatter.2 + geom_point(aes(colour = recency.log, shape = pareto)) scatter.2 <- scatter.2 + scale_shape_manual(name = "80/20 Designation", values=c(17, 16)) scatter.2 <- scatter.2 + scale_colour_gradient(name="Log-transformed Recency") scatter.2 <- scatter.2 + xlab("Log-transformed Frequency") scatter.2 <- scatter.2 + ylab("Log-transformed Monetary Value of Customer") scatter.2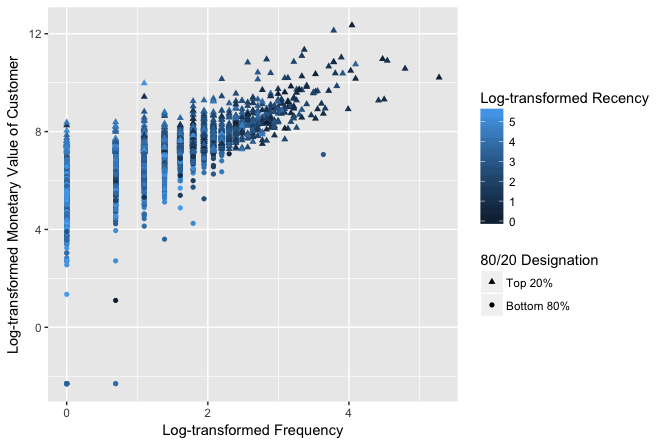
Graficando con los Z obtenemos lo mismo, por lo que no lo presentaremos (se los dejo de tarea). En este punto es donde debe analizarse si incluir datos fuera de rango o no (outliers). Es necesario definir si los incluimos o no. Para este caso, es interesante dejarlos, pues son justamente casos que nos interesa analizar (revisar las consideraciones en el documento original).
Ahora, para el cálculo del k, realizaremos un ciclo iterativo, que mostramos a continuación, con el objeto de examinar cuál k es el que más nos conviene desde el punto de vista del negocio:
# cargamos la librería para kmeans if (! ("plyr" %in% rownames(installed.packages()))) { install.packages("plyr", dependencies = TRUE) } library(plyr) # # seleccionamos las columnas 9 a la 11 del dataset de clientes para trabajar preprocessed <- customers[,9:11] # fijamos en un máximo de 10 clusters para probar j <- 10 # creamos un data frame para alojar los resultados models <- data.frame(k=integer(), tot.withinss=numeric(), betweenss=numeric(), totss=numeric(), rsquared=numeric()) # aquí ciclo para iterar kmeans de 1 a 10 y obtener los resultados for (k in 1:j ) { # mostramos el k del ciclo print(k) # ejecutar kmeans output <- kmeans(preprocessed, centers = k, nstart = 20) # agregamos al data set de clientes la participación de en qué cluster queda, para análisis posterior var.name <- paste("cluster", k, sep="_") customers[,(var.name)] <- output$cluster customers[,(var.name)] <- factor(customers[,(var.name)], levels = c(1:k)) # graficamos los clusters cluster_graph <- ggplot(customers, aes(x = frequency.log, y = monetary.log)) cluster_graph <- cluster_graph + geom_point(aes(colour = customers[,(var.name)])) colors <- c('red','orange','green3','deepskyblue','blue','darkorchid4','violet','pink1','tan3','black') cluster_graph <- cluster_graph + scale_colour_manual(name = "Cluster Group", values=colors) cluster_graph <- cluster_graph + xlab("Log-transformed Frequency") cluster_graph <- cluster_graph + ylab("Log-transformed Monetary Value of Customer") title <- paste("k-means Solution with", k, sep=" ") title <- paste(title, "Clusters", sep=" ") cluster_graph <- cluster_graph + ggtitle(title) print(cluster_graph) # vemos los centros print(title) cluster_centers <- ddply(customers, .(customers[,(var.name)]), summarize, monetary=round(median(monetary),2), frequency=round(median(frequency),1), recency=round(median(recency), 0)) names(cluster_centers)[names(cluster_centers)=="customers[, (var.name)]"] <- "Cluster" print(cluster_centers) cat("\n") cat("\n") # recolectamos la información del modelo corrido models[k,("k")] <- k models[k,("tot.withinss")] <- output$tot.withinss models[k,("betweenss")] <- output$betweenss # la suma de las dos anteriores models[k,("totss")] <- output$totss # betweenss + tot.withinss # porcentaje de la varianza explicada models[k,("rsquared")] <- round(output$betweenss/output$totss, 3) assign("models", models, envir = .GlobalEnv) # removemos los datos de la iteración remove(output, var.name, cluster_graph, cluster_centers, title, colors) } # eliminamos en k remove(k)Obtenemos como salida de texto por la consola los siguientes resultados para k desde 1 a 10:
[1] 1 [1] "k-means Solution with 1 Clusters" Cluster monetary frequency recency 1 1 626.99 2 50 [1] 2 [1] "k-means Solution with 2 Clusters" Cluster monetary frequency recency 1 1 327.50 1 96 2 2 1797.78 5 17 [1] 3 [1] "k-means Solution with 3 Clusters" Cluster monetary frequency recency 1 1 3213.34 9 8 2 2 921.10 3 34 3 3 259.44 1 144 [1] 4 [1] "k-means Solution with 4 Clusters" Cluster monetary frequency recency 1 1 1140.64 4 52 2 2 372.90 2 20 3 3 258.76 1 178 4 4 3152.82 9 8 [1] 5 [1] "k-means Solution with 5 Clusters" Cluster monetary frequency recency 1 1 3187.97 9 8 2 2 1173.34 4 48 3 3 283.20 1 174 4 4 360.01 2 19 5 5 0.00 1 135 [1] 6 [1] "k-means Solution with 6 Clusters" Cluster monetary frequency recency 1 1 1136.77 4 60 2 2 0.00 1 110 3 3 303.87 1 37 4 4 257.70 1 216 5 5 1083.71 4 9 6 6 4359.97 12 9 [1] 7 [1] "k-means Solution with 7 Clusters" Cluster monetary frequency recency 1 1 4706.14 13 5 2 2 266.35 1 39 3 3 2140.07 6 30 4 4 838.70 3 10 5 5 773.44 3 86 6 6 223.47 1 233 7 7 0.00 1 110 [1] 8 [1] "k-means Solution with 8 Clusters" Cluster monetary frequency recency 1 1 714.42 2 99 2 2 0.00 1 110 3 3 216.63 1 236 4 4 2083.42 6 34 5 5 632.97 2 18 6 6 1903.59 6 5 7 7 250.38 1 45 8 8 7170.25 18 5 [1] 9 [1] "k-means Solution with 9 Clusters" Cluster monetary frequency recency 1 1 267.13 1 48 2 2 815.02 3 26 3 3 388.65 2 8 4 4 1985.79 6 6 5 5 2369.28 6 38 6 6 0.00 1 135 7 7 705.12 2 116 8 8 212.93 1 240 9 9 7454.07 18 5 [1] 10 [1] "k-means Solution with 10 Clusters" Cluster monetary frequency recency 1 1 411.86 1 186 2 2 808.51 3 25 3 3 0.00 1 110 4 4 148.70 1 236 5 5 2315.01 6 38 6 6 234.34 1 38 7 7 645.65 2 120 8 8 7454.07 18 5 9 9 440.78 2 5 10 10 2015.01 6 6
Y, para efectos de análisis, mostraremos los clusters que se armaron para el valor de k de 2, 3, 5 y 10:
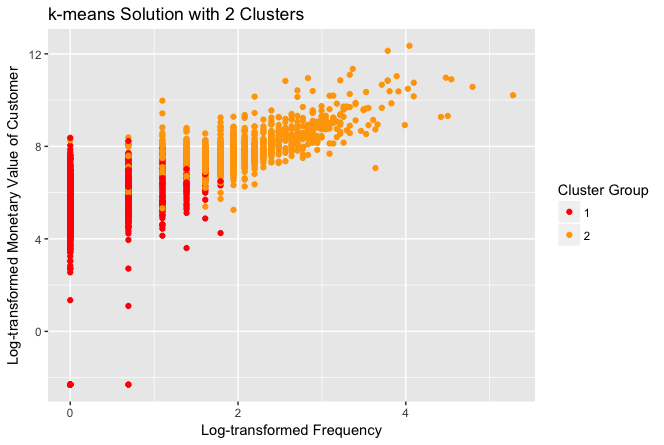
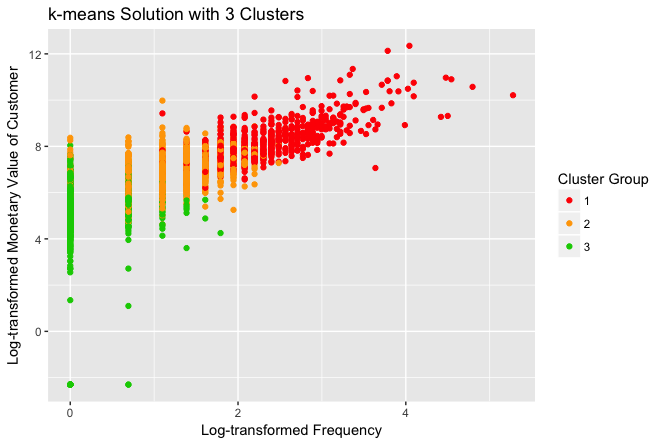
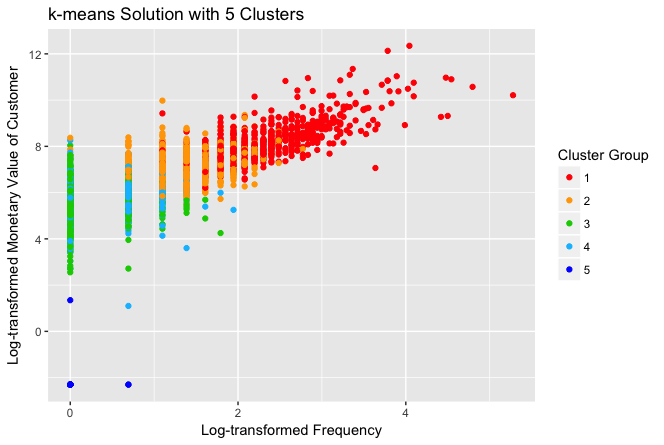

Visiblemente, con la selección de k=2 es más claro que el resto, pero desde el punto de vista de los datos obtenidos en la salida de texto de la consola, la selección de k=5 presenta un cluster, el 5, con un grupo de monetary=0.00 y además un cluster, el 1, con un grupo de más alto monetary y frecuency, y más bajo recency; que nos permite hacer una mejor distribución de las acciones comerciales.
Busquemos otra forma para complementar la toma de decisión. Calculemos y grafiquemos la explicación de la varianza en los clusters realizados y una mirada al método del codo para seleccionar el k.
# gráfico de la varianza explicada según el número de clusters r2_graph <- ggplot(models, aes(x = k, y = rsquared)) r2_graph <- r2_graph + geom_point() + geom_line() r2_graph <- r2_graph + scale_y_continuous(labels = scales::percent) r2_graph <- r2_graph + scale_x_continuous(breaks = 1:j) r2_graph <- r2_graph + xlab("k (Number of Clusters)") r2_graph <- r2_graph + ylab("Variance Explained") r2_graph# gráfico de la suma de cuadrados por el número de clusters (codo) ss_graph <- ggplot(models, aes(x = k, y = tot.withinss)) ss_graph <- ss_graph + geom_point() + geom_line() ss_graph <- ss_graph + scale_x_continuous(breaks = 1:j) ss_graph <- ss_graph + scale_y_continuous(labels = scales::comma) ss_graph <- ss_graph + xlab("k (Number of Clusters)") ss_graph <- ss_graph + ylab("Total Within SS") ss_graphLos gráficos obtenidos son los siguientes:

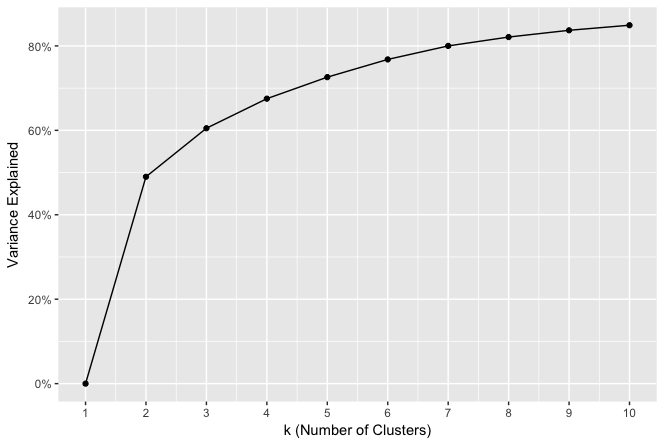

Al revisar la varianza explicada con cada k iterado, nos damos cuenta que la solución de k=2 sólo explica el 49% de la varianza, mientras que con k=5 logramos explicar el 72% de la varianza.
¿Cuál sería la conclusión? Por mi parte, yo elijo el de k=5 para hacer estrategias diferenciadas. Claramente con k=5 tenemos dos grupos diferentes que podemos abordar con estrategias de marketing y ventas específicas. La tabla de clientes queda con las asignaciones de los clusters por cada k probado, con ello saben en qué cluster queda cada uno de los clientes para cada k, y así poder identificarlos para las acciones de negocio que quieran realizar.
Estamos llegando al final. Fue un ejemplo bien completo, utilizando varias estrategias intermedias para tratar los datos, luego depurarlos y prepararlos para luego concluir con la construcción de los modelos. Este tipo de modelamiento es el denominado como no supervisado, según la jerga, y podemos utilizarlo en muchas otras situaciones cuando necesitamos “descubrir” un nuevo conocimiento.
Aprovechen lo escrito en R para otros casos.
Cuéntenme si quieren un tipo de ejemplo en particular, y se los fabrico. Mientras seguiré viendo que otro hay por ahí para explicarlo bien.
Agradezco al autor (referido al inicio) y todos los créditos por el buen trabajo realizado en el ejemplo que tomamos (código R) para este artículo.
De acuerdo a UCI hay papers relevantes que pueden acceder, que son:
1) The evolution of direct, data and digital marketing, Richard Webber, Journal of Direct, Data and Digital Marketing Practice (2013) 14, 291–309. 2) Clustering Experiments on Big Transaction Data for Market Segmentation, 3) Ashishkumar Singh, Grace Rumantir, Annie South, Blair Bethwaite, Proceedings of the 2014 International Conference on Big Data Science and Computing. 4) A decision-making framework for precision marketing, Zhen You, Yain-Whar Si, Defu Zhang, XiangXiang Zeng, Stephen C.H. Leung c, Tao Li, Expert Systems with Applications, 42 (2015) 3357–3367.
Un abrazo. ¡Qué tengan muy buena semana!
LinkedIn / Ezequiel / 2018–02–07.