

La semana pasada hablamos de la necesidad de toolings que permita a los científicos de datos implementar modelos más fácilmente. En lugar del enfoque «over the wall» para la entrega del modelo, nos gustaría tener más control, pero también acortar la curva de aprendizaje para las operaciones de ingeniería. ¿Cómo podemos domar la aplicación de Machine Learning industrial?
¡Presentamos Metaflow!
Tabla de contenidos
Metaflow
Metaflow es una herramienta de código abierto desarrollada por Netflix y dirigida a resolver algunos de nuestros dolores de cabeza.
Metaflow se desarrolló originalmente para aumentar la productividad de los científicos de datos que trabajan en una amplia variedad de proyectos, desde estadísticas clásicas hasta aprendizaje profundo de vanguardia.
Hay varias áreas en las que este paquete está ayudando.
1. Flujo de trabajo integrado
Tendemos a parar en la etapa pickle.dump(). Con esto, tendríamos que hacer un poco más para poder etiquetar nuestros «pasos», y los pasos conducen a una tubería flexible para su uso posterior.
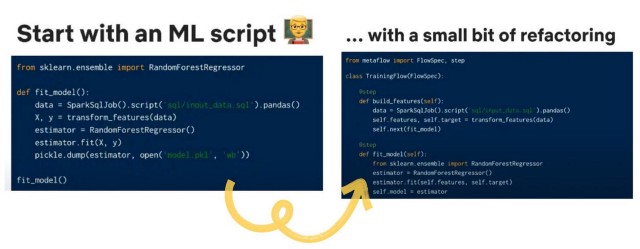
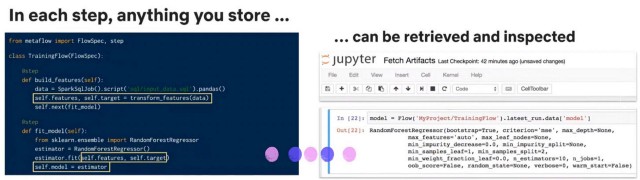
2. Trabajar con control de flujo y versión
Las cosas se almacenan en el camino para que estos artefactos puedan ser recuperados más tarde. El siguiente ejemplo recupera las especificaciones del modelo de la ejecución más reciente. Y se puede acceder a diferentes run.id para cada usuario según sea necesario.
Básicamente, puedes ejecutar tu script sin tener que preocuparte en que el sistema haya comprometido tu código o haya almacenado todos los parámetros de entrada en un notebook. Puedes retroceder en el tiempo y recrear todo tu historial de trabajo, o reiniciar desde cualquier paso.
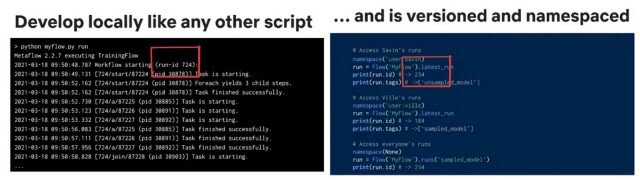
El código de implementación para el trabajo de formación es simplemente: python myflow.py run
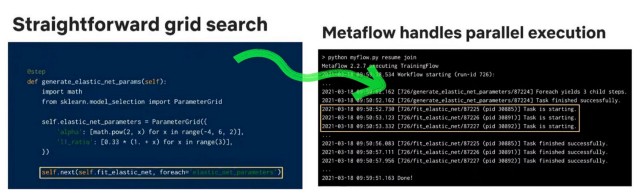
3. Agricultura de trabajos de múltiples modelos
Para configurar varios trabajos para un problema como la búsqueda en cuadrícula, solo necesitas una línea más de código para entregar la paralelización a metaflow.
4. Descarga de cómputo
Para romper el límite de recursos de tu portátil, simplemente puede anotar los recursos deseados y entregarlos a metaflow con el decorador de @resources.
Metaflow se encargará de crear la imagen de docker adecuada, publicar el código de usuario, envolverlo y asegurarse de que todos los datos estén disponibles en esa instancia remota ejecutando el código de usuario y luego guardar todos los datos de nuevo en el almacén de datos.

Metaflow puede especificar fácilmente los requisitos de recursos para diferentes segmentos de tu código y eso impulsa la utilización de tu clúster de computación. Esto es realmente importante desde el punto de vista del coste cuando hay muchos usuarios que ejecutan diferentes cargas de trabajo.
5. Dependencias de cómputo especificadas fácilmente
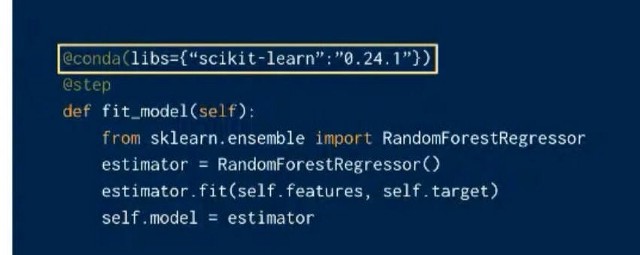
El caso de uso aquí podría ser, por ejemplo, si entrenaste un modelo con Pytorch 1.11 y te gustaría migrar a la versión 1.12, podrías agregar un paso más con la versión más reciente para entrenar dos modelos en paralelo y comparar las ejecuciones para decidir si es seguro actualizar.
6. Preparándose para la producción
Una vez que hayas terminado con tu flujo de trabajo y puedas escalar tu flujo de trabajo en un proveedor cloud, lo siguiente que podrías considerar es cómo ejecutar el flujo de forma asíncrona cuando los datos se actualizan o el rendimiento del modelo ha decaído. Aquí es cuando necesitas publicar tu flujo de trabajo en un orquestador de flujo de trabajo.
Se vuelve más complejo cuando los flujos de trabajo de machine learning responden a los flujos de trabajo de ingeniería de datos ascendente que pueden no ser responsabilidad de su equipo. El equipo de ingeniería de datos puede tener diferentes SDK o paradigmas de programación en los que puede necesitar encajar a pesar de que ha terminado con tu creación de prototipos locales.
Metaflow ayuda al usuario a implementar su código de creación de prototipos en estos orquestadores de flujo de trabajo de producción y hace que su trabajo sea inmediatamente parte del resto del ecosistema de ingeniería.
7. Integración rápida y sucia en cualquier momento
Lo que más me impresiona es cómo metaflow puede ayudar a implementar prototipos rápidamente sin implicar SLA pesados. Como configurar una función o modelo como servicio rápidamente y permitir a los usuarios simplemente implementar fragmentos de su código y simplemente usarlo.
Utiliza un decorador de @endpoint para ejecutar la implementación. En el siguiente ejemplo, el usuario está interesado en implementar el flujo de entrenamiento #726. De esta manera, los usuarios pueden optar por actualizar su punto final de alojamiento muy fácilmente en función de sus resultados de experimentación.

Hay más capacidades que ofrece metaflow que resuenan con muchos de los casos de uso que he visto, como:
- Facilitar el acceso rápido a los datos de alto rendimiento con Spark SQL
- Facilitar la colaboración, la replicabilidad y la reproducibilidad del trabajo entre los miembros del equipo (a medida que se registran todos los pasos)
- Apoyo a los usuarios de R
Como facilitador de la organización de la ciencia de datos, a menudo pienso en cómo hacer que la vida de nuestros compañeros científicos de datos sea más fácil y plena. Somos como un estudio en el que estamos desarrollando soluciones a diferentes problemas en el día a día.
Al final del día, la gestión de una gran cartera de proyectos de ciencia de datos también es un problema de optimización. Además de la dimensión de impacto y las prioridades que nos preocupan profundamente, es crucial entender cómo se orquesta el desarrollo de la IA y cuáles son los costos. Hay puntos de cabeza que resolver para permitir la IA acelerada.
Mis equipos han utilizado el enfoque «por encima de la pared» para el despliegue, así como para construir puntos finales de contenedores Docker, usando Sagemaker, etc. Metaflow está definitivamente en mi lista para probarlo como la herramienta de implementación de próxima generación.
Gracias por leer mi boletín. ¡Puedes seguirme en Linkedin! Y puedes encontrar el post original aquí.