

Tu mente sólo sabe algunas cosas. Tu voz interior, tu instinto, lo sabe todo. Si escuchas lo que sabes instintivamente, siempre te llevará por el buen camino. – Henry Winkler
La conciencia es la voz interior que nos avisa de que alguien podría estar mirando. – H. L. Mencken
Los seres humanos no lo comunicamos todo con palabras, y lo que decimos tiene sentido entre líneas. Tanto si se trata de un simpático comentario sarcástico disfrazado de inocente cumplido como si es veladamente una mentira. Depende del lector o del oyente comprender lo que hay más allá del significado de una cadena de palabras juntas.
Gran parte del significado de un texto se esconde entre líneas: sin entender por qué aparecen las afirmaciones en un documento, el lector sólo tiene una comprensión superficial. (fuente)
Los humanos destacamos en la comprensión de estos mensajes ocultos (o al menos la mayoría de nosotros). Los LLM son excelentes a la hora de encontrar patrones en los datos, pero tienen dificultades con los matices del razonamiento o los mensajes implícitos.
En un estudio anterior, los autores crearon un conjunto de datos para la generación de razonamientos y afinaron un modelo sobre este conjunto de datos. Esto se debe a que varios trabajos muestran que el razonamiento intermedio explícito (“rationales”) puede ayudar al modelo a resolver una tarea. Por ello, los autores crearon manualmente este conjunto de datos. Una alternativa a la creación de estos razonamientos es pedir al modelo que cree razonamientos de forma iterativa mediante bootstrap. El proceso es iterativo y se utiliza para refinar las capacidades del modelo:
En concreto, pedimos a un gran modelo lingüístico que autogenere razonamientos y refinamos la capacidad del modelo afinando aquellos razonamientos que conducen a respuestas correctas. Repetimos este procedimiento, utilizando cada vez el modelo mejorado para generar el siguiente conjunto de entrenamiento. (fuente)
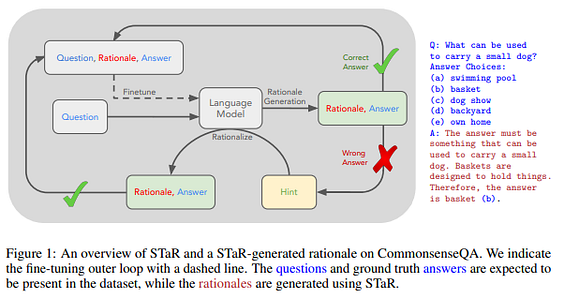
Además del reentrenamiento, este enfoque aprovecha la capacidad de un modelo para aprender del contexto o in-context learning.
Sin embargo, este enfoque tiene limitaciones porque de vez en cuando el modelo sigue sin resolver los problemas porque a veces no encuentra una solución. Para solucionar esto, los autores proponen la racionalización: cuando el modelo falla, generan un nuevo razonamiento proporcionando al modelo la respuesta correcta.
Esto permite al modelo razonar hacia atrás: dada la respuesta correcta, el modelo puede generar más fácilmente un razonamiento útil. Estos razonamientos se recogen entonces como parte de los datos de entrenamiento, lo que a menudo mejora la precisión general. Así, desarrollamos el método del Razonador Autodidacta (STaR, Fig. 1), un método escalable de bootstrapping que permite a los modelos aprender a generar sus propios razonamientos, al tiempo que aprenden a resolver problemas cada vez más difíciles. (fuente)
De este modo, si el modelo responde correctamente, se crean estos razonamientos y si no resuelve se utiliza la racionalización, con lo que finalmente el modelo se afina en este conjunto de datos.
Obviamente, tener que contar con un conjunto de datos de partida limita la generalización y la escala del sistema. Un buen conjunto de datos tiene que ser conservado y sólo cubre un subconjunto de preguntas y temas, además de ser caro. Partiendo de este planteamiento anterior, en un nuevo trabajo los autores pretenden que el modelo genere un razonamiento para que sea capaz de afrontar nuevos retos más allá de los ya vistos.
A grandes rasgos, Quiet-STaR procede generando razonamientos después de cada token para explicar el texto futuro (pensar), mezclando las predicciones del texto futuro con y sin razonamientos (hablar), y luego aprendiendo a generar mejores razonamientos mediante REINFORCE (aprender).
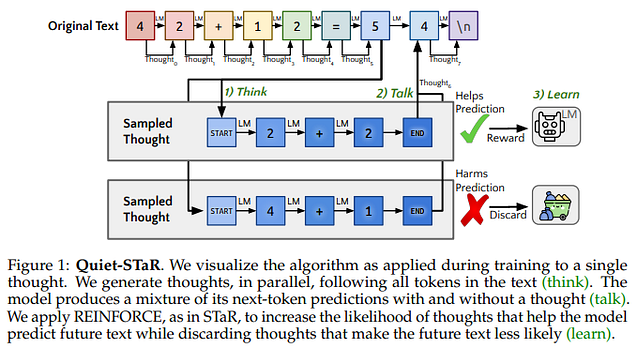
En otras palabras, dotaron al LLM de un monólogo interno.
para introducir el razonamiento (o su capacidad) dentro del modelo. Así, en este caso, el modelo genera pensamientos (racionales) para cada fragmento de texto. La idea es imitar la forma en que razonamos los humanos, en la que hacemos pausas y reflexiones. Los humanos sopesamos las palabras antes de responder (o al menos la mayoría de ellas).
El planteamiento es, por tanto, interesante porque se trata de una especie de autorreflexión. Además, el proceso se optimiza mediante aprendizaje por refuerzo para seleccionar qué pensamientos son más útiles en futuras predicciones de texto. Los resultados demuestran que el modelo obtiene resultados satisfactorios en tareas de razonamiento habituales. Todo ello sin necesidad de una tarea específica de puesta a punto, como se hace con otros modelos. Se trata, de hecho, de un primer paso hacia una aproximación directa al razonamiento universal.
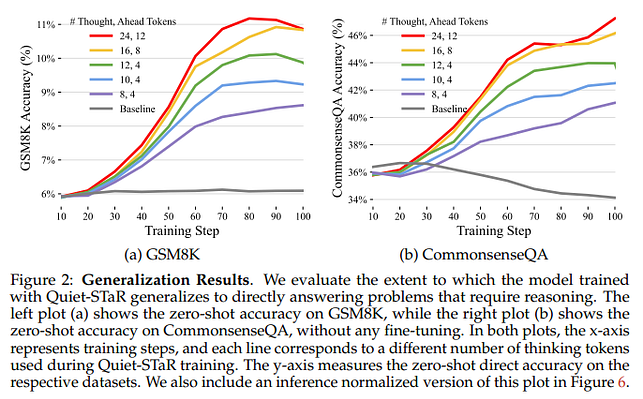
Los resultados pueden no parecer impresionantes porque hay modelos que obtienen mejores resultados en estas pruebas de referencia. Aquí, sin embargo, los autores utilizan un modelo mucho más pequeño (sólo 7B parámetros). ChatGPT y Gemini han fallado espectacularmente en ocasiones con razonamientos comunes, por lo que cabe preguntarse qué ocurriría si se utilizara un enfoque similar con modelos mucho mayores.
Quiet-STaR representa un paso adelante hacia modelos lingüísticos capaces de aprender a razonar de forma general y escalable. Al entrenarse en el rico espectro de tareas de razonamiento implícitas en diversos textos web, en lugar de especializarse estrechamente para conjuntos de datos concretos, Quiet-STaR señala el camino hacia modelos lingüísticos más robustos y adaptables. (fuente)
Así pues, el planteamiento es interesante porque el modelo comprende mejor los matices del texto humano. Esto se debe a un enfoque que se inspira en cómo razonamos los humanos.
Se trata de un paso tanto en la dirección de un modelo que puede aplicar lo que aprende incluso a tareas para las que no ha sido entrenado, como en la de interactuar más eficazmente con nosotros, los humanos.
Tales modelos pueden ser útiles en las interacciones con los humanos; serían más receptivos que el mensaje del texto y garantizarían así una experiencia más atractiva.
Si te ha parecido interesante:
Puedes buscar mis otros artículos, y también puedes conectar o ponerte en contacto conmigo en LinkedIn. Consulta este repositorio con noticias actualizadas semanalmente sobre ML e IA. Estoy abierto a colaboraciones y proyectos y puedes contactar conmigo en LinkedIn.
Aquí está el enlace a mi repositorio GitHub, donde estoy recopilando código y muchos recursos relacionados con el aprendizaje automático, la inteligencia artificial, y más.