

Las plataformas como Google Assistant facilitan la creación de asistentes de voz personalizados (chatbots). Pero, ¿qué pasaría si quisieras crear un asistente que se ejecute localmente y garantice la privacidad de tus datos? Puedes hacerlo utilizando las herramientas de código abierto Rasa, Mozilla DeepSpeech y Mozilla TTS. Si quieres saber cómo, echa un vistazo a este tutorial.
Con plataformas como Google Assistant y Alexa que son cada vez más populares, los asistentes de voz están destinados a ser la próxima herramienta para las interacciones con los clientes en varias industrias. Sin embargo, a menos que utilices soluciones comerciales alojadas, el desarrollo de asistentes de voz viene con un conjunto completamente nuevo de desafíos que van más allá de la NLU y la gestión del diálogo; además de esos temas, debes ocuparte de la transcripción del habla a texto, componentes de texto a voz, la interfaz… Tocamos el tema de la voz hace algún tiempo cuando experimentamos con la construcción de un Google Assistant con tecnología Rasa. Aprovechar plataformas como Google Assistant elimina el obstáculo de implementar el procesamiento de voz y los frontend components, pero obliga a comprometer la seguridad de tus datos y la flexibilidad de las herramientas que utilizas. Entonces, ¿qué opciones tienes si deseas crear un asistente de voz que se ejecute localmente y garantice la seguridad de tus datos? Bueno, descubrámoslo. En este post, aprenderás cómo puedes crear un asistente de voz utilizando solo herramientas de código abierto, desde el backend hasta la interfaz.
Tabla de contenidos
Outline
- Resumen de herramientas y software
- El asistente de Rasa
- Implementación del componente de voz a texto
- Implementación del componente de texto a voz
- Poniéndolo todo junto
- ¿Qué sigue?
- Resumen y recursos
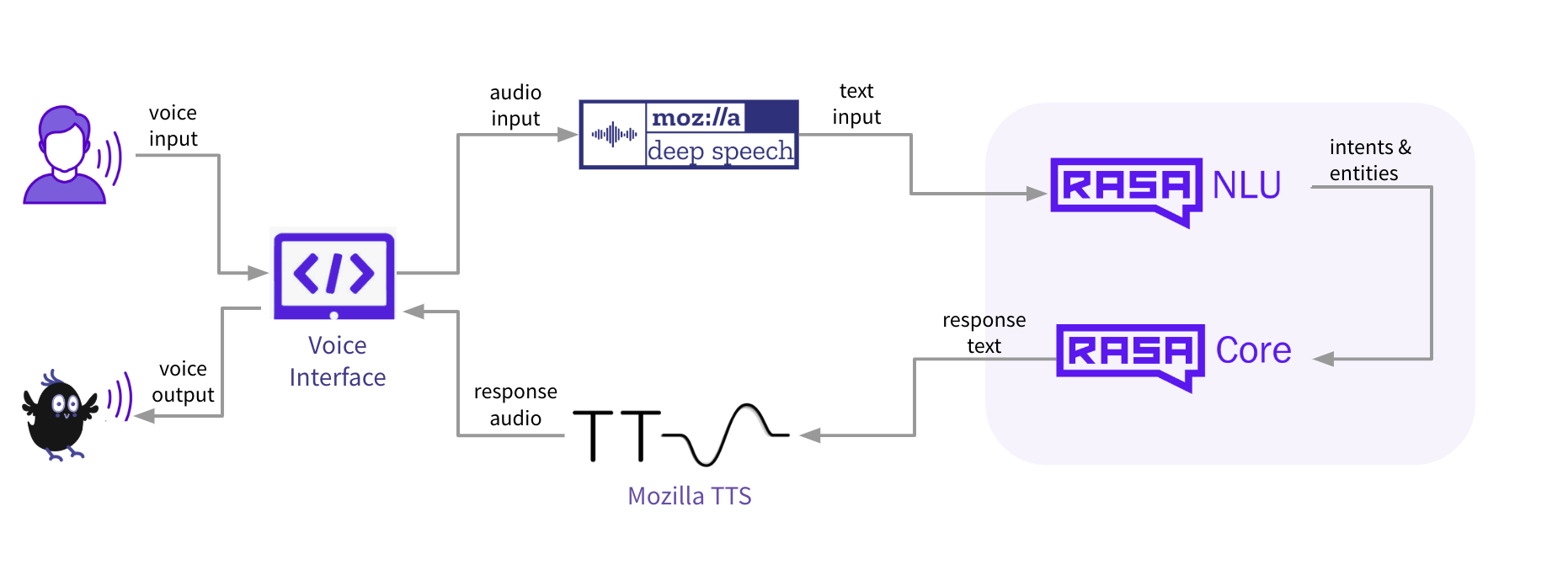
1. Herramientas y descripción general del software
El objetivo de esta publicación es mostrarte cómo puedes crear tu propio asistente de voz utilizando solo herramientas de código abierto. En general, hay cinco componentes principales que son necesarios para construir un asistente de voz:
- Interfaz de voz: una interfaz que los usuarios usan para comunicarse con el asistente (aplicación web o móvil, altavoz inteligente, etc.)
- Voz a texto (STT) : un componente de procesamiento de voz que toma la entrada del usuario en un formato de audio y produce una representación de texto
- NLU: un componente que toma la entrada del usuario en formato de texto y extrae datos estructurados (intentos y entidades) que ayuda a comprender lo que el usuario quiere
- Gestión del diálogo: un componente que determina cómo debe responder un asistente en un estado específico de la conversación y genera esa respuesta en un formato de texto
- Texto a voz (TTS): un componente que toma la respuesta del asistente en un formato de texto y produce una representación de voz que luego se envía al usuario.

Si bien Rasa de código abierto es una opción bastante obvia para NLU y la gestión de diálogo, decidir sobre STT y TTS es una tarea más difícil simplemente porque no hay muchos marcos de código abierto para elegir. Después de explorar las opciones disponibles actualmente: CMUSphinx, Mozilla DeepSpeech, Mozilla TTS, Kaldi, decidimos utilizar las herramientas de Mozilla : Mozilla DeepSpeech y Mozilla TTS . Esto es porque:
- Las herramientas de Mozilla vienen con un conjunto o modelos pre-entrenados, pero también puedes entrenar los tuyos usando datos personalizados. Esto te permite implementar cosas rápidamente, pero también te da toda la libertad para construir componentes personalizados.
- En comparación con las alternativas, las herramientas de Mozilla parecen ser las más independientes del sistema operativo.
- Ambas herramientas están escritas en Python, lo que facilita un poco la integración con Rasa.
- Tiene una comunidad de código abierto grande y activa lista para ayudar con preguntas técnicas.
¿Qué es Mozilla DeepSpeech y Mozilla TTS? Mozilla DeepSpeech es un marco de voz a texto que toma la entrada del usuario en un formato de audio y utiliza el aprendizaje automático para convertirlo a un formato de texto que luego puede ser procesado por la NLU y el sistema de diálogo. Mozilla TTS se encarga de lo contrario: toma la entrada (en nuestro caso, la respuesta del asistente producido por un sistema de diálogo) en un formato de texto y utiliza el aprendizaje automático para crear una representación de audio.
Los componentes de NLU, gestión de diálogo y procesamiento de voz cubren el backend del asistente de voz, ¿qué pasa con la interfaz? Bueno, aquí es donde radica el mayor problema: si buscas los widgets de interfaz de voz de código abierto, es muy probable que termines sin resultados. ¡Al menos esto es lo que nos pasó y es por eso que desarrollamos nuestra propia interfaz de voz Rasa que utilizamos para este proyecto y estamos felices de compartirla con la comunidad!
Para resumir, aquí están los ingredientes del asistente de voz de código abierto:
2. El Asistente de Rasa
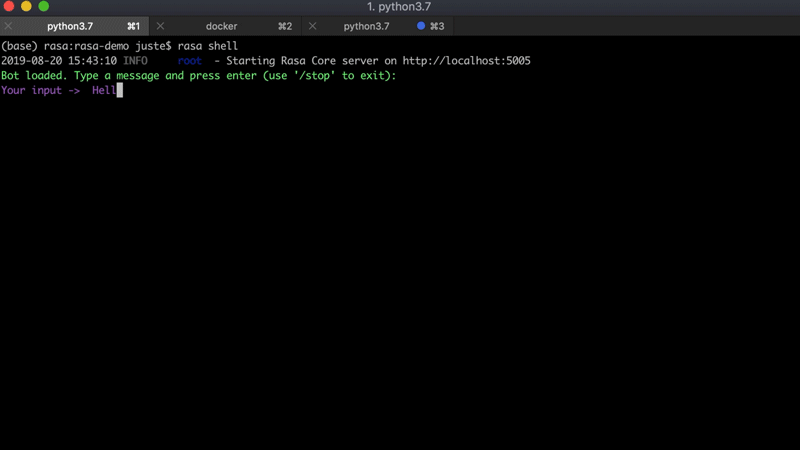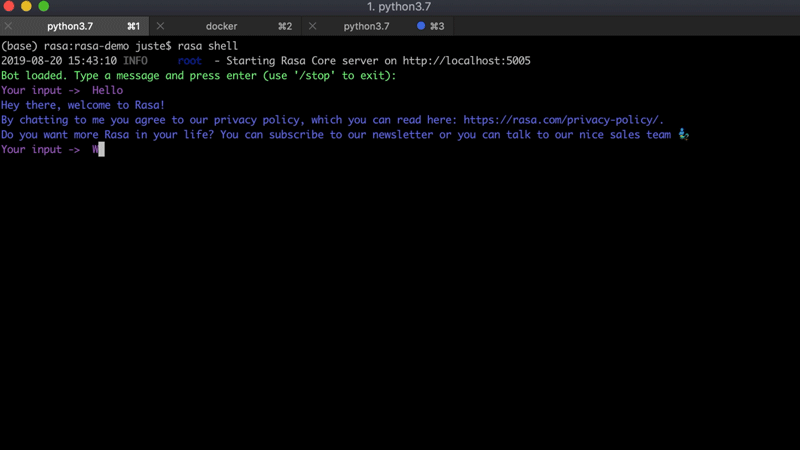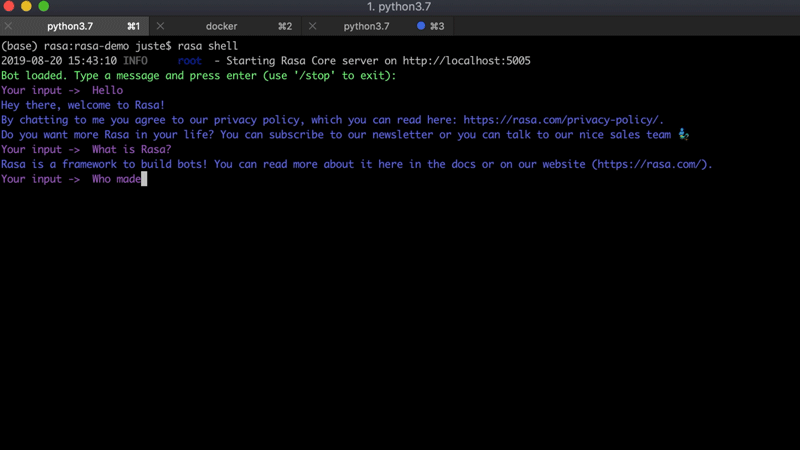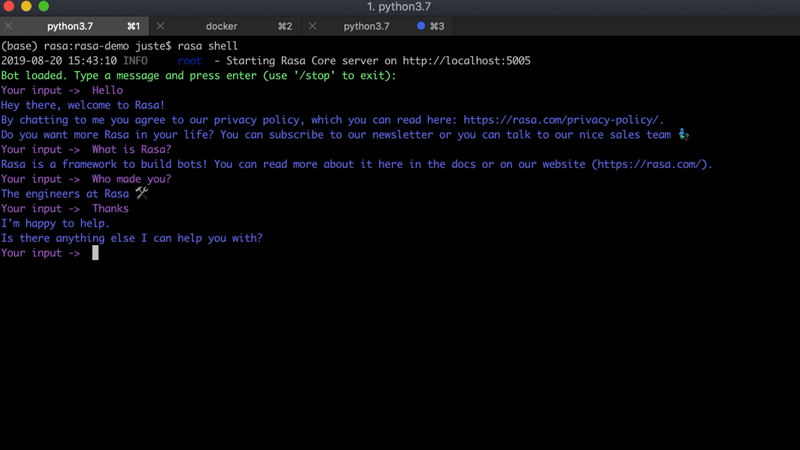
Para este proyecto, vamos a utilizar un asistente de Rasa existente: Sara . Es un asistente de código abierto impulsado por Rasa que puede responder varias preguntas sobre el marco Rasa y ayudarte a comenzar. A continuación se muestra un ejemplo de conversación con Sara:
Estos son los pasos sobre cómo configurar Sara en su entorno de desarrollo:
- Clonar el repositorio de Sara:
git clone https://github.com/RasaHQ/rasa-demo.git cd rasa-demo
2. Instala las dependencias necesarias:
pip install -e .
3. Capacitar a la NLU y los modelos de diálogo:
rasa train --augmentation 0
4. Prueba Sara en tu terminal:
docker run -p 8000:8000 rasa/duckling rasa run actions --actions demo.actions make run-cmdline
Para convertir a Sara en un asistente de voz, tendremos que editar algunos de los archivos del proyecto en las etapas posteriores de la implementación. Antes de hacer eso, implementamos los componentes TTS y STT.
3. Implementando el componente de voz a texto
Implementemos el componente de voz a texto: modelo Mozilla DeepSpeech. Echa un vistazo a esta publicación del blog de Rouben Morais para obtener más información sobre cómo funciona Mozilla DeepSpeech bajo el capó. Mozilla DeepSpeech viene con algunos modelos previamente entrenados y te permite entrenar el tuyo. En aras de la simplicidad, utilizamos un modelo previamente capacitado para este proyecto. Estos son los pasos para configurar STT en tu entorno de desarrollo:
- Clonar el repositorio de deepspeech:
pip3 install deepspeech
2. Descarga un modelo de texto a voz previamente capacitado y descomprímelo en el directorio de su proyecto:
wget https://github.com/mozilla/DeepSpeech/releases/download/v0.5.1/deepspeech-0.5.1-models.tar.gz tar xvfz deepspeech-0.5.1-models.tar.gz
3. Prueba el modelo.
La mejor manera de verificar si el componente se configuró correctamente es probar el modelo en algunas entradas de audio de muestra. El siguiente script te ayudará a hacer eso:
- La función record_audio () captura un audio de 5 segundos y lo guarda como un archivo test_audio.wav
- La función deepspeech_predict () carga un modelo de deep voice y pasa un archivo test_audio.wav para hacer una predicción sobre cómo debería verse la entrada de voz en un formato de texto
Ejecuta el script usando el comando a continuación y una vez que veas el mensaje ‘ Grabando… ‘ pronuncia una oración con la que te gustaría probar el modelo:
python deepspeech_test_prediction.py
En la siguiente parte de este post, aprenderás cómo configurar la tercera parte del proyecto: el componente de texto a voz.
4. Implementación del componente de texto a voz
Para permitir que el asistente responda con voz en lugar de texto, tenemos que configurar el componente de texto a voz que tomará la respuesta generada por Rasa y la convertirá en un sonido. Para eso, utilizamos Mozilla TTS . Al igual que Mozilla DeepSpeech, viene con modelos previamente entrenados, pero también puedes entrenar tus propios modelos utilizando datos personalizados. Esta vez también utilizaremos un modelo TTS pre-entrenado. Aquí se explica cómo configurar el componente TTS en tu entorno de desarrollo:
- Clonar el repositorio de TTS:
git clone https://github.com/mozilla/TTS.git cd TTS git checkout db7f3d3
2. Instala el paquete:
python setup.py develop
3. Descarga el modelo:
En tu directorio de Sara, crea una carpeta llamada tts_model y coloca los archivos de modelo descargados desde aquí (solo necesitas config.json y best_model.th.tar )
4. Prueba el componente:
Puedes usar el siguiente script para probar el componente de texto a voz. Esto es lo que hace el script:
- La función load_model () carga el modelo tts y prepara todo para el procesamiento
- La función tts () toma la entrada de texto y crea un archivo de audio test_tts.wav
Puedes cambiar la variable de oración con una entrada personalizada en la que te gustaría probar el modelo. Una vez que el script deja de ejecutarse, el resultado se guardará en el archivo test_tts.wav que puedes escuchar para probar el rendimiento del modelo.
import os import sys import io import torch from collections import OrderedDict from TTS.models.tacotron import Tacotron from TTS.layers import * from TTS.utils.data import * from TTS.utils.audio import AudioProcessor from TTS.utils.generic_utils import load_config from TTS.utils.text import text_to_sequence from TTS.utils.synthesis import synthesis from utils.text.symbols import symbols, phonemes from TTS.utils.visual import visualize # Set constants MODEL_PATH = './tts_model/best_model.pth.tar' CONFIG_PATH = './tts_model/config.json' OUT_FILE = 'tts_out.wav' CONFIG = load_config(CONFIG_PATH) use_cuda = False def tts(model, text, CONFIG, use_cuda, ap, OUT_FILE): waveform, alignment, spectrogram, mel_spectrogram, stop_tokens = synthesis(model, text, CONFIG, use_cuda, ap) ap.save_wav(waveform, OUT_FILE) return alignment, spectrogram, stop_tokens def load_model(MODEL_PATH, sentence, CONFIG, use_cuda, OUT_FILE): # load the model num_chars = len(phonemes) if CONFIG.use_phonemes else len(symbols) model = Tacotron(num_chars, CONFIG.embedding_size, CONFIG.audio['num_freq'], CONFIG.audio['num_mels'], CONFIG.r, attn_windowing=False) # load the audio processor # CONFIG.audio["power"] = 1.3 CONFIG.audio["preemphasis"] = 0.97 ap = AudioProcessor(**CONFIG.audio) # load model state if use_cuda: cp = torch.load(MODEL_PATH) else: cp = torch.load(MODEL_PATH, map_location=lambda storage, loc: storage) # load the model model.load_state_dict(cp['model']) if use_cuda: model.cuda() model.eval() model.eval() model.decoder.max_decoder_steps = 1000 align, spec, stop_tokens = tts(model, sentence, CONFIG, use_cuda, ap, OUT_FILE) if __name__ == '__main__': sentence = "Hello, how are you doing? My name is Sara" load_model(MODEL_PATH, sentence, CONFIG, use_cuda, OUT_FILE)
En este punto, debes tener todos los componentes más importantes ejecutándose en el entorno de desarrollo: el asistente Rasa, componentes de voz a texto y de texto a voz. Todo lo que queda por hacer es juntar todos estos componentes y conectar el asistente a la interfaz de voz Rasa. Aprende cómo puedes hacerlo en el siguiente paso de este post.
5. Poniendo todo junto
Para juntar todas las piezas y poner el asistente de voz en acción, necesitamos dos cosas:
- Interfaz de voz
- Un conector para establecer la comunicación entre la interfaz de usuario y el backend (componentes de Mozilla y Rasa)
Primero configuremos la interfaz de voz Rasa. Aquí esos dejo cómo hacerlo:
- Instala npm y node siguiendo las instrucciones proporcionadas aquí .
- Clona el repositorio de la interfaz de usuario de Rasa Voice:
git clone https://github.com/RasaHQ/rasa-voice-interface.git cd rasa-voice-interface
3. Instala el componente:
npm install
4. Pruébalo:
npm run serve
Una vez que ejecutes el comando anterior, abre un navegador y entra en https: //localhost: 8080 para verificar si la interfaz de voz se está cargando. Una pelota que salta indica que se ha cargado correctamente y está esperando la conexión.
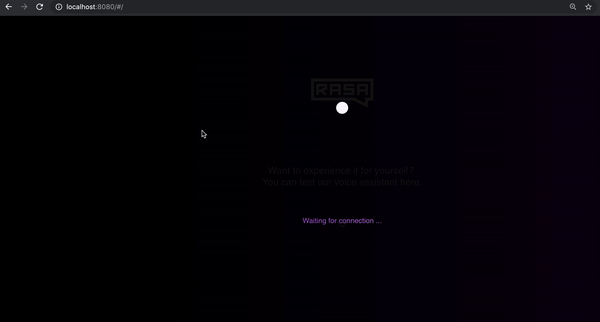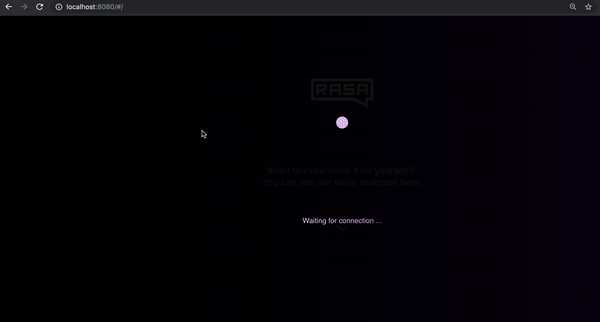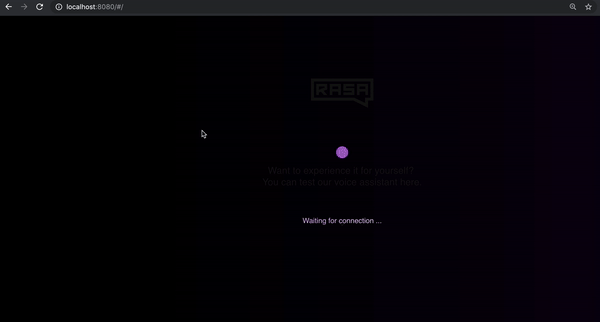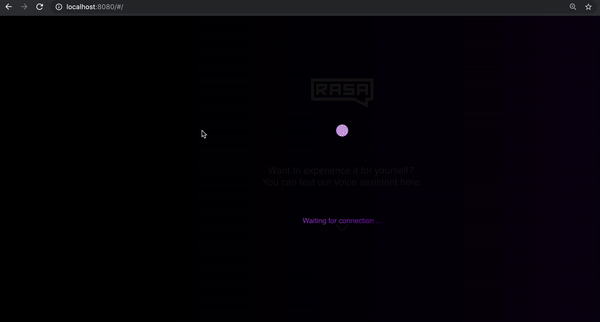
Para conectar el asistente a la interfaz, necesitas un conector. El conector también determinará qué sucede cuando el usuario dice algo y cómo la respuesta de audio se devuelve al frontend component. Para crear un conector, podemos usar un conector socketio existente y actualizarlo con algunos componentes nuevos:
- El evento de clase SocketIOInput () ‘user_utter’ se actualiza para recibir los datos de audio enviados como un enlace desde la interfaz de voz Rasa y guardarlos en el disco como un archivo .wav. Luego, cargamos el modelo STT de Mozilla para convertir el audio en representación de texto y pasarlo a Rasa:
- La clase SocketIOutput () obtiene un nuevo método _send_audio_message () que recupera una respuesta predicha por el modelo de gestión de diálogo Rasa en un formato de texto, carga el modelo Mozilla TTS que luego convierte el texto en un formato de audio y lo envía de vuelta a la interfaz.
A continuación, puede encontrar un código completo del conector actualizado:
import logging import uuid from sanic import Blueprint, response from sanic.request import Request from socketio import AsyncServer from typing import Optional, Text, Any, List, Dict, Iterable from rasa.core.channels.channel import InputChannel from rasa.core.channels.channel import UserMessage, OutputChannel import deepspeech from deepspeech import Model import scipy.io.wavfile as wav import os import sys import io import torch import time import numpy as np from collections import OrderedDict import urllib import librosa from TTS.models.tacotron import Tacotron from TTS.layers import * from TTS.utils.data import * from TTS.utils.audio import AudioProcessor from TTS.utils.generic_utils import load_config from TTS.utils.text import text_to_sequence from TTS.utils.synthesis import synthesis from utils.text.symbols import symbols, phonemes from TTS.utils.visual import visualize logger = logging.getLogger(__name__) def load_deepspeech_model(): N_FEATURES = 25 N_CONTEXT = 9 BEAM_WIDTH = 500 LM_ALPHA = 0.75 LM_BETA = 1.85 ds = Model('deepspeech-0.5.1-models/output_graph.pbmm', N_FEATURES, N_CONTEXT, 'deepspeech-0.5.1-models/alphabet.txt', BEAM_WIDTH) return ds def load_tts_model(): MODEL_PATH = './tts_model/best_model.pth.tar' CONFIG_PATH = './tts_model/config.json' CONFIG = load_config(CONFIG_PATH) use_cuda = False num_chars = len(phonemes) if CONFIG.use_phonemes else len(symbols) model = Tacotron(num_chars, CONFIG.embedding_size, CONFIG.audio['num_freq'], CONFIG.audio['num_mels'], CONFIG.r, attn_windowing=False) num_chars = len(phonemes) if CONFIG.use_phonemes else len(symbols) model = Tacotron(num_chars, CONFIG.embedding_size, CONFIG.audio['num_freq'], CONFIG.audio['num_mels'], CONFIG.r, attn_windowing=False) # load the audio processor # CONFIG.audio["power"] = 1.3 CONFIG.audio["preemphasis"] = 0.97 ap = AudioProcessor(**CONFIG.audio) # load model state if use_cuda: cp = torch.load(MODEL_PATH) else: cp = torch.load(MODEL_PATH, map_location=lambda storage, loc: storage) # load the model model.load_state_dict(cp['model']) if use_cuda: model.cuda() #model.eval() model.decoder.max_decoder_steps = 1000 return model, ap, MODEL_PATH, CONFIG, use_cuda ds = load_deepspeech_model() model, ap, MODEL_PATH, CONFIG, use_cuda = load_tts_model() class SocketBlueprint(Blueprint): def __init__(self, sio: AsyncServer, socketio_path, *args, **kwargs): self.sio = sio self.socketio_path = socketio_path super(SocketBlueprint, self).__init__(*args, **kwargs) def register(self, app, options): self.sio.attach(app, self.socketio_path) super(SocketBlueprint, self).register(app, options) class SocketIOOutput(OutputChannel): @classmethod def name(cls): return "socketio" def __init__(self, sio, sid, bot_message_evt, message): self.sio = sio self.sid = sid self.bot_message_evt = bot_message_evt self.message = message def tts(self, model, text, CONFIG, use_cuda, ap, OUT_FILE): import numpy as np waveform, alignment, spectrogram, mel_spectrogram, stop_tokens = synthesis(model, text, CONFIG, use_cuda, ap) ap.save_wav(waveform, OUT_FILE) wav_norm = waveform * (32767 / max(0.01, np.max(np.abs(waveform)))) return alignment, spectrogram, stop_tokens, wav_norm def tts_predict(self, MODEL_PATH, sentence, CONFIG, use_cuda, OUT_FILE): align, spec, stop_tokens, wav_norm = self.tts(model, sentence, CONFIG, use_cuda, ap, OUT_FILE) return wav_norm async def _send_audio_message(self, socket_id, response, **kwargs: Any): # type: (Text, Any) -> None """Sends a message to the recipient using the bot event.""" ts = time.time() OUT_FILE = str(ts)+'.wav' link = "http://localhost:8888/"+OUT_FILE wav_norm = self.tts_predict(MODEL_PATH, response['text'], CONFIG, use_cuda, OUT_FILE) await self.sio.emit(self.bot_message_evt, {'text':response['text'], "link":link}, room=socket_id) async def send_text_message(self, recipient_id: Text, message: Text, **kwargs: Any) -> None: """Send a message through this channel.""" await self._send_audio_message(self.sid, {"text": message}) class SocketIOInput(InputChannel): """A socket.io input channel.""" @classmethod def name(cls): return "socketio" @classmethod def from_credentials(cls, credentials): credentials = credentials or {} return cls(credentials.get("user_message_evt", "user_uttered"), credentials.get("bot_message_evt", "bot_uttered"), credentials.get("namespace"), credentials.get("session_persistence", False), credentials.get("socketio_path", "/socket.io"), ) def __init__(self, user_message_evt: Text = "user_uttered", bot_message_evt: Text = "bot_uttered", namespace: Optional[Text] = None, session_persistence: bool = False, socketio_path: Optional[Text] = '/socket.io' ): self.bot_message_evt = bot_message_evt self.session_persistence = session_persistence self.user_message_evt = user_message_evt self.namespace = namespace self.socketio_path = socketio_path def blueprint(self, on_new_message): sio = AsyncServer(async_mode="sanic") socketio_webhook = SocketBlueprint( sio, self.socketio_path, "socketio_webhook", __name__ ) @socketio_webhook.route("/", methods=['GET']) async def health(request): return response.json({"status": "ok"}) @sio.on('connect', namespace=self.namespace) async def connect(sid, environ): logger.debug("User {} connected to socketIO endpoint.".format(sid)) print('Connected!') @sio.on('disconnect', namespace=self.namespace) async def disconnect(sid): logger.debug("User {} disconnected from socketIO endpoint." "".format(sid)) @sio.on('session_request', namespace=self.namespace) async def session_request(sid, data): print('This is sessioin request') if data is None: data = {} if 'session_id' not in data or data['session_id'] is None: data['session_id'] = uuid.uuid4().hex await sio.emit("session_confirm", data['session_id'], room=sid) logger.debug("User {} connected to socketIO endpoint." "".format(sid)) @sio.on('user_uttered', namespace=self.namespace) async def handle_message(sid, data): output_channel = SocketIOOutput(sio, sid, self.bot_message_evt, data['message']) if data['message'] == "/get_started": message = data['message'] else: ##receive audio received_file = 'output_'+sid+'.wav' urllib.request.urlretrieve(data['message'], received_file) path = os.path.dirname(__file__) fs, audio = wav.read("output_{0}.wav".format(sid)) message = ds.stt(audio, fs) await sio.emit(self.user_message_evt, {"text":message}, room=sid) message_rasa = UserMessage(message, output_channel, sid, input_channel=self.name()) await on_new_message(message_rasa) return socketio_webhookGuarda este código en el directorio de tu proyecto como socketio_connector.py.
Lo último que debe configurarse antes de que puedas darle un giro es la configuración del conector, ya que creamos un conector personalizado, tenemos que decirle a Rasa que use este conector personalizado para recibir las entradas del usuario y enviar las respuestas. Para hacerlo, crea un archivo credentials.yml en el directorio del proyecto de Sara y proporciona los siguientes detalles (aquí socketio_connector es el nombre del módulo donde se implementa el conector personalizado, mientras que SocketIOInput es el nombre de la clase de entrada del conector personalizado):
socketio_connector.SocketIOInput: bot_message_evt: bot_uttered session_persistence: true user_message_evt: user_uttered
¡Eso es! Todo lo que queda por hacer es iniciar el asistente y tener una conversación con él. Aquí te explico cómo hacerlo:
- Inicia el servido de Rasa:
rasa run --enable-api -p 5005
2. Inicia el servidor de acciones personalizadas Rasa:
rasa run actions --actions demo.actions
3. Uno de los componentes de Sara es el componente DucklingHTTPExtractor . Para usarlo, inicia un servidor:
docker run -p 8000:8000 rasa/duckling
4. Inicia un servidor http simple para enviar los archivos de audio al cliente:
python3 -m http.server 8888
Si actualizas la interfaz de voz Rasa en tu navegador, deberías ver que el asistente está listo para hablar:
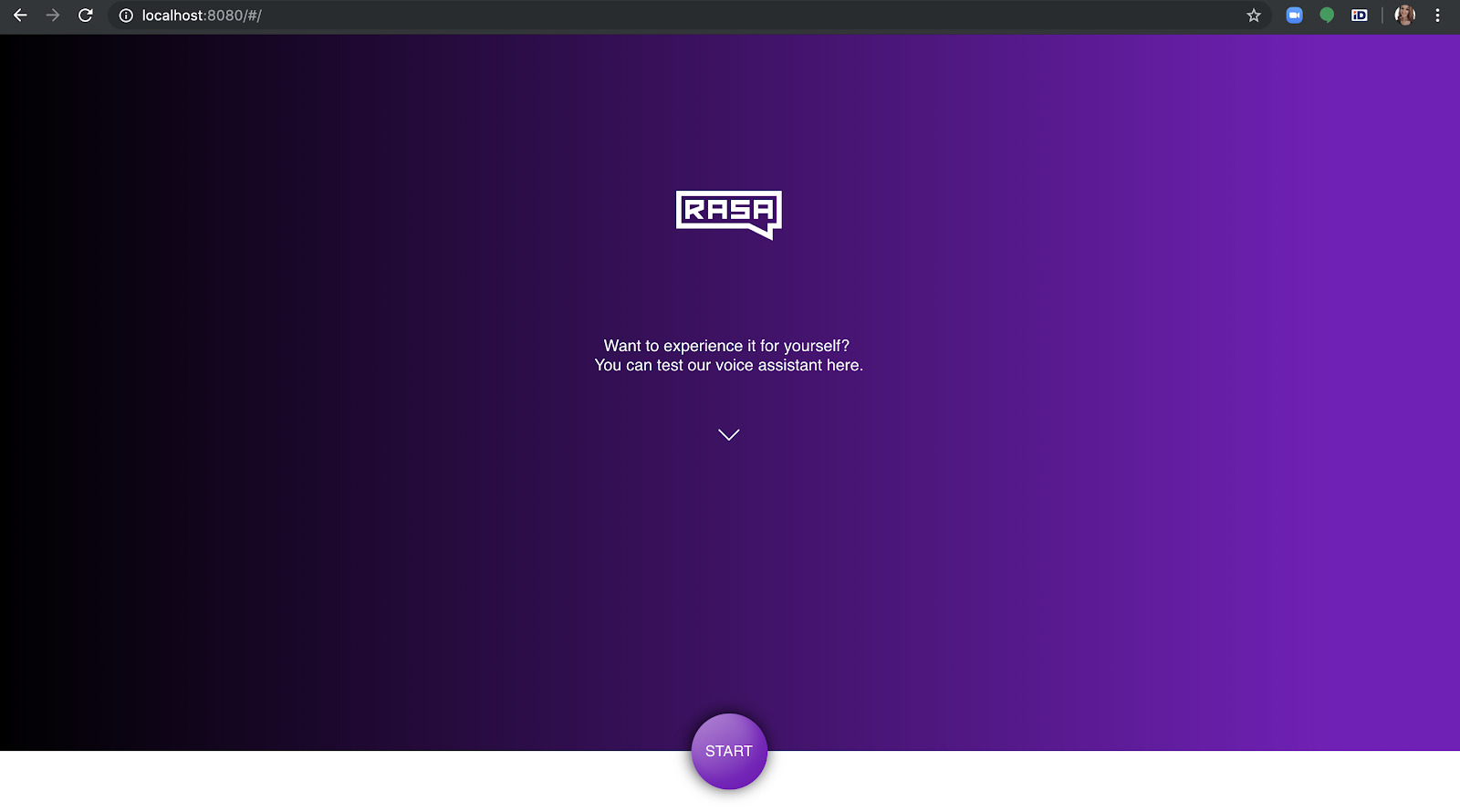
¡Haz clic en Inicio y mantén una conversación con un asistente de voz creado utilizando solo herramientas de código abierto!
6. ¿Qué sigue?
El desarrollo de asistentes de voz viene con un conjunto completamente nuevo de desafíos: ya no se trata solo de la buena NLU y el diálogo, necesita buenos componentes STT y TTS y tu NLU debe ser lo suficientemente flexible como para compensar los errores cometidos por STT. Si replicas este proyecto, notarás que el asistente no es perfecto y que hay mucho margen de mejora, especialmente en la etapa STT y NLU. ¿Cómo puedes mejorarlo? Aquí hay algunas ideas:
- Los modelos STT pre-entrenados se entrenan con datos bastante genéricos que hacen que el modelo sea propenso a errores cuando se usa en dominios más específicos. La construcción de un modelo STT personalizado con Mozilla DeepSpeech podría conducir a un mejor rendimiento de STT y NLU.
- Mejorar la NLU podría compensar algunos de los errores cometidos por STT. Una forma bastante simple de mejorar el rendimiento del modelo NLU es mejorar los datos de entrenamiento con más ejemplos para cada intento y agregar un corrector ortográfico a la pipeline Rasa NLU para corregir algunos errores STT más pequeños.
7. Resumen y recursos
En Rasa, buscamos constantemente formas de superar los límites de las herramientas y el software que permiten a los desarrolladores construir grandes cosas. Al compilar este proyecto, queríamos mostrarte que puedes usar Rasa para construir no solo texto, sino también asistentes de voz e inspirarlo para crear aplicaciones excelentes sin comprometer la seguridad y la flexibilidad de las herramientas que usa. ¿Has construido un asistente de voz con Rasa? ¿Qué herramientas usaste? Comparte tu experiencia con nosotros publicando al respecto en el foro de la comunidad Rasa.
Este proyecto es muy interesante.
Estoy intentando reproducirlo, pero quedo frenado a a cada intento y me parece que es por las versiones viejas de hace dos años.
Seria fantastico una revision al tutorial con las versiones actuales.