

Cuando uno ve lo que Google acaba de conseguir, no es de extrañar que OpenAI lanzara de repente Sora unas horas más tarde para distraer al mundo del hecho de que ya no están a la cabeza en el espacio de los Grandes Modelos de Lenguaje (LLM).
Gemini 1.5 Pro de Google es un salto generacional en términos de modelos lingüísticos multimodales, o MLLM, como GPT-4 lo fue para los LLM en marzo de 2023.
En concreto, es capaz de procesar millones de palabras a la vez, vídeos de 40 minutos de duración u 11 horas de audio en cuestión de segundos con una precisión de recuperación de contexto del 99%, algo absolutamente inaudito en este campo hasta la fecha.
La era de las secuencias largas ha llegado, y con ella, un nuevo actor dominante se posiciona por primera vez frente a OpenAI.
Tabla de contenidos
Google, el rey, reclama su trono
En noviembre de 2022, el rey inequívoco de la industria de la IA durante más de una década, Google, vio como una empresa parcialmente desconocida (al menos para el gran público) y respaldada por Microsoft, OpenAI, lanzaba un producto, ChatGPT, que cambió por completo la narrativa y les envió a la posición de subcampeón.
Sam, el hombre más odiado del cuartel general de Google
De repente, la IA se convirtió en la tecnología más importante, pero al mismo tiempo, Google ya no era vista como la empresa puntera del sector. Sam Altman había lanzado el LLM más potente que el mundo había visto jamás, ChatGPT.
Al mismo tiempo, Google no tenía nada que ofrecer. Claro que tenían cosas en marcha dentro de su sede de Mountain View, como LAMDA, pero ni de lejos se acercaban a la calidad y la preparación de la producción que tenía ChatGPT.
¿Y lo más doloroso? ChatGPT se basaba en Transformer, una arquitectura que, para consternación de muchos accionistas de Google en ese momento, había sido creada por investigadores de Google en 2017.
En otras palabras, era como si Google hubiera estado de brazos cruzados mientras tenía la «salsa secreta» del próximo salto tecnológico en un armario polvoriento. Imperdonable. Naturalmente, Google recibió el memorándum y se puso manos a la obra.
Todos los caminos conducían a Gemini
Después de un tiempo, Google lanzó Bard, un completo y absoluto desastre si lo comparamos con el modelo GPT-4 de OpenAI que corría detrás de ChatGPT lanzado en marzo de 2023.
Ahora Google parecía aún más atrasado que nunca.
Entonces, a finales de 2023, Google finalmente lanzó Gemini 1.0, una familia de LLMs nativamente multimodales, lo que significa que fueron entrenados desde cero para procesar vídeo, imágenes y texto, además de ser capaces de generar texto, código e imágenes, lo que puso a la compañía de búsquedas al menos al nivel de GPT-4 de OpenAI, si consideramos Gemini 1.0 Ultra, el modelo más capaz.
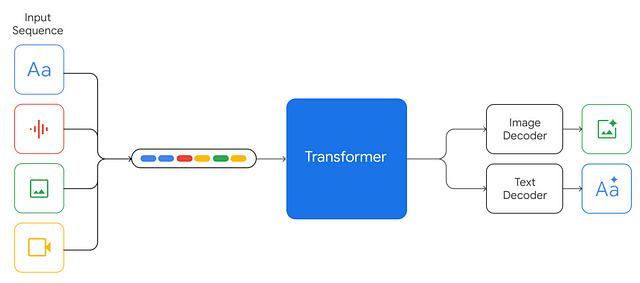
Sin embargo, si pensamos en los plazos, esto no fue nada especial.
A fin de cuentas, Gemini salió al mercado en noviembre del año pasado para competir con un producto que OpenAI había lanzado en marzo.
Como era de esperar, para evitar el desprecio de la industria, lanzaron rápidamente Alphacode 2 al mismo tiempo, un modelo revolucionario que combinaba Gemini con un algoritmo de búsqueda y cálculo en tiempo de prueba para permitir a la IA competir en el nivel superior de la programación competitiva, obteniendo un asombroso percentil del 85%.
¿Qué es el cálculo en tiempo de prueba?
La computación en tiempo de prueba significa que, para maximizar las posibilidades de obtener una respuesta correcta, Alphacode 2 genera hasta un millón de posibles respuestas a cualquier pregunta en tiempo de ejecución, y utiliza un algoritmo de búsqueda y filtrado para llegar a la mejor respuesta y responder.
En lugar de la respuesta básica del «Sistema 1» que te dan los LLM, es como si el modelo «explorara» el abanico de posibilidades hasta encontrar la mejor opción, como haría un humano.
Salvado por la campana.
Pero ahora, por fin, Google se lo ha «cargado» de verdad gracias a Gemini 1.5, hasta el punto de que OpenAI se ha visto «obligada» a lanzar Sora inmediatamente después, ya que Google ha recuperado el trono de la IA con un salto generacional en términos de rendimiento general y de secuencia larga.
Gemini, el supermodelo de largo alcance
En pocas palabras, Gemini 1.5 es impresionante.
Aunque sólo disponemos de los resultados del modelo Pro, el de tamaño medio, lo que presumiblemente indica que pronto llegará un modelo aún mejor, las puntuaciones son increíbles.
Recordatorio: La familia Gemini se divide en tres grupos, de menor (por tanto peor) a mayor (por tanto mejor), Nano, Pro y Ultra.
Para empezar, tiene la ventana contextual más larga y de rendimiento optimizado que conoce el ser humano, de hasta 10 millones de tokens.
Pero, ¿qué es un token y qué es la ventana contextual?
Los tokens son las unidades utilizadas por los Transformers para procesar y generar datos. En el caso del texto, suelen tener entre 3 y 4 caracteres. Por ejemplo, aunque esto dependerá del tokenizador que utilices (un modelo que divide tu texto en tokens), «Londres» podría dividirse en tokens «Lon» y «don».
Por otro lado, la ventana de contexto es la mayor cantidad de tokens que un LLM puede procesar en un momento dado. Es su memoria en tiempo real, algo parecido a lo que la memoria de acceso aleatorio (RAM) es para los procesadores informáticos.
Las ventanas contextuales existen por una sencilla razón: las secuencias largas son caras y difíciles de modelar.
En concreto, los costes de ejecución de un LLM tienen una complejidad cuadrática en relación con la longitud de la secuencia. En términos sencillos, si duplicas la longitud de la secuencia que les das, el coste se cuadruplica.
Además, los Transformadores sufren una gran degradación de su rendimiento cuando trabajan con secuencias más largas que para las que fueron entrenados.
Este problema se conoce como extrapolación (aunque también influyen otras características de diseño, como la elección de las incrustaciones posicionales correctas, pero esa es una conversación para otro momento).
Piensa en la extrapolación como si te hubieras entrenado para correr 8 kilómetros al día y, de repente, un día inesperadamente fueras a hacer 15. Naturalmente, esos 16 kilómetros extra van a ser más duros y vas a rendir mucho peor. Naturalmente, esas 10 millas extra van a ser más duras y vas a rendir mucho peor.
Pero, para entender el tamaño del aumento de la ventana contextual de Google, ¿cuánto son 10 millones de tokens?
Pues eso:
- Alrededor de 7,5 millones de palabras, o unas 15.000 páginas de 500 palabras, que es mucho más que toda la saga de Harry Potter
- Vídeos mudos de 44 minutos de duración
- 6-8 minutos de un vídeo estándar de YouTube
De una sola vez.
Como referencia, el líder actual en esta faceta es Claude 2.1, con hasta 200.000 tokens. Es decir, unas 150.000 palabras, 50 veces menos que Gemini 1.5.
Y no sólo eso, sino que consiguieron un 99% de precisión en la recuperación de hechos concretos y puntuales a partir de secuencias extremadamente largas, como puede verse en la imagen inferior (no pudieron resistirse a poner en aprietos a ChatGPT en el proceso):

Otro resultado asombroso fue que el modelo aprendió Kalamang, una de las lenguas más raras que existen, con sólo un puñado de documentos y casi igualando el rendimiento humano a pesar de que ambos tenían la misma información.
Y, en el proceso, destruyeron absolutamente otros modelos de frontera para esa tarea:
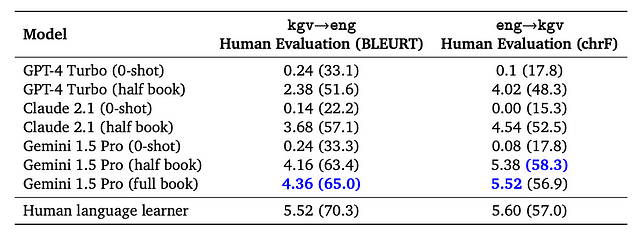
Esta hazaña no puede subestimarse, ya que significa que la IA se está convirtiendo poco a poco en «tan buena» como los humanos en términos de eficiencia de aprendizaje.
Pero la verdadera pregunta es: ¿cómo lo han conseguido?
La coronación de los expertos
En el informe técnico, Google atribuye su éxito principalmente al hecho de que Gemini 1.5 utiliza la Mezcla de Expertos (Mixture-of-Experts layer, MoE) como principal impulsor de la arquitectura.
Divide y vencerás
MoE es una técnica relativamente conocida que se ha convertido en un estándar en la actualidad, con ejemplos como Gemini 1.5, Mixtral-8x7B o GPT-4 (rumor más o menos confirmado).
El principio es bastante sencillo.
En lugar de tener un gran modelo experto, se reúne un grupo de modelos expertos más pequeños especializados en determinadas regiones de la entrada.
Pero, ¿qué entendemos por regionalización de input?
El secreto de las redes neuronales es que aproximan (aprenden) un mapa muy complejo entre inputs y outputs. En el caso del lenguaje, esto significa que aprenden a mapear cuidadosamente la siguiente palabra de una secuencia basándose en las palabras anteriores.
El espacio de entrada, es decir, el espacio de todas las entradas posibles (todas las posibles secuencias de texto que puede enviar a ChatGPT) es enorme, pero las redes neuronales son capaces de crear una función, o mapa, que «divide» este espacio de modo que, independientemente de la especificidad de la secuencia, sigue prediciendo con exactitud sin importar lo poco común que sea la secuencia de entrada.
Pero, ¿qué hace que MoE sea tan bueno?
Sencillo: en lugar de obligar al modelo a aprender un mapa global de todas las posibles entradas a todas las posibles salidas, se crean «expertos», redes neuronales más pequeñas que se centran en regiones de inputs específicos.
Por ejemplo, un experto puede llegar a dominar las ciudades europeas, mientras que otro se convierte en experto en la fauna de Groenlandia.
En realidad, al contar con un número limitado de expertos, estos siguen siendo polifacéticos y competentes en miles de temas de entrada diferentes, pero combinados dan cuenta de una especificidad mucho mayor que teniendo un experto global.
Tomando como ejemplo el modelo Mixtral-8x7B MoE de Mistral, el modelo se divide en 8 expertos. Así, para cualquier entrada, 2 de los expertos son elegidos para responder, mientras que el resto permanece en silencio.
Por lo tanto, MoE es lo mejor de ambos mundos, ya que:
- Se consigue entrenar una red neuronal enorme, un elemento esencial para crear buenos MLLM.
- En el momento de la inferencia, sólo se ejecuta una fracción de la red, lo que ahorra costes y reduce la latencia.
Si te interesa saber cómo se hace, consulta el artículo de Mistral.
Para abreviar, MoE funciona dividiendo las capas Feedforward, una pieza esencial en el Transformador, en grupos, con una puerta delante. Esta puerta, normalmente una función softmax que clasifica a los expertos en orden probabilístico, decide qué expertos participan en cada entrada, activando a aquellos y silenciando a los demás.
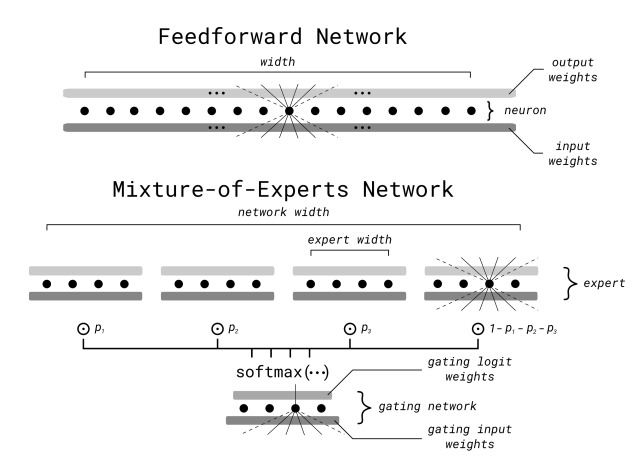
Sin embargo, la arquitectura MoE no explica cómo han conseguido un modelado de secuencias largas asequible y eficaz.
No explican cómo, pero podríamos saberlo.
Compresión en caché
Como ya se ha mencionado, uno de los problemas de trabajar con secuencias largas son los enormes costes, y una de las mejores formas de reducirlos es mediante la cuantización.
La cuantización reduce la precisión de los parámetros del modelo para ahorrar memoria. Por ejemplo, para un modelo de 50.000 millones de parámetros con precisión float32 (32 bits por parámetro, o 4 bytes), el archivo de pesos ocupa 200 GB, por lo que se necesitan al menos 3 GPU de última generación de 80 GB sólo para alojar el modelo.
En los Transformers, todo el modelo se ejecuta para cada predicción, por lo que es necesario almacenarlo en RAM. Algunas técnicas, como los LLM Flash de Apple, pueden ayudar a almacenar algunas partes del modelo en memoria flash.
Pero si reducimos la precisión de los parámetros a 4 bits, eso significa que nuestro modelo ocupa ahora 25 GB (pasando de 32 a 4), lo que significa que se puede ejecutar eficientemente el modelo en una GPU.
Pero con secuencias largas, entra en juego otro problema, caché KV.
Los transformadores se basan en el mecanismo de atención, un sistema muy intensivo en computación esencial para que Gemini o ChatGPT procesen el lenguaje.
Por suerte, los cálculos realizados en este proceso son muy redundantes durante esta tarea de predicción de la siguiente palabra. Así, esos cálculos redundantes se almacenan en memoria caché, evitando que todo el proceso resulte prohibitivamente caro.
Sin embargo, como se explica en un reciente artículo presentado por investigadores de Stanford, en estos casos la caché KV es el principal cuello de botella de la memoria:
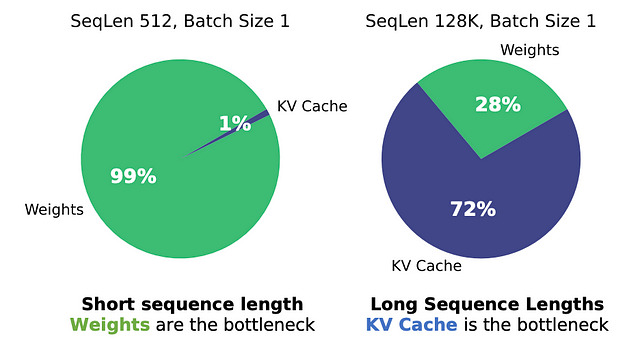
Así, lo que han hecho estos investigadores es lograr la primera cuantización de caché KV de alto rendimiento. En otras palabras, no solo los pesos del modelo pueden almacenarse con menor precisión, sino también la caché.
Esto permitió ejecutar secuencias de millones de tokens en una sola GPU, algo nunca visto.
Teniendo en cuenta los tiempos, apuesto a que Google ha utilizado un método similar o ha alcanzado un avance parecido para explicar sus resultados con Gemini 1.5.
Hay quien sospecha que Google también ha introducido una variante del mecanismo de atención que consume menos recursos informáticos, aunque no hay confirmación al respecto.
Una gran victoria para los transformadores
En definitiva, no se puede subestimar el avance de Google con Gemini 1.5.
De hecho, esta mejora de las funciones paso a paso es una clara señal de lo que está por venir: Compañeros de IA.
Pronto, los humanos tendrán a su disposición un modelo capaz de recordar conversaciones de meses (o incluso años) con absoluta precisión.
Un modelo que estará siempre dispuesto a escuchar, siempre dispuesto a ayudar y siempre recordará tus pensamientos, problemas y preocupaciones.
Un verdadero amigo digital.
Esto puede parecer algo malo, pero en última instancia creo que algunas personas, personas en la era de la soledad creciente, necesitan a alguien, o «algo» con quien hablar y estar dispuestos a escuchar en todo momento.
Sin embargo, ¿esto alienará cada vez más a los humanos, que se decidirán a hablar sólo con sus IA? Tal vez, lo que empeoraría las cosas.
Y tú, ¿cómo te sientes?
Por último, si te ha gustado este artículo, en mi LinkedIn comparto gratuitamente reflexiones similares de forma más completa y simplificada.
Espero poder conectar contigo.