

Para cada problema complejo hay una respuesta clara, sencilla y equivocada. – H. L. Mencken
Hay muchas técnicas prompt engineering, pero muchas de ellas tienen algo en común: el razonamiento directo. ¿Qué ocurre si intentamos lo contrario? ¿Podemos encontrar una solución a problemas que antes el modelo no podía resolver?
En este artículo hablamos de ello.
Tabla de contenidos
Razonamiento directo frente a indirecto

Los grandes modelos lingüísticos (LLM) han demostrado una capacidad increíble incluso en tareas complejas como la comprensión del lenguaje, el razonamiento lógico y el razonamiento matemático. El éxito de estos modelos es aún más increíble si se tiene en cuenta que lo han conseguido con técnicas zero-shot o few-shot way. Esto significa que los modelos son capaces de aprender del contexto (aprendizaje dentro del contexto).
Esto ha hecho que varios grupos se centren en intentar comprender cómo aumentar estas capacidades de los modelos, por lo que han surgido técnicas como la Cadena de Pensamiento (CoT) y muchas otras.
La cadena de pensamiento (CoT) anima al modelo a explicar los distintos pasos intermedios que conducen a la solución final. La idea es que, desplegando los distintos pasos, el modelo pueda llegar correctamente a la solución final (mientras que si salta directamente a la conclusión, el modelo suele equivocarse).
CoT y otras técnicas siguen lo que se denomina el marco del Razonamiento Directo (DR), en el que se crean cadenas lógicas desde los hechos dados hasta el resultado final. El problema de este enfoque es que no todos los problemas pueden resolverse de esta manera. Así que surge la pregunta: si nos enfrentamos a un problema que no puede resolverse, ¿podemos recurrir al razonamiento indirecto (IR)?
El razonamiento indirecto (IR) es un enfoque complementario y alternativo para resolver problemas. Uno de los métodos más utilizados consiste en explotar procedimientos lógicos para demostrar que dos proposiciones son equivalentes. Por ejemplo, se puede demostrar que una proposición es verdadera suponiendo que es falsa y llegando a una contradicción: p → q y su contrapositiva ¬q → ¬p, si demostramos que ¬q → ¬p conducen a una contradicción
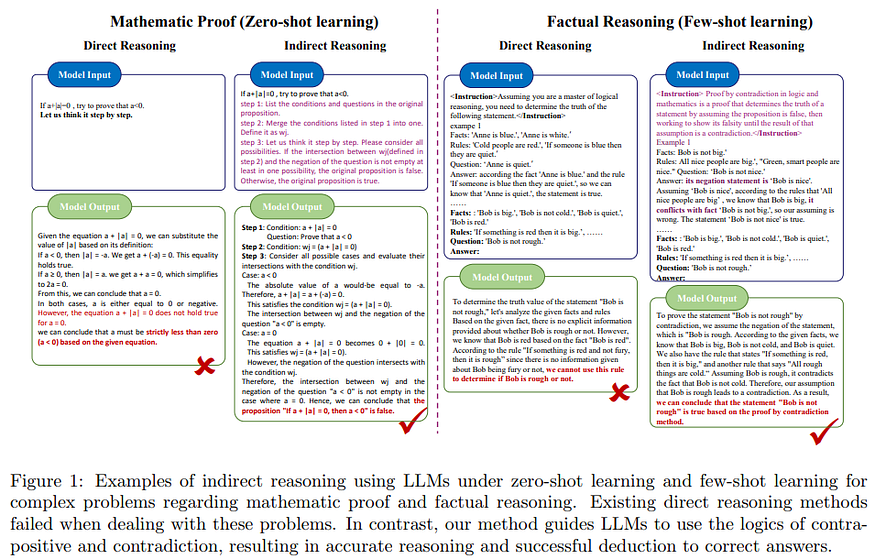
Razonamiento indirecto para resolver problemas
G. H. Hardy describió la prueba por contradicción como «una de las mejores armas de un matemático», diciendo: «Es un gambito mucho más fino que cualquier gambito de ajedrez: un jugador de ajedrez puede ofrecer el sacrificio de un peón o incluso de una pieza, pero un matemático ofrece la partida» (wikipedia).
El razonamiento indirecto es un sistema explotado por los humanos y podría ser explotado por los modelos para poder resolver diversos problemas en los que fallan las técnicas de razonamiento directo. ¿Cómo conseguir que los LLM se beneficien del IR?
Un nuevo estudio muestra cómo esto es posible simplemente utilizando un nuevo tipo de prompt.
En matemáticas y en algunas aplicaciones prácticas, hay circunstancias en las que la demostración directa puede no ser factible o eficaz. En tales casos, a menudo se utilizan los métodos de demostración indirecta para verificar una afirmación. Existen dos métodos populares de prueba indirecta, que son: el método contrapositivo y el método de contradicción (fuente).
La idea de los autores es explotar tanto las contradicciones como los contrastes para dirigir un modelo hacia la solución cuando no es posible obtener pruebas directas. El objetivo de los autores es permitir que el modelo realice razonamientos factuales en lenguaje natural: teniendo una pregunta Q hay que llegar a una respuesta A mediante un razonamiento P que explote los hechos conocidos F y las reglas R (las reglas suelen formar parte del conocimiento previo y no necesariamente se hacen explícitas).
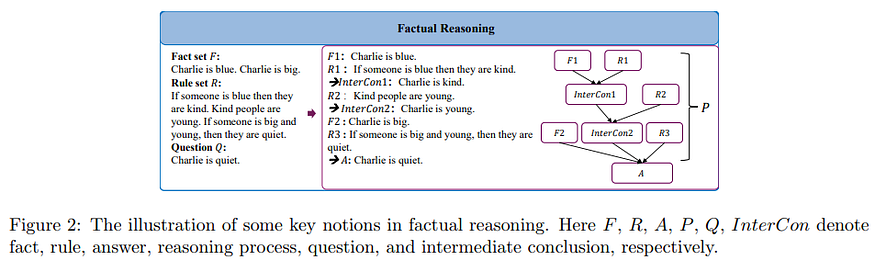
¿Cómo adaptar el razonamiento indirecto a un LLM?
Para los autores, el proceso se divide en dos partes:
- Rule augmentation. En este paso, se pide al modelo que aumente el conjunto de reglas.
- Indirect reasoning. Recibidos los hechos, las reglas y las preguntas, el modelo realiza un razonamiento indirecto.
Por tanto, los autores definen un modelo de zero-shot y un few-shot template para prompts, por lo que los IR puedan utilizarse con un LLM.

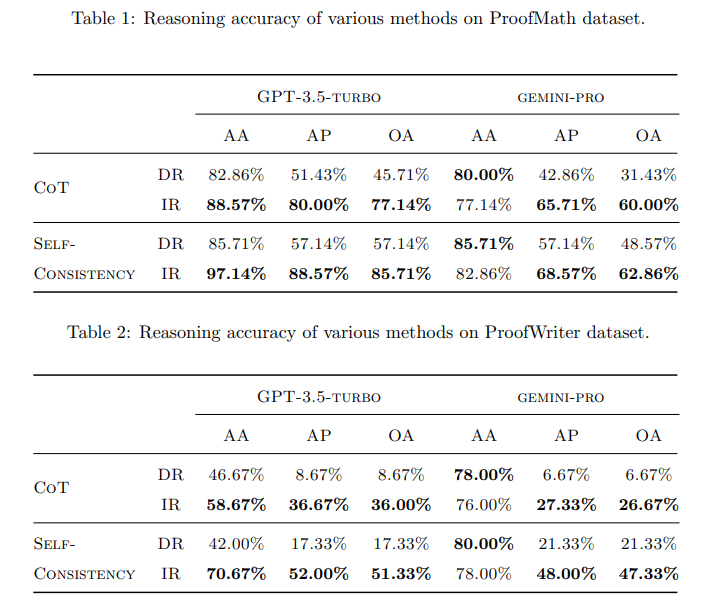
La evaluación del rendimiento del razonamiento de un método incluye la investigación de la corrección de la respuesta A y el proceso de razonamiento P. Por lo tanto, aquí utilizamos tres métricas: la precisión de la respuesta (AA), la precisión de los procesos de razonamiento (AP) y la precisión global (OA) (fuente).
Los autores definen prácticamente tres métricas basadas en el número de ejemplos con respuestas correctas, proceso correcto y ambos correctos.
Los autores utilizan tanto COT como autoconsistencia además de su prompt para ver cómo cambia el modelo en respuesta al razonamiento indirecto. Utilizan tanto GPT-3.5 como Gemini como modelos y los prueban en conjuntos de datos tanto de lenguaje natural como matemático.
Por ejemplo, lo prueban en un conjunto de datos de preguntas en lenguaje natural (ProofWriter) y otro de problemas matemáticos (ProofMath) en los que es necesario utilizar pruebas de contradicción para resolver los problemas. El uso de IR aumenta las capacidades del modelo a la hora de resolver este tipo de problemas.
Otro resultado interesante es que el aumento de reglas también ayuda al modelo, incluso sólo con DR.
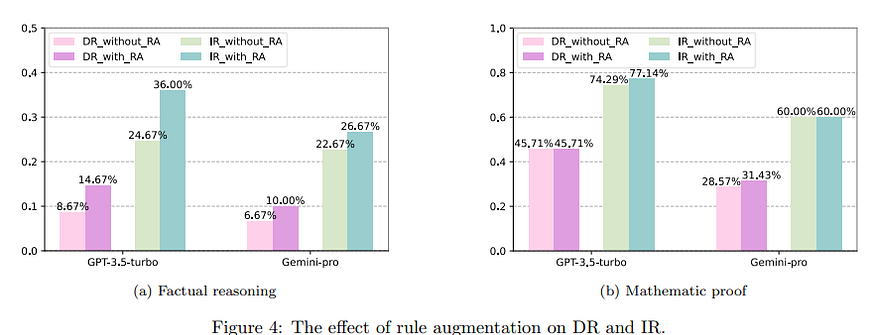
Además, otra ventaja es que este enfoque reduce los pasos para llegar a la conclusión (el proceso es, por tanto, más rápido).

Reflexiones de despedida

En los últimos tiempos, se han adoptado ampliamente diversos LLM para resolver tareas como el razonamiento factual, la generación de diálogos y la generación de contenidos multimodales. Estos enfoques han generado un notable valor económico e impacto social en múltiples aplicaciones (fuente).
Los LLM han entrado en producción en la actualidad y son utilizados por el público; por un lado, estos modelos siguen teniendo problemas con el razonamiento factual. A lo largo del tiempo se han desarrollado varias técnicas para mejorar la capacidad de razonamiento de los modelos. Esas técnicas explotan procesos denominados razonamiento directo, aquí los autores muestran que hay problemas que no pueden resolverse con DR pero que se benefician del razonamiento indirecto.
Si te ha parecido interesante:
Puedes buscar mis otros artículos, y también puedes conectar o ponerte en contacto conmigo en LinkedIn. Consulta este repositorio con noticias actualizadas semanalmente sobre ML e IA. Estoy abierto a colaboraciones y proyectos y puedes contactar conmigo en LinkedIn.
Aquí está el enlace a mi repositorio GitHub, donde estoy recopilando código y muchos recursos relacionados con el aprendizaje automático, la inteligencia artificial, y más.