

Escrito por Juankboards en Planeta Chatbot.
En mi anterior post, “Una breve introducción a Machine Learning”, definimos machine learning (ML) como las técnicas usadas para que una máquina mejore su rendimiento en una tarea específica a partir de experiencias previas. Para esto, se requiere de un proceso iterativo en el que se busca minimizar el error de la maquina realizando dicha tarea, lo que se conoce como entrenar el modelo.
Para entender bien lo anterior definiremos que es un modelo paramétrico, función de pérdida o de costo y optimización.
Tabla de contenidos
¿Qué es un Modelo Paramétrico?
Un modelo es una representación matemática de un proceso o fenómeno con el cual se puedan realizar predicciones. Un modelo paramétrico es entonces una representación en la que un grupo finito de parámetros contiene toda la información necesaria para realizar dichas predicciones. Estos parámetros forman un vector θ ([θ1, θ2……, θn]) con un numero fijo y finito de elementos… Pero ¿de donde salen estos parámetros y que significado tienen? Pues de los datos con los que entrenamos el modelo, por supuesto.
Los parámetros de un modelo se pueden entender como el peso o la influencia que tiene cada una de las características observadas en un fenómeno en la predicción de un nuevo valor, por ejemplo, la edad de una persona, el numero de habitaciones de una vivienda, la presencia de ciertas palabras en un email o el valor de un pixel en una fotografiá a blanco y negro. Algunos ejemplos de algoritmos paramétricos usados en ML son Logistic Regression, SVM y Artificial Neural Networks.
¿Como medir el desempeño de mi modelo?
Una función de pérdida J(x) mide que tan insatisfechos estamos con las predicciones de nuestro modelo con respecto a una respuesta correcta y utilizando ciertos valores de θ. Existen varias funciones de pérdida como el Error cuadrático medio o entropía cruzada y la selección de uno de ellos depende de varios factores como el algoritmo seleccionado o el nivel de confianza deseado, pero principalmente depende de el objetivo de nuestro modelo.
¿Puedo mejorar mi modelo?
El propósito de entrenar un modelo es generar predicciones lo suficientemente “cerca” a la respuesta correcta, es decir, minimizar el error o la insatisfacción, medida con la función de pérdida. Para obtener el mínimo resultado de la función de pérdida se debe encontrar los valores óptimos de θ. Lo anterior, se conoce como optimización y es la columna vertebral de los algoritmos usados en ML y al igual que con la función de pérdida, existen varios métodos de optimización que impactan en el rendimiento de nuestro modelo y el tiempo que toma entrenarlo.
Gradiente Descendente
El algoritmo de gradiente descendiente es un proceso iterativo en el que se ajustan los valores θ, comenzando con valores aleatorios, hasta que se obtiene el mínimo error. El ajuste que se realiza es proporcional al negativo del gradiente (derivada) de la función de pérdida en un punto especifico ∇J(x). Los parámetros se ajustan de manera paralela, es decir, todos los valores se ajustan al mismo tiempo.
θ := θ – α∇J(x)
Dado que el ajuste depende del gradiente, a medida que se acerca a un punto mínimo (gradiente igual a cero) este es cada vez más pequeño. Además del gradiente, se debe definir una tasa de aprendizaje α. Si se elije una tasa muy alta, el proceso puede divergir y no hallar los parámetros óptimos. Si la tasa es muy baja, el entrenamiento del modelo puede tomar mucho tiempo.
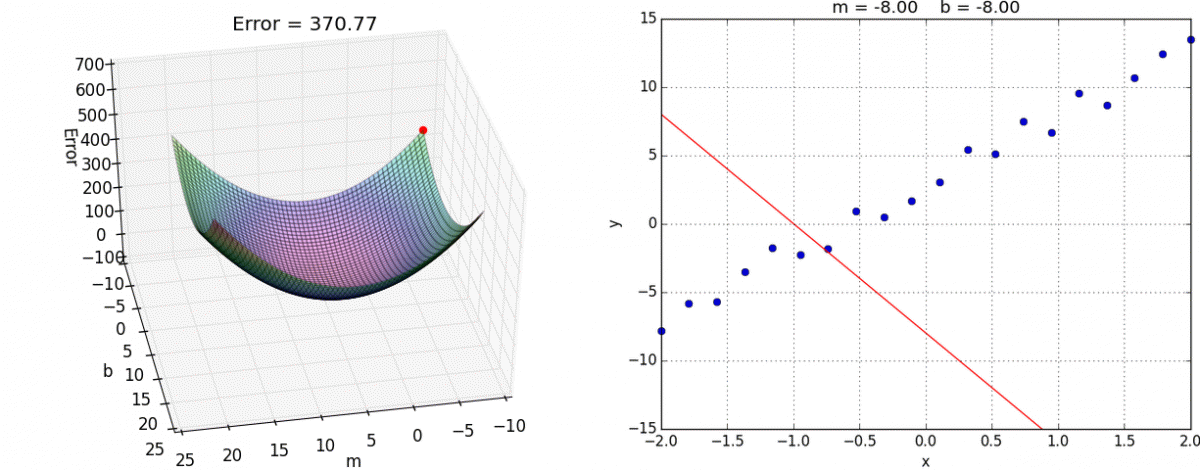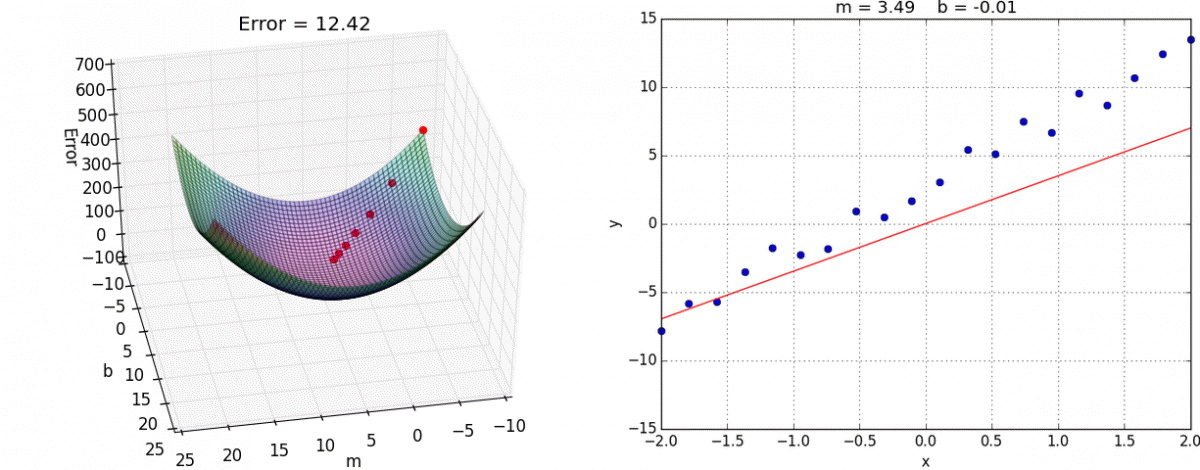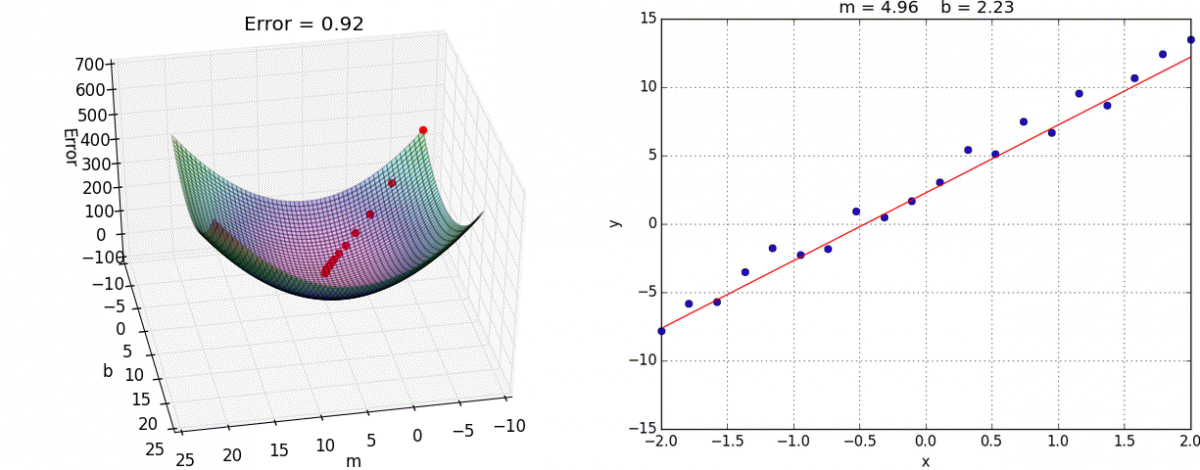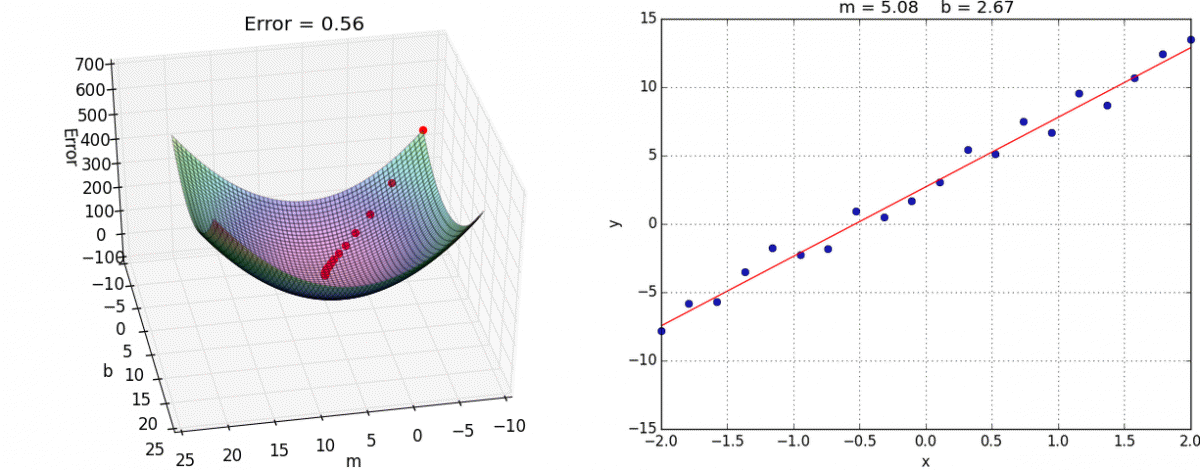
El gradiente descendiente tiene un costo computacional que depende los datos con los que se entrena el modelo. Al incrementar la cantidad de ejemplos y de características, se vuelve más costoso ya que se debe calcular el error de cada ejemplo cada vez que se ajustan los parámetros.
Gradiente Descendiente Estocástico (SGD)
A fin de disminuir el costo computacional del gradiente descendiente se desarrollo el SGD en el cual los parámetros se ajustan con el gradiente de la función de pérdida con cada ejemplo de los datos usados para entrenar el modelo. El termino estocástico hace referencia a que cada ejemplo es escogido o el set es mezclado de manera aleatoria antes de comenzar el entrenamiento. En este caso el numero de pasos en el proceso de optimización, y por lo tanto la cantidad de veces que se calcula el error, es igual al número de ejemplos con los que se entrena el modelo.
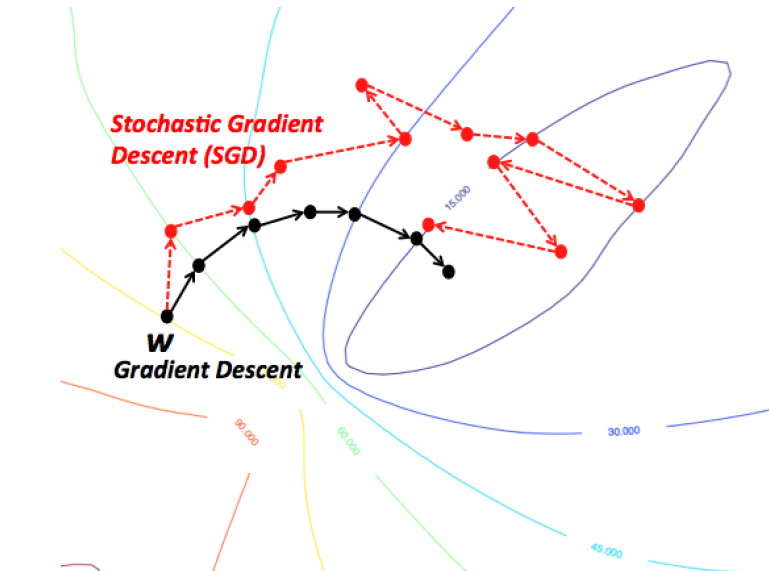
El costo de usar SGD es que no necesariamente se obtienen los valores óptimos de θ, pero dado que es menos exigente computacionalmente, se pueden obtener valores lo suficientemente cercanos para lograr un rendimiento adecuado del modelo.
Conclusión
El concepto de parámetros, función de pérdida y optimización son los principales ingredientes en muchos algoritmos usados en ML. Existen distintas opciones tanto para la función de pérdida y optimización y la decisión de cual usar en una situación especifica están por fuera del alcance de este post, pero serán tocados en mayor profundidad en los siguientes.