

Lo que estoy a punto de mostrarte no tiene precedentes y parece casi magia… Google Research, en colaboración con la Universidad de Cornell, ha anunciado RealFill, un modelo de inpainting y outpainting de imágenes con resultados impactantes.
El modelo toma como referencia un conjunto de imágenes y permite rellenar las partes que faltan de una imagen de destino basándose en las primeras.
Pero, ¿qué significa eso?
El modelo es capaz de utilizar las referencias de un puñado de imágenes para rellenar (inpaint) o ampliar (outpaint, el caso que sigue) respetando la referencia.

Es capaz de hacerlo aunque las referencias estén en otros ángulos de cámara o iluminación, ya que el modelo extrae las características clave de esas imágenes y las aplica con éxito a las nuevas generaciones.
De este modo, no tienes que imaginar cómo debería haber sido la imagen perfecta pero recortada. Ahora, basta con pedirla.
Pero profundicemos en cómo han creado realmente este modelo mágico.
Tabla de contenidos
El Miguel Ángel del siglo XXI
Como la mayoría de los modelos actuales de IA generativa, RealLife es un modelo de difusión.
Los modelos de difusión son sistemas de IA que aprenden a transformar una imagen en una distribución de datos Gaussian (aleatoria) en una imagen objetivo.
En otras palabras, toman una imagen «con ruido», predicen el ruido que tiene y lo eliminan, descubriendo la nueva imagen.

La imagen de arriba muestra el proceso de entrenamiento. A partir de una imagen real (izquierda), se añade ruido (valores aleatorios de los píxeles) a la imagen, obteniendo la imagen de la derecha.
Al mismo tiempo, el modelo toma una condición que describe la imagen original, como «un gato tumbado».
A continuación, el modelo tiene que predecir el ruido, eliminarlo y reconstruir la imagen inicial utilizando el texto como «pista».
Por consiguiente, al generar nuevas imágenes, el modelo puede partir con éxito de un «lienzo» con ruido arbitrario y una condición de texto como «dibújame un gato» y obtener una nueva imagen que coincida con la original.
Si tienes problemas para comprender lo que esto significa, piensa en esta cita de uno de los seres humanos con más talento que ha pisado la Tierra, el renacentista Miguel Ángel:
«La escultura ya está completa dentro del bloque de mármol. Sólo tengo que cincelar el material superfluo».
En cierto modo, el modelo hace exactamente lo mismo.
A partir de un montón de píxeles colocados arbitrariamente, el modelo es capaz de «cincelar» el ruido y descubrir la imagen deseada:

Sin embargo, no todo iban a ser campanas y silbatos.
Para evitar generar siempre la misma imagen, el proceso de difusión parte siempre de ruido aleatorio, por lo que la petición «un retrato de un hombre» le dará resultados ligeramente distintos cada vez.
De hecho, esto se hace a propósito, para que las imágenes cambien cada vez. Pero aquí, el diablo está en los detalles.
¿Y si también queremos generar imágenes coherentes y fieles a una referencia determinada?
Por ejemplo, ¿qué pasa si quiero ampliar la imagen del retrato (derecha) pero asegurarme de que la parte de la imagen recién generada respeta el atuendo original (izquierda)?

Et voilà.
Por si te lo estás preguntando, este NO soy yo.
Los modelos de difusión estándar siempre dan resultados aleatorios, por lo que la ampliación nunca coincidirá del todo con el original.
Con RealFill, eso ya no es un problema.
Se trata de centrarse en QUÉ aprender
No importa el caso de uso, o si se trata de texto, imagen o sonido.
Las redes neuronales, en esencia, aprenden todas de la misma manera: utilizando el descenso gradiente para optimizar contra una función de pérdida dada.
Si pensamos en ChatGPT, se trata de minimizar las posibilidades de no adivinar la palabra correcta en una frase. Para Stable Diffusion, minimizar las posibilidades de no reconstruir correctamente la imagen inicial.
Por tanto, se trata de averiguar cómo medir esa «diferencia» y simplemente ajustar las neuronas de la red para que la diferencia en el resultado sea progresivamente menor.
Las redes neuronales son aproximadores universales de funciones.
Para una tarea determinada, aprenden el conjunto de neuronas y activaciones que le permiten aprender la función que modela esa tarea, es decir, predecir la siguiente palabra (ChatGPT) o generar nuevas partes de una imagen (RealFill).
Sea cual sea el caso de uso, en esencia, el procedimiento es siempre el mismo.
En el caso de RealFill, tenemos que hacer dos cosas:
- Enseñar al modelo a reconstruir una imagen inicial siguiendo el proceso de difusión descrito anteriormente.
- Enseñar al modelo a reconstruir sólo determinadas partes de una imagen, es decir, enseñarle a pintar o a despintar una imagen.
Por suerte, ya tenemos la primera, ya que podemos tomar simplemente un modelo de código abierto como Stable Diffusion.
Pero para la segunda tarea, necesitamos afinar Stable Diffusion siguiendo el siguiente gráfico:

- Alimentamos el modelo con varias imágenes de referencia, muestreando una imagen cada vez y aplicándole ruido aleatorio (lo que ellos llaman «imagen de entrada»).
- También introducimos una condición de texto, ya que queremos poder determinar lo que el modelo generará en el área asignada.
- Como queremos que sea leal a una referencia dada, también alimentamos el modelo con la imagen de entrada con un patrón de parches aleatorios sobre ella.
- Ahora, el objetivo es reconstruir las partes visibles de la parcheada.
Pero la intuición clave aquí es, ¿por qué estamos parcheando la imagen?
Para tener éxito en una tarea estándar de reconstrucción de imágenes, el modelo no necesita realmente entender que la característica más destacada de esta imagen es una chica, ya que básicamente tratará toda la imagen como un montón de píxeles estructurados de una manera determinada.
Por tanto, durante el entrenamiento, el modelo se centra en la imagen global.
Pero puede que pienses: «No estoy de acuerdo, ya que modelos como Stable Diffusion generarán lo que yo les pida, ya sea una chica o un gorila, lo que significa que el modelo entiende lo que está generando».
Y en cierto modo es cierto, pero esto sólo funcionará si el modelo parte de un «lienzo sin ruido» completo sobre el que trabajar.
Si le das el 80% de la imagen y le dices que rellene el 20% que falta, eso requiere localidad, y en esas tareas, los generadores de imágenes estándar fracasan estrepitosamente:

Por tanto, si forzamos al modelo a reconstruir sólo imágenes parcheadas (parcialmente visibles), le estamos obligando a prestar atención localmente.
La reconstrucción de imágenes parcheadas es la base de los autocodificadores o del modelo mundial I-JEPA de Meta, soluciones que obligan a los modelos a prestar atención tanto global como localmente para aprender características más complejas.
Por ejemplo, si parcheamos la mitad de la cara de la chica, el objetivo del modelo ya no es generar una chica bailando, sino reconstruir la mitad de la cara de una chica que resulta que también está bailando.
¿Y a la hora de inferir?
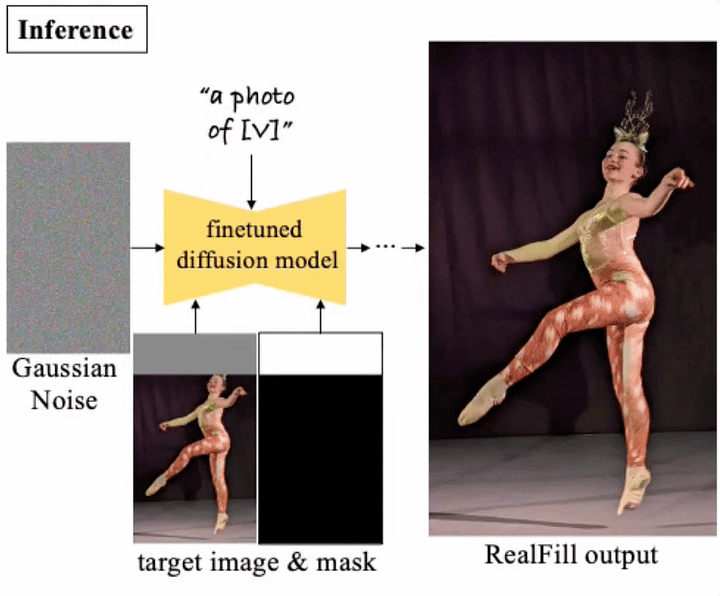
La inferencia es como en cualquier modelo de difusión, pero añadiendo una máscara para que el modelo genere sólo la parte de la imagen que falta.
En conclusión, la reconstrucción parcial implica una comprensión más compleja de lo que tiene que generar y de cómo mantenerse fiel a una referencia dada.
Funciones mágicas pero prácticas
Lo mejor de RealFill es que lo más probable es que ya sea un producto real y disponible.
Viendo que el documento se publicó casi al mismo tiempo que Google anunciaba las nuevas funciones de edición de imágenes de su smartphone Pixel 8, está bastante claro que esto se basa en RealFill.
Pero RealFill también tiene sus inconvenientes.
Como explica este artículo de la BBC, será muy difícil diferenciar la realidad de las generaciones falsas, desatando una polémica en torno a «¿cuánta IA es demasiada IA?».
Mientras tanto, herramientas como RealFill permitirán a los humanos dar forma a sus experiencias y recuerdos de nuevas maneras que los hagan más memorables.
Por otro lado, cabe preguntarse… ¿se puede confiar en algo a estas alturas?
Magnífico ¡¡¡¡¡