

Los frameworks de deep learning consisten en tensores como su unidad computacional básica. Como resultado, pueden utilizar los aceleradores de hardware (por ejemplo, GPU), acelerando así el entrenamiento y la inferencia del modelo. Sin embargo, las bibliotecas tradicionales de machine learning como scikit-learn están desarrolladas para ejecutarse en CPU y no tienen noción de tensores. Como resultado, no pueden aprovechar las GPU y, por lo tanto, perderse las posibles aceleraciones de las que disfrutan las bibliotecas de machine learning.
En este artículo, aprenderemos sobre una biblioteca llamada Hummingbird, creada para cerrar esta brecha. Hummingbird acelera la inferencia en los modelos tradicionales de machine learning convirtiéndolos en modelos basados en tensores. Esto nos permite usar modelos como los árboles de decisión de scikit-learn y el bosque aleatorio incluso en GPU y aprovechar las capacidades del hardware.
Tabla de contenidos
¿Qué es Hummingbird?
Como se mencionó anteriormente, Hummingbird es una biblioteca para acelerar la inferencia en modelos tradicionales de machine learning. Hummingbird logra esto compilando estas canalizaciones tradicionales de machine learning en cálculos de tensor. Esto significa que puede aprovechar la aceleración de hardware como GPU y TPU, incluso para modelos tradicionales de machine learning, sin rediseñar los modelos.
Esto es beneficioso en varios aspectos. Con la ayuda de Hummingbird, los usuarios pueden beneficiarse de:
- las optimizaciones implementadas en marcos de redes neuronales;
- aceleración de hardware nativo;
- tener una plataforma única para admitir modelos de redes tradicionales y neuronales;
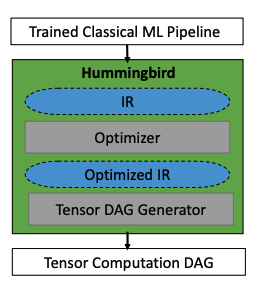
Arquitectura de alto nivel de la biblioteca Hummingbird | Fuente: documento oficial
Además de las ventajas anteriores, Hummingbird también ofrece muchas funciones convenientes, algunas de las cuales se enumeran a continuación.
1️⃣. API de “inferencia” uniforme y conveniente
Hummingbird proporciona una API de “inferencia” uniforme y conveniente que imita de cerca la API de sklearn. Esto permite intercambiar modelos sklearn con modelos generados por Hummingbird sin tener que cambiar el código de inferencia.
2️⃣. Soporte para los principales modelos y características.
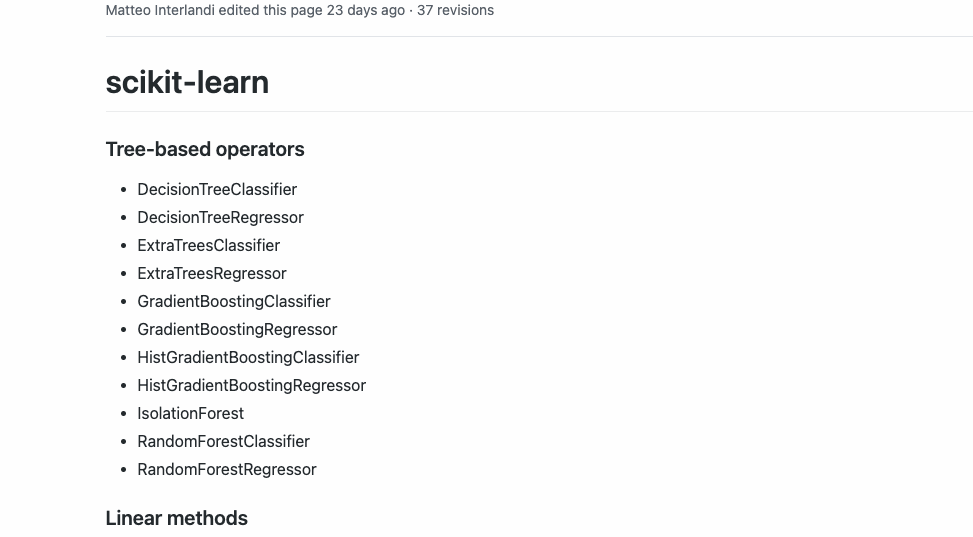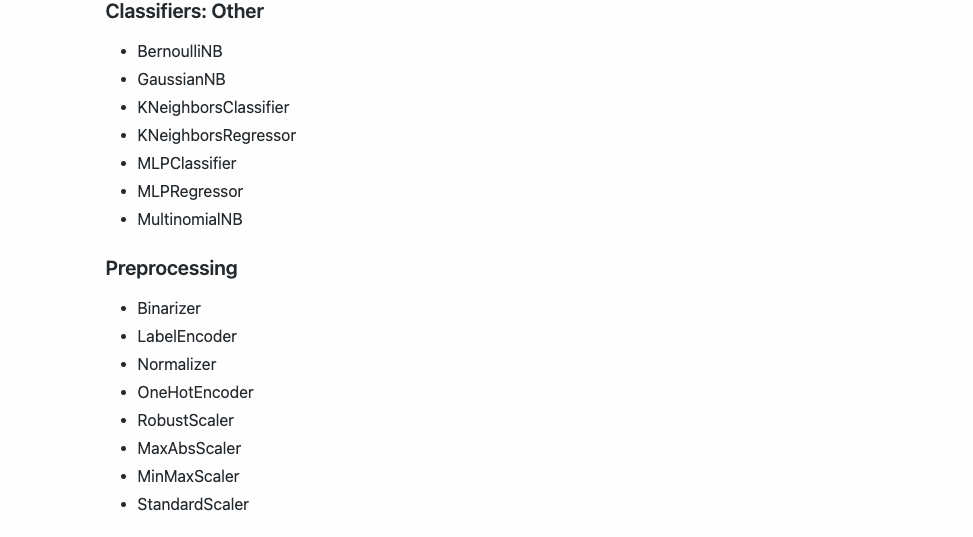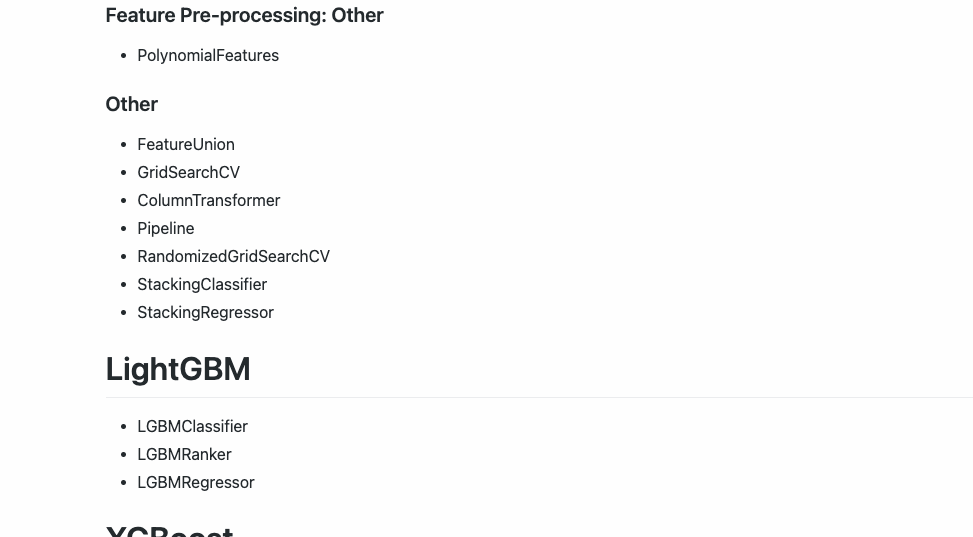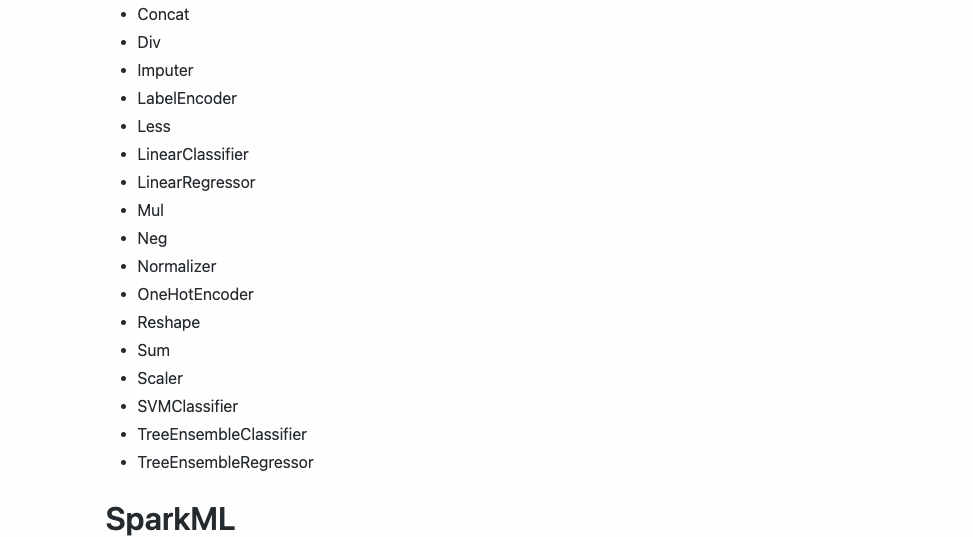
Esta versión actual de Hummingbird actualmente admite los siguientes operadores:
3️⃣. Capacidades de conversión
Actualmente, puedes usar Hummingbird para convertir tus modelos ML tradicionales entrenados en PyTorch, TorchScript, ONNX y TVM)

Hummingbird puede convertir tu machine learning tradicional entrenado | Imagen del autor
Trabajando
El objetivo principal de la biblioteca Hummingbird es acelerar la inferencia de los modelos tradicionales de machine learning. Se han desarrollado muchos sistemas especializados, como ONNX Runtime, TensorRT y TVM. Sin embargo, muchos de estos sistemas se centran en el Deep Learning. El problema con los modelos tradicionales es que se expresan utilizando código imperativo de una manera ad hoc. Entendamos esto a través de alguna representación visual.
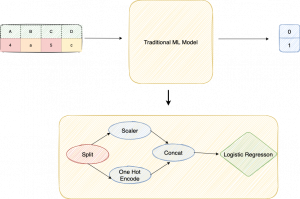
Cómo funcionan los modelos tradicionales de machine learning | Imagen del autor | Reproducido de la sesión Hummingbird.
Los modelos tradicionales se expresan usando código imperativo de una manera ad hoc
Pensemos en un marco de datos que contiene cuatro columnas, de las cuales dos son categóricas y el resto dos numéricas. Estos se introducen en un modelo de machine learning, digamos regresión logística, para identificar si pertenecen a la clase 0 o la clase 1. Este es un caso clásico de un problema de clasificación binaria. Si miramos bajo el capó, tenemos un DAG o gráfico acíclico dirigido de operadores llamado pipeline. La canalización consta de características que preprocesan los datos y luego los introducen en un predictor, que generará la predicción.
Esta es solo una representación simple de cómo se vería un modelo tradicional. En todos los marcos tradicionales de machine learning, hay cientos y cientos de estas características y predictores. Como resultado, resulta difícil representarlos de una manera que tenga sentido en todos los marcos diferentes.
Los modelos de Deep Learning se expresan como DAG of Tensor Operations
Por otro lado, confiamos principalmente en la abstracción de los tensores en el Deep Learning que es solo una matriz multidimensional. Los modelos de Deep Learning también se expresan como un DAG, pero se centran explícitamente en los operadores de tensores. En el siguiente diagrama, tenemos operaciones matriciales muy genéricas que se pueden representar fácilmente en una amplia variedad de sistemas.
 Cómo funcionan los modelos de Deep Learning | Imagen del autor | Reproducido de la sesión Hummingbird.
Cómo funcionan los modelos de Deep Learning | Imagen del autor | Reproducido de la sesión Hummingbird.
Los sistemas de servicio de predicción de Deep Learning pueden capitalizar estas operaciones de tensores y explotar esta abstracción para trabajar en muchos entornos de destino diferentes.
Hummingbird convierte las tuberías tradicionales en operaciones tensoriales mediante la reconfiguración de operadores algorítmicos. El siguiente ejemplo de su blog oficial explica una de las estrategias de Hummingbird para traducir un árbol de decisiones en tensores que involucran GEMM (Multiplicación de matrices genéricas).
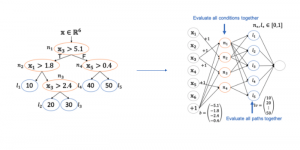
Transformar un árbol de decisiones simple en redes neuronales | Reproducido del blog oficial de Hummingbird
Demo
La sintaxis de Hummingbird es muy intuitiva y mínima. Para ejecutar tu modelo ML tradicional en marcos DNN, solo necesita importar hummingbird.ml y agregar convert (model, ‘dnn_framework’) a tu código. A continuación se muestra un ejemplo que utiliza un modelo de bosque aleatorio de scikit-learn y PyTorch como marco de destino.
Enlace para acceder a todo el código y el conjunto de datos
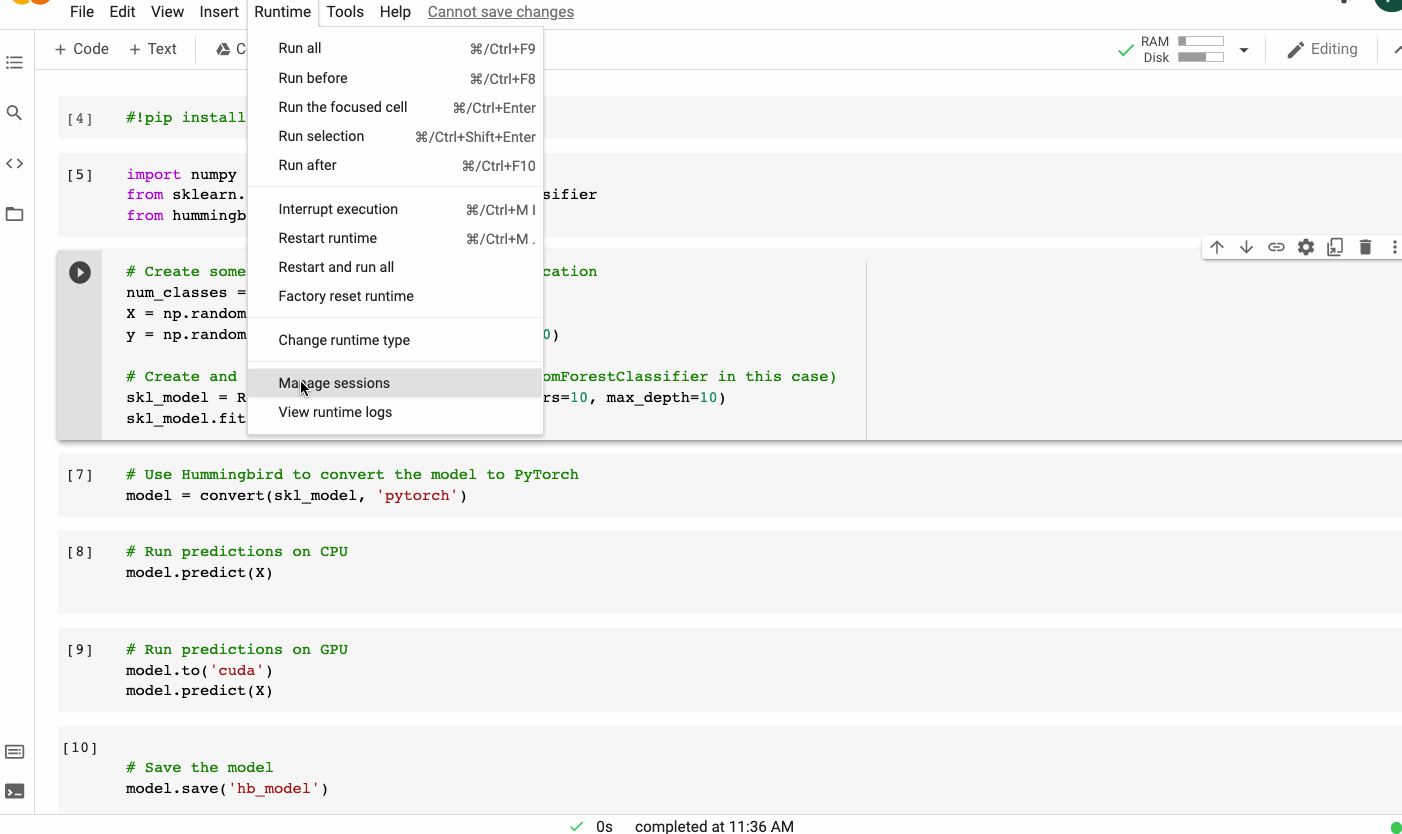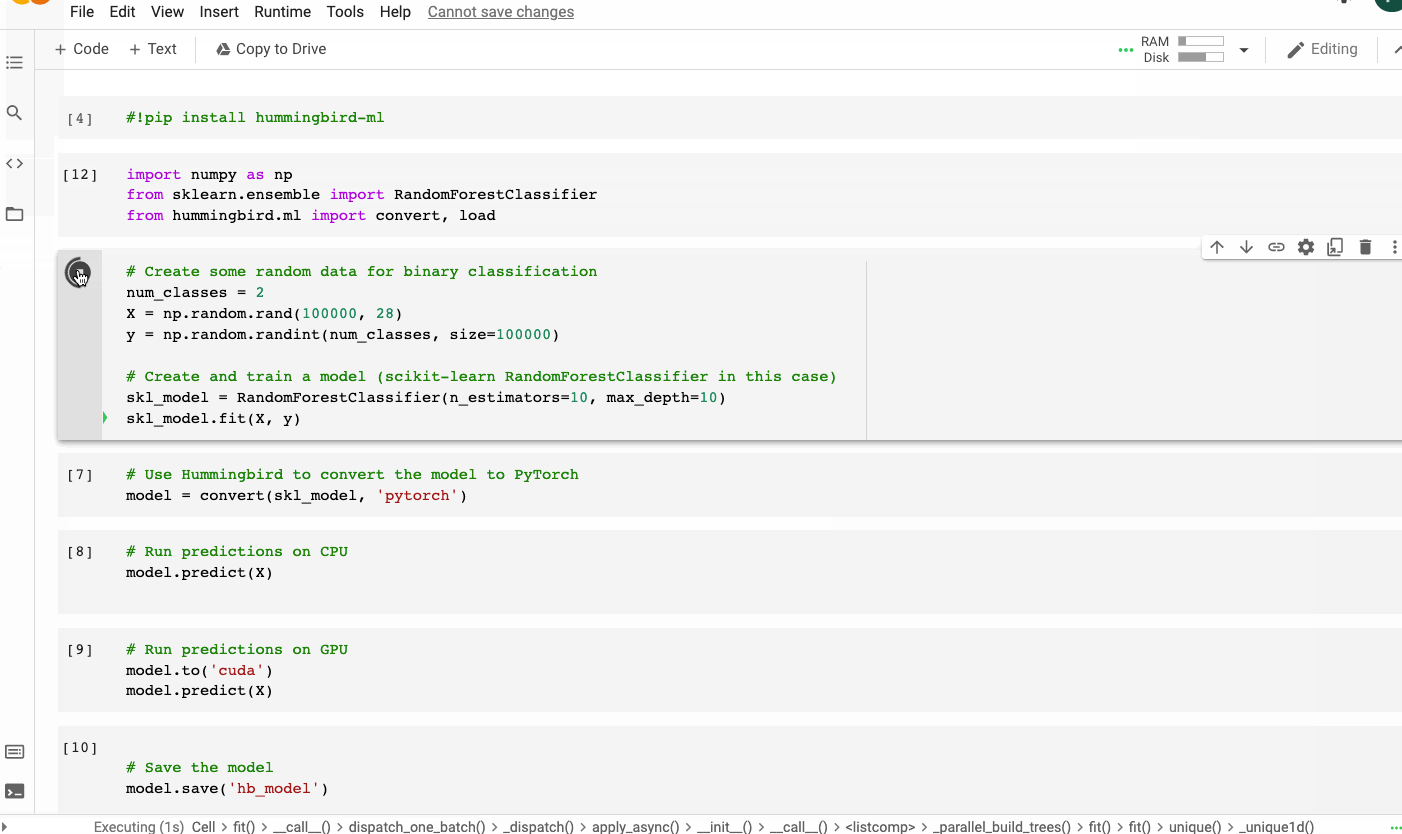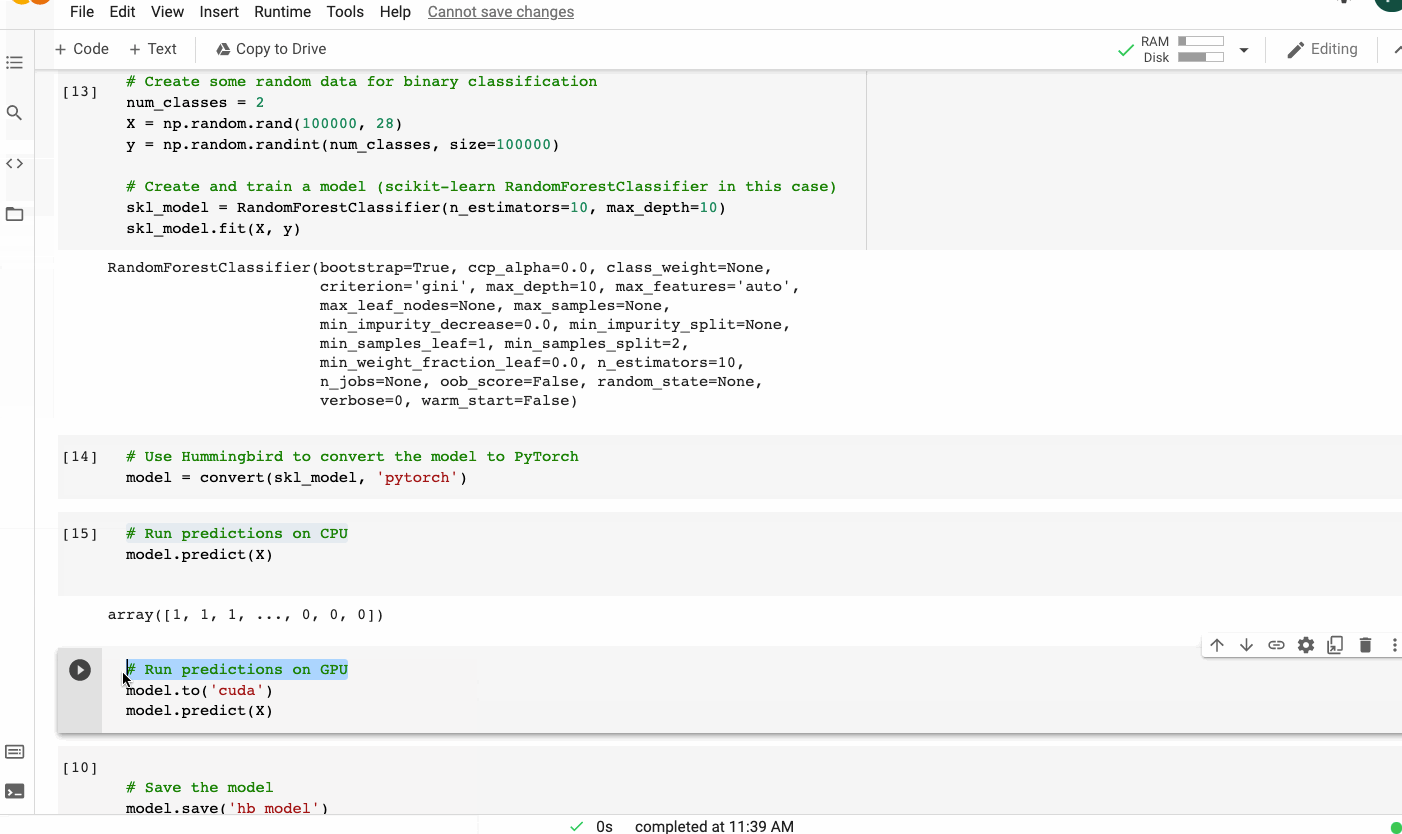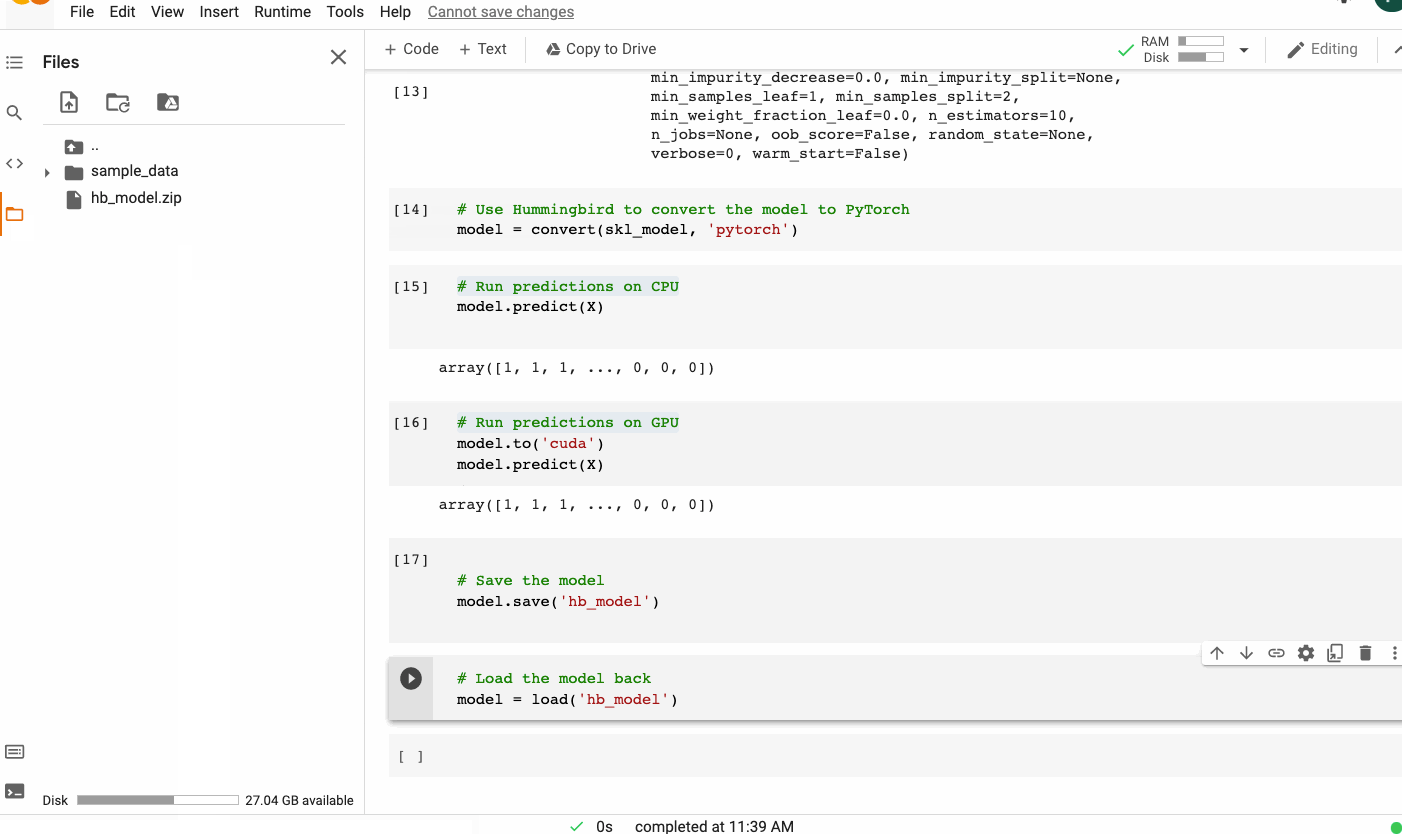
Usando un modelo de bosque aleatorio scikit-learn y PyTorch como marco de destino usando Hummingbird | Imagen del autor
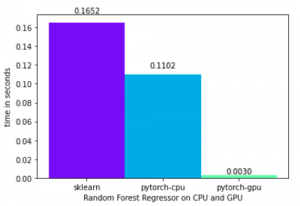
Comparación en tiempos de un regresor de bosque aleatorio en CPU vs. GPU | Imagen del autor | Enlace al código
Conclusión
Hummingbird es una biblioteca prometedora y trabaja en un problema central en el espacio de machine learning. Dar la capacidad a los usuarios de realizar una transición fluida de la CPU a la GPU y aprovechar el acelerador de hardware para acelerar la inferencia ayudará a enfocarse directamente en los problemas en lugar del código. Si deseas ir más allá, asegúrate de consultar los recursos a continuación. Este artículo se basa en estas referencias y también las encontrará útiles si decide profundizar en las explicaciones subyacentes de la biblioteca.
Referencias
- https://github.com/microsoft/hummingbird
- Tensors Are All You Need: Faster Inference with Hummingbird
- A Tensor Compiler for Unified Machine Learning Prediction Serving.
- Compiling Classical ML Pipelines into Tensor Computations for One-size-fits-all Prediction Serving.