

Tabla de contenidos
Los grandes modelos lingüísticos son la próxima generación de sistemas operativos
“No creo que sea acertado pensar en los Large Language Models como chatbots o una especie de generadores de palabras” afirma Andrej Karpathy, uno de los miembros fundadores de OpenAI. “Es mucho más correcto pensar en [ellos] como el proceso del núcleo de un Sistema Operativo emergente“.
Espera, pero ¿qué demonios significa eso?
Los grandes modelos lingüísticos (LLM) se convertirán gradualmente en la interfaz entre ti y los sistemas informáticos.
Ahora mismo, tienes en tus manos un dispositivo con cierta potencia de cálculo, pero no puedes acceder directamente a ella. Tu interacción está mediada por un sistema operativo (como Windows, Mac OS y Android), que transforma una colección de chips y circuitos en una interfaz fácil de usar.
Tu Sistema Operativo (SO) te permite realizar una amplia gama de actividades (como leer el artículo de un tipo calvo) a través de una variedad de aplicaciones que se ejecutan sobre él. Cada aplicación tiene su propia interfaz de usuario y su propio conjunto de tareas. Saltas de una aplicación a otra, de una interfaz a otra, dependiendo de lo que necesites hacer.
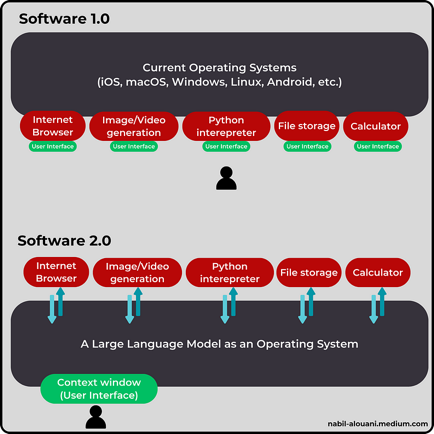
El día de mañana, dispondrás de una única interfaz de usuario para hacer de todo, desde redactar un informe comercial anual hasta crear una nueva aplicación desde cero. Dicha interfaz será un chatbox o una “ventana contextual” dentro de la cual podrás enviar instrucciones en lenguaje natural, y ahí es donde entra en juego la ingeniería de instrucciones.
Prompt Engineering es una forma elegante de decir “Escribe instrucciones cada vez mejores para tu modelo de IA hasta que haga exactamente lo que quieres“. Pero no se trata de un simple juego de palabras, sino del proyecto para el futuro de la programación.
La programación como mercancía (barata)
“La programación se refiere a un proceso tecnológico para decirle a una computadora qué tareas debe realizar para resolver problemas” escribió Coursera en su sitio web. “Puedes pensar en la programación como una colaboración entre humanos y ordenadores, en la que los humanos crean instrucciones para que un ordenador las siga (código) en un lenguaje que los ordenadores puedan entender“.
En otras palabras, la programación convierte la potencia de cálculo en una mercancía: un recurso que puedes utilizar para lograr tus objetivos. Prompt Engineering es una herramienta que convierte la programación en una mercancía. Tú envías una instrucción a un LLM y éste escribe el código por ti.
Digamos que quieres analizar un pequeño conjunto de datos para un proyecto. Normalmente, empezarías por reunir cientos de archivos CSV dispersos por la nube de tu empresa. A continuación, haces doble clic en Jupyter Notebook y escribes unas pocas líneas de Python para compilar tus entradas en un único marco de datos.
A partir de ahí, espolvoreas un poco de magia de ciencia de datos, ejecutas una docena de iteraciones y enhorabuena: tienes una colección de tablas elegantes, gráficos extravagantes y predicciones basadas en datos. El último paso es comprimir las seis semanas de trabajo en 42 hermosas diapositivas que se muestran en otra aplicación llamada Microsoft PowerPoint.
Acabas de combinar aplicaciones estándar con código escrito por ti mismo para crear un programa que ejecuta un análisis de datos específico. Pero, ¿y si, en lugar de eso, todo lo que tuvieras que hacer fuera escribir unas cuantas instrucciones en inglés sencillo?
“Hola, amigo de la IA” dirías. “Aquí tienes un conjunto de datos desordenados sobre las entregas que nuestra empresa ha hecho en París en los últimos cinco años. Por favor, limpia el desorden y ejecuta un algoritmo de agrupación. Muestra un mapa de calor y haz zoom en los puntos de alta densidad. Añade una proyección a dos años y utiliza los resultados para optimizar el itinerario diario de nuestra flota de reparto. Cuando acabes con las matemáticas, genera un informe con gráficos claros y comentarios sucintos. ¡Y tómate tu tiempo! Estaré fuera al menos seis horas“.
Cada vez que escribes un mensaje de este tipo, estás programando una aplicación que resuelve un problema concreto.
Es casi como lo describe Coursera: colaboras con un ordenador para lograr un objetivo. La única diferencia es que, en lugar de código, utilizarás un lenguaje sencillo. De acuerdo, el mensaje puede estar a unos metros de la línea de meta, pero en principio, así es como serán tus interacciones con los futuros LLM.
Para una ilustración más concreta, considera la famosa demostración de abajo, donde GPT-4 convirtió un boceto dibujado a mano en código HTML funcional.
Todo lo que necesitas son prompts
Pasará un tiempo antes de que podamos sustituir a los data scientist, los desarrolladores web y los ingenieros de software por un montón de mensajes inteligentes. Mientras tanto, los aumentaremos con asistentes de IA que hagan su trabajo más eficiente, y cada uno de estos asistentes de IA estará programado en inglés sencillo.
En lugar de utilizar un paquete de aplicaciones complementarias como Google Workspace, Jupyter Notebook y Microsoft PowerPoint, crearemos un asistente llamado “StatSniffer: tu experto personal en Data Science”.

Al igual que el actual ChatGPT PLUS, tu StatSniffer personalizado será un LLM conectado a una serie de herramientas que le proporcionan capacidades adicionales como la exploración de archivos, la ejecución de código y la generación de gráficos. También se podrá aumentar las capacidades de StatSniffer con metodologías de alto rendimiento, dándole acceso a trabajos de investigación, estudios de casos y libros de texto académicos.
OpenAI ya está experimentando con asistentes de IA personalizados a través de la GPT Store, donde se pueden crear asistentes llamados GPT. Sin embargo, los GPT actuales son toscos. Por ejemplo, son vulnerables a simples jailbreaks que les hacen revelar sus “instrucciones centrales”. Los GPT también tienden a volver a su modo por defecto (GPT-4) tras unos pocos intercambios con los usuarios.
Esto no es una sorpresa porque la tecnología aún está en pañales. A medida que avance la investigación en IA y mejoren los modelos de código abierto, el ecosistema de asistentes de IA evolucionará para abarcar más capacidades con mayor fiabilidad. Hablando de eso, queda mucho camino por recorrer.
Problemas como la planificación y el razonamiento en varios pasos siguen sin resolverse, en parte porque los LLM aún van por detrás de los humanos (e incluso de los gatos) en lo que se refiere a la comprensión de la realidad física.
Esto no significa que la gente vaya a aguantar la respiración para que asistentes totalmente autónomos versados en Gravedad Cuántica aprovechen los modelos de IA existentes. Incluso los llamados LLM “tontos” pueden multiplicar por dos su eficiencia. He aquí un extracto de un estudio de McKinsey sobre cómo los desarrolladores utilizan los LLM para acelerar su trabajo.
“Nuestra investigación empírica más reciente revela que las herramientas basadas en IA generativa ofrecen impresionantes ganancias de velocidad en muchas tareas habituales de los desarrolladores. La documentación de la funcionalidad del código para su mantenimiento (que tiene en cuenta la facilidad con la que se puede mejorar el código) se puede completar en la mitad de tiempo, la escritura de código nuevo en casi la mitad de tiempo y la optimización del código existente (denominada refactorización del código) en casi dos tercios de tiempo.“
“Para que los desarrolladores utilicen eficazmente la tecnología como complemento de su trabajo diario, es probable que necesiten una combinación de formación y entrenamiento”, explica el equipo de investigación de McKinsey. “La formación inicial debe incluir las mejores prácticas y ejercicios prácticos para introducir indicaciones en lenguaje natural en las herramientas, lo que suele denominarse ingeniería de indicaciones“.
Y esto no sólo es cierto para las tareas relacionadas con el software. El mismo patrón se extiende también a una gama más amplia de actividades corporativas. Por ejemplo, investigadores de la Harvard Business School (HBS) realizaron un estudio para evaluar el impacto de equipar a los empleados del Boston Consulting Group (BCG) con herramientas de IA Generativa.
“Para cada una de las 18 tareas de consultoría realistas dentro de la frontera de las capacidades de la IA, los consultores que la utilizaron fueron significativamente más productivos (completaron un 12,2% más de tareas de media y un 25,1% más rápido) y produjeron resultados de una calidad significativamente mayor (más de un 40% más de calidad en comparación con un grupo de control)” escribieron los investigadores de la HBS.
Estos estudios alimentan el nuevo tópico de “la IA no te sustituirá, pero alguien que la utilice sí“. Quizá una formulación más elegante podría ser: “La IA no te sustituirá, pero sí lo hará un Ingeniero Prompt“.
Cuanto mayor sea la “frontera de la IA” (es decir, las tareas que los modelos de IA pueden realizar con gran precisión), más problemas podremos resolver utilizando prompts. Esto nos lleva a una falacia muy extendida que sugiere que los modelos de IA más capaces requieren menos habilidades de ingeniería de avisos.
“¿Ha muerto la ingeniería rápida?” No, es tecnología punta
Una forma de ver la relación entre un Modelo de Lenguaje Extenso y la Ingeniería de Preguntas es imaginar el primero como un multiverso y el segundo como un puntero, sí, como un puntero láser.
Cuando se formula una pregunta a un LLM, éste considera un multiverso de documentos relevantes. Dentro de cada documento, hay un grupo de posibles respuestas, y cada posible respuesta es una cadena de probabilidades.
Su pregunta apunta hacia el universo que tiene más probabilidades de contener la respuesta deseada y, a partir de ahí, su modelo intenta navegar hacia esa respuesta deseada, palabra por palabra.
Cada vez que el modelo predice una ficha, elimina cientos de caminos alternativos y sigue reduciendo sus opciones hasta que todo lo que queda es una serie de palabras que constituyen “el destino”.

Sin embargo, este destino nunca es el mismo. Aunque utilice exactamente la misma pregunta, casi nunca llegará a la misma dirección. En cambio, aterrizarás en algún lugar del “vecindario” de las respuestas más relevantes.
François Chollet, ingeniero de software e investigador de Inteligencia Artificial que trabaja en Google, ofrece una descripción más técnica:
“Si un LLM es como una base de datos de millones de programas vectoriales, una pregunta es como una consulta de búsqueda en esa base de datos […] esta “base de datos de programas” es continua e interpolativa, no es un conjunto discreto de programas.
Esto significa que una pregunta ligeramente diferente, como “Reformule líricamente este texto al estilo de x”, seguiría apuntando a una ubicación muy similar en el espacio de programas, lo que daría como resultado un programa que se comportaría de forma bastante parecida, pero no idéntica. […]
La ingeniería de instrucciones es el proceso de búsqueda a través del espacio de programas para encontrar el programa que empíricamente parece funcionar mejor en la tarea objetivo.”
Como señaló Chollet, el objetivo de tu prompt es llamar al programa adecuado para la tarea que quieres realizar. La trampa de razonamiento en la que cae mucha gente es creer que los futuros LLM deberían ser capaces de predecir qué programa queremos que ejecuten, incluso cuando les damos asignaciones vagas.
Pero, al igual que ocurre con los humanos, aunque contrates a la ingeniera más capaz técnicamente, no podrá leerte la mente. Tienes que explicarle exactamente lo que quieres; de lo contrario, estás perdiendo tiempo y energía.
Supongamos que has encargado a tu formidable ingeniero que construya un producto, pero no te gusta el resultado. Puede cambiar de ingeniero o cambiar sus instrucciones. Como sabe que su ingeniero está altamente cualificado, el sentido común le sugiere que opte por la segunda opción.
Del mismo modo, si su modelo lingüístico altamente capacitado no produce la respuesta que usted desea, no lo desecha. No se sienta a esperar que el próximo modelo sea capaz de leerle la mente. Lo más razonable y rentable es mejorar su prontitud.
Eso es lo que hizo un equipo de investigación de Microsoft con GPT-4. En lugar de perfeccionar el modelo para un caso de uso específico, utilizaron técnicas de ingeniería rápida para mejorar su rendimiento.
La puntuación de GPT-4 mejoró hasta un 9% en nueve parámetros médicos diferentes. Como resultado, la precisión del modelo superó el 90%, superando a los modelos ajustados específicamente para aplicaciones médicas.
Tenga en cuenta que el ajuste requiere recursos adicionales, como la contratación de expertos para producir datos de entrenamiento de alta calidad y algunos recursos informáticos para volver a entrenar el modelo. Por supuesto, el ajuste fino requiere una fracción de la potencia informática en comparación con el preentrenamiento, pero sigue siendo un coste adicional.
Además, hay que invertir los mismos recursos cada vez que se quiere ajustar el modelo a un nuevo campo de especialización. En cambio, Microsoft ha creado una técnica que mejora el rendimiento en distintos campos: ingeniería eléctrica, aprendizaje automático, filosofía, contabilidad, derecho, enfermería y psicología clínica.
Otro ejemplo que pone de relieve el poder de la ingeniería de estímulos procede de Anthropic. Su equipo mejoró el rendimiento de su modelo Claude 2.1 en un 98% en una evaluación de recuperación de información. Sólo una frase.
Manipular los LLM es como jugar con una herramienta alienígena. La única manera de averiguar lo que puede hacer es pulsar sus botones de diferentes maneras. Cuando sale una nueva versión de esta herramienta alienígena, es de esperar que tenga más capacidades, pero también más botones.
Lo ingenuo es pensar que “los modelos más capaces requieren menos indicaciones”. En realidad, cuanto más capaz sea tu modelo, más funciones podrás desbloquear utilizando las indicaciones adecuadas.
¡Es hora de brillar, agente humano!
A largo plazo, utilizaremos los LLM como sistemas operativos para manejar la potencia de cálculo y resolver todo tipo de problemas. A medio plazo, programaremos agentes de IA para que realicen tareas para las que antes escribíamos código. En ambas etapas, utilizaremos el inglés como principal lenguaje de programación.
Vale, pero ¿qué pasa ahora?
Hasta que los agentes de IA se pongan al día, es tu momento de brillar. Piensa en ti como un artesano de la tecnología que combina modelos de IA, código y aplicaciones tradicionales para abordar retos complejos. Jugarás al Lego, por así decirlo, y gracias a la comunidad de código abierto en particular, tendrás un suministro interminable de piezas que podrás combinar para crear proyectos innovadores.
Los LLM son piezas especiales de este hipotético Lego porque a menudo acabarás con uno en el centro de tus creaciones. Esto nos lleva a los dos sabores complementarios de Prompt Engineering.
Verás, Prompt Engineering tiene dos significados: (1) Escribir instrucciones en lenguaje natural de alta calidad para LLMs y (2) Escribir código sobre LLMs para mejorar su salida usando prompting condicional y otras técnicas.
La segunda definición incluye la primera porque, incluso si envuelves un LLM con código, sigues utilizando el inglés para interactuar con él. He aquí cómo ambas definiciones se entrelazan con el uso del LLM.
- LLM como programas independientes: Aquí se escriben instrucciones de alta calidad en lenguaje natural para obtener los mejores resultados posibles. Algunos ejemplos son la generación de ideas, el resumen de documentos y la escritura de código.
- LLMs como parte de un programa diseñado por ti: Aquí escribes software (en Python, Java, C++ u otros lenguajes de programación) envuelto en LLMs para lograr tareas específicas. Algunos ejemplos son el análisis del sentimiento de los comentarios en las redes sociales, los chatbots especializados y los agentes autónomos.
Veamos ahora qué aspecto tiene la ingeniería de avisos en cada caso de uso.
1️⃣ Prompt Engineering para “LLMs como programas independientes”
El caso de uso más común para LLMs es interactuar con ellos a través de interfaces web como ChatGPT’s, y Bard’s.
En función de sus necesidades específicas, puede crear una biblioteca personal de avisos. Querrás que tus prompts estén planificados y sean fáciles de actualizar. De esta forma no tendrás que reescribir tus prompts desde cero o buscarlos en el historial de chat cada vez que quieras ejecutar uno de ellos.
A continuación encontrarás tres ejemplos variados de avisos flexibles que pueden servirle de inspiración:
[PROMPT TEMPLATE #1 DOCUMENT SUMMARY] Act like a research assistant in the field of <field_name>. I will give you a report titled <title_of_the_report> as input. Please access the report through the following link <URL_of_the_report> using the online browsing feature. Summarize the report in less than <summary_wordcount> and add <number_of_quotes> from the authors. Make sure to pick precise quotes and list them as bullet points. ## Desired format: Title: <title_of_the_report> Link: <URL_of_the_report> Summary of the report based on the previous instructions. - Quote #1 - Quote #2 - Quote #3 - etc. ## Inputs: <field_name> = Placeholder for the field of expertise of your document. <title_of_the_report> = Placeholder for the title of the report you want summarize. <URL_of_the_report> = Placeholder for web address where the report can be found. <summary_wordcount> = Placeholder for the maximum word count for the summary. <number_of_quotes> = Placeholder for the number of quotes to be extracted from the report. [PROMPT TEMPLATE #2 PRODUCT DESCRIPTION] Act like an expert copywriter. ## Role: Write a product description for an e-commerce shop. Use the following structure and fill in the details based on the placeholders provided: Product Name: <product_name> Introduction: Start with a captivating opening sentence about <product_name>, suitable for <target_audience>. Key Features: List the main features of <product_name>. Include <product_features>. Benefits: Explain how <product_name> benefits the user, addressing <target_audience> needs. Call to Action: Encourage the reader to make a purchase decision with a compelling call-to-action. SEO Keywords: Integrate <seo_keywords> naturally within the text for SEO purposes. Tone: Maintain a <brand_tone> throughout the description to align with the brand's voice. ## Inputs: <product_name> = Placeholder for the name of the product. <product_features> = Placeholder for listing the specific features of the product. <target_audience> = Placeholder to specify the target audience or demographic for the product. <seo_keywords> = Placeholder for SEO-optimized keywords relevant to the product. <brand_tone> = Placeholder to define the brand's tone of voice to be reflected in the product description. [PROMPT TEMPLATE #3 PROGRAMMING ASSISTANT] Act like a software engineer. ## Role: Your role is to write a program in <programming_language>. Your program must follow these instructions: <user_instructions>. Reason step by step to make sure you understand the user's instructions before you generate the code. Ensure the code is clear, well-commented, and adheres to best practices in <programming_language>. ## Format: Give a clear title to each code snippet you generate. For example you can title the first snippet "Snippet #1 version 1," the second snippet "Snippet #2 version 1," and an updated version of the second snippet can be "Snippet #2 version 2." ## Inputs: <programming_language> = Placeholder for the programming language in which you want the code to be written (e.g., Python, JavaScript). <user_instructions> = Placeholder for the specific instructions or description of the task you want to be turned into code. 2️⃣ Prompt Engineering para “LLMs como parte de un programa que diseñas”
En este caso, utilizarás tus LLMs como funciones que puedes llamar para procesar, analizar y generar lenguaje natural.
Por ejemplo, tu código puede llamar a un LLM para analizar el sentimiento en una serie de comentarios relacionados con un producto determinado. Después de procesar estos comentarios, puedes utilizar otra función dependiente de un LLM para generar una respuesta basada en los resultados anteriores.
Ahora, veamos cómo puedes incrustar LLMs en tu código. Hay tres formas principales:
- Conectarse a través de una API proporcionada por otra empresa.
- Utilizar un servidor local dentro de la red de tu empresa.
- Instalar un LLM de código abierto directamente en tu ordenador.
Aquí tienes un ejemplo básico de cómo puedes utilizar un LLM dentro de un programa:
PYTHON CODE SNIPPET : # Objective: Carry out a sentiment analysis on a series of comments stored in an Excel file # LLM choice: We’ll use OpenAI API to call the gpt-4 model import pandas as pd # version used 2.1.3 from openai import OpenAI # version used 1.2.0 # Define the path to your API key file API_key_path = “C:/Users/…..API_Key.txt” # Replace with your actual API key file path # Read the API key from the file with open(API_key_path, ‘r’) as file: API_key = file.read().strip() # .strip() removes any leading/trailing whitespace # Create the OpenAI client object with the API key client = OpenAI(api_key=API_key) # Define a function that analyzes sentiment in a series of comments stored in an Excel file def analyze_sentiments(input_file): # Read the input Excel file inputs_df = pd.read_excel(input_file) # Select the column by its name ‘comments’ if ‘comments’ in inputs_df.columns: comments = inputs_df[‘comments’] else: raise ValueError(“Column ‘comments’ not found in the input file”) sentiments = [] for comment in comments: # Prepare API call messages = [ { “role”: “system”, “content”: “Analyze the sentiment of the following comment. Use a single word to describe the sentiment. Either `Positive` or `Negative`. Refrain from writing any extra text. Thanks!”, }, { “role”: “user”, “content”: comment, } ] model = “gpt-4” temperature = 1.0 max_tokens= 100 # Adjust based on expected response length # Make the API call chat_completion = client.chat.completions.create( model=model, temperature=temperature, max_tokens= max_tokens, messages=messages ) # Extract response if chat_completion.choices: sentiment_result = chat_completion.choices[0].message.content.strip() else: sentiment_result = “No response” sentiments.append(sentiment_result) # Combine comments with their sentiments result_df = pd.DataFrame({ ‘Comment’: comments, ‘Sentiment’: sentiments }) # Write to a new Excel file output_file = “path_to_your_output_file.xlsx” # Replace with your desired output file path result_df.to_excel(output_file, index=False) print(“Sentiment analysis complete. Results saved to”, output_file) # Example usage input_file = “path_to_your_input_file.xlsx” # Replace with your input file path analyze_sentiments(input_file) # Homework exercice: Write a function that uses a dynamic prompt to write a different response based on the result of sentiment analysis.Cómo mejorar tus habilidades de Prompt Engineering
La respuesta corta es una elegante cita que le robé a Stephen King. “Debes hacer dos cosas por encima de todas las demás“, dijo. “Leer mucho y escribir mucho“.
Al igual que escribir, la ingeniería de prompts parece fácil hasta que te sientas y le das al teclado. Como utilizamos el lenguaje natural para escribir las instrucciones, lo abordamos con una falsa sensación de simplicidad.
Perdona la repetición, pero los modelos de IA no pueden leerle la mente (todavía).
Si quieres respuestas de calidad, tienes que aprender a expresar tus intenciones con la mayor claridad posible. Mantente al día de la bibliografía para aprender nuevas técnicas y haz tantas repeticiones como puedas para integrarlas.
Puede que te aburras de teclear instrucciones aleatorias en una ventana contextual parpadeante. El antídoto es encontrar problemas difíciles de resolver. ¿Cómo puedes aleatorizar partes de tu salida? ¿Cómo cambiar dinámicamente el contenido de tu prompt? ¿Puedes programar un asistente que resista los intentos de jailbreaking?
Encuentra problemas difíciles de resolver y Prompt Engineering pasará de ser “una habilidad que tienes que aprender” a una dosis diaria de “dichosa (aunque a veces frustrante) estimulación intelectual“.
Además, hay otros dos temas que merecen tu atención: El aprendizaje automático en general y el aprendizaje profundo en particular. Te interesa explorar tanto sus puntos fuertes como sus defectos, porque una vez que entiendas cómo funciona la tecnología que hay detrás de la IA generativa, desarrollarás intuiciones sobre por qué tu modelo se comporta de determinadas maneras.
Aquí tienes algunos recursos que pueden ayudarte a empezar:
- Making Friends of Machine Learning por Cassie Kozyrkov. (Serie de vídeos de YouTube)
- Intro to Large Language Models por Andrej Karpathy. (Vídeo de YouTube)
- Prompt Engineering for Developers por Isa Fulford y Andrew Ng (Curso en línea gratuito)
- How to Write Expert Prompts for LLMs por este tipo calvo (Guía completa de 16.000 palabras que incluye más de 25 técnicas de prompting, ejemplos y comentarios).
La versión TL;DR
Los LLM se están convirtiendo progresivamente en nuestra interfaz con la potencia de cálculo. La ingeniería de instrucciones es el arte de escribir instrucciones que obtengan los mejores resultados posibles de tus LLM (y otros modelos de IA).
- Utilizaremos el lenguaje natural para interactuar con los futuros sistemas operativos.
- Antes de eso, usaremos el lenguaje natural para programar asistentes de IA.
- La ingeniería de instrucciones se realiza principalmente en lenguaje natural, pero eso no significa que los modelos de IA puedan leerte la mente. Todavía tienes que expresar tus instrucciones con claridad.
- Si puedes escribir instrucciones de alta calidad, podrás escribir código.
- Quienes escriban mejores instrucciones construirán mejores programas y obtendrán mejores resultados.
- El prompt engineering es la clave para desbloquear las capacidades latentes de los modelos lingüísticos (y de los modelos de IA en general).
- La ingeniería de instrucciones es una ciencia empírica. Se puede aprender de las experiencias de los demás, pero se aprende más de las propias.
¿Seguimos en contacto?
Puedes suscribirte para recibir notificaciones por correo electrónico cuando publique nuevos posts (en inglés).
También estoy activo en Linkedin y X y respondo a todos los mensajes.
Para consultas sobre Prompt Engineering, escríbeme a: nabil@nabilalouani.com.
Y por si te lo estás preguntando: este artículo está generado 100% por humanos.