

Hay una serie de retos únicos que se plantea un asistente de voz en comparación con los chatbots basados en texto. El problema más difícil de resolver es gestionar con éxito la gestión de los turnos propios en una conversación. Este reto debe considerarse a la luz de otros elementos como la irrupción, el ruido de fondo, etc. Cuando los humanos mantenemos una conversación telefónica, hay una secuencia de acontecimientos. Primero nos saludamos, luego nos ponemos de acuerdo sobre el motivo de la llamada (intención). A continuación se decide quién va primero y se gestionan las interrupciones (barge-in).
Tabla de contenidos
La versión resumida para un asistente de voz
- Los robots de voz tienen la clara desventaja de que sus características de diseño son invisibles desde la perspectiva del usuario.
- Hay que prever las conversaciones triviales, ya que los usuarios son más propensos a hablar por teléfono que en una interfaz de chatbot y, en general, son más verbales.
- La intención de la llamada debe establecerse firmemente al inicio de la misma. Una vez establecida la intención, el robot de voz debe hacerse cargo del diálogo, lo que requiere una detección precisa de la intención.
- El barge-in no debe ser demasiado sensible y debe activarse de forma explícita, en lugar de implícita.
- La detección del ruido de fondo es bastante precisa a través de un modelo acústico y se debe aconsejar a los interlocutores que se trasladen a un lugar tranquilo o que llamen más tarde. En lugar de intentar anular el ruido.

Charla trivial
Las conversaciones triviales forman parte de nuestro proceso de conversación diario y, por lo general, en las conversaciones hay una sección introductoria de conversaciones triviales. En ella, el usuario se presenta y suele decir desde dónde llama.
La charla no tiene por qué ser extensa, pero la cortesía básica debe estar integrada en nuestro asistente.
Menús de desambiguación
Después de una pequeña charla, hay que establecer la intención de la conversación. Lo mismo ocurre con nuestras conversaciones entre humanos, en las que la intención se establece desde el principio y, por tanto, es la base de la conversación.
El primer paso es pedir al usuario que diga el motivo de su llamada con unas pocas palabras.
Este paso podría evitarse si se utilizara un motor de propensión o algún tipo de búsqueda en el sistema empresarial para averiguar por adelantado el motivo de la llamada.
El robot de voz tiene que tomar el mando de la narración, como se explicará en el siguiente paso… sin embargo, es necesario tener la certeza de la intención antes de este paso.
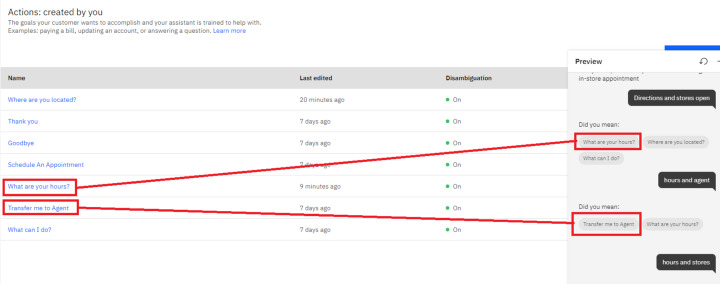
La forma más segura de confirmar la intención es utilizar los menús de desambiguación.
He aquí un ejemplo de cómo se pueden utilizar los menús de desambiguación… digamos que, por ejemplo, alguien llama al operador de telefonía móvil y declara que le han robado el teléfono, y se puede presentar un menú de desambiguación posterior. Todos los elementos del menú están relacionados con la pérdida o el robo del teléfono.
Por tanto, los menús de desambiguación pueden verse como un tema de una colección de intenciones. El menú de desambiguación puede preguntar al usuario:
¿Te gustaría…
~ Bloquear su línea,
~ Poner su dispositivo en la lista negra,
~ Realizar un cambio de SIM,
u obtener sugerencias para un nuevo dispositivo?
Tomar el mando de la narración
Una vez que se ha establecido claramente la intención y se ha eliminado la ambigüedad en la medida de lo posible, el asistente de voz debe tomar el mando de la narración y de los turnos de diálogo.
Especialmente en una implementación corporativa de dominio específico habrá procedimientos de cliente más largos para navegar, por lo tanto una secuencia fija de eventos que el usuario necesita pasar.
La irrupción debe ser explícita y no implícita, ya que la irrupción implícita puede dar lugar a ruidos aleatorios, a que el usuario tosa, etc., que rompan el flujo del diálogo y sean vistos como una irrupción.
Una intromisión explícita suele producirse cuando el usuario dice algo que no está relacionado con el turno de diálogo actual. En esta coyuntura se puede preguntar al usuario si quiere repetir su entrada, o terminar el proceso actual y hablar de otra cosa…
Detección de ruido accidental en el asistente de voz
Para el proceso de conversión de voz en texto, el reconocimiento automático del habla, se puede entrenar un modelo acústico sobre una muestra de expresiones del cliente. Algo que he comprobado en mi experiencia, es que un modelo acústico mejora significativamente la precisión de la transcripción de la voz a texto.
Otra cosa que he descubierto (por accidente), es que el modelo acústico traducía el ruido de una manera muy específica. Las frases transcritas para el ruido eran lo suficientemente coherentes como para aconsejar al usuario que se trasladara a un lugar tranquilo o que llamara más tarde.
Para terminar
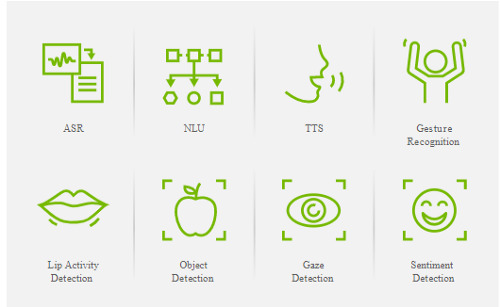
Resolver la toma de turnos y la irrupción en la conversación será difícil sin elementos como:
- Reconocimiento de gestos.
- Detección de la actividad de los labios.
- Detección de objetos.
- Detección de la mirada.
Puedes leer más sobre este tipo de procesos en el siguiente artículo. Sin embargo, hacer uso de los principios de diseño que enumero en este artículo contribuirá en gran medida a mejorar el NPS, el CSAT, la contención y la tasa de resolución de problemas de un voicebot.