

¿Cansado de los viejos sistemas RAG (Generación Aumentada de Recuperación) que hemos tratado ampliamente en otras entradas del blog? Pues yo estoy cansado de ellos. Hagamos algo divertido para llevar las cosas al siguiente nivel. Vamos a repasar la construcción de tus propios sistemas Agentic RAG, introduciendo la idea de agentes en un flujo de trabajo de sistema RAG bien definido.
El año pasado la palabra de moda eran los sistemas RAG, este año las cosas han dado un giro, ahora todo gira en torno a los agentes. Si echas de menos la era de la palabra de moda RAG, no pasa nada porque también podemos introducir agentes en los sistemas RAG. Lo bueno es que es incluso mejor.
En este artículo, repasaremos cómo implementar una aplicación RAG Agentic básica usando Llama-index. Este es el primer artículo de una serie de artículos que publicaré en las próximas semanas sobre arquitecturas RAG Agentic.
Tabla de contenidos
Canal básico de generación mejorada de recuperación (RAG)
Antes de continuar, quiero refrescar un poco cómo es y cómo funciona una arquitectura RAG tradicional. Este conocimiento será útil más adelante y también para los principiantes que no sepan cómo funciona una canalización RAG básica.

De la imagen anterior de un sistema RAG sencillo, tenemos simplemente lo siguiente con lo que trabajamos:
- Documentos: Este es el contexto en el que quieres aumentar tu LLM con información externa que alimenta a un LLM. Puede ser un PDF o cualquier otro documento de texto o incluso imágenes para un LLM multimodal.
- Trozos: El documento más grande se divide en tamaños más pequeños que normalmente se llaman trozos, a veces también llamados nodos.
- Incrustaciones: Una vez que tenemos los trozos de menor tamaño, creamos incrustaciones vectoriales para ellos. Una vez recibida la consulta del usuario, se realiza una búsqueda de similitudes y se recuperan los documentos más parecidos. Estos fragmentos de documento recuperados se envían junto con la consulta del usuario al LLM, y los documentos recuperados actúan como contexto. A partir de ahí, el LLM genera una respuesta.
La explicación anterior es el funcionamiento típico de un sistema tradicional de RAG.
Por qué RAG Agentic
Hemos visto la implementación de una RAG simple desde arriba, este enfoque es adecuado para tareas simples de GC sobre uno o pocos documentos. No es adecuado para tareas complejas de control de calidad y resumen de grandes conjuntos de documentos.
Aquí es donde los agentes pueden entrar en juego, para ayudar a llevar la simple implementación de la RAG a otro nivel. Con los sistemas RAG agénticos, las tareas más complejas, como el resumen de documentos, el control de calidad complejo y muchas otras tareas, pueden llevarse a cabo mucho más fácilmente. Agentic RAG también le ofrece la posibilidad de incorporar llamadas a herramientas en su sistema RAG y estas herramientas pueden ser funciones personalizadas que usted mismo defina.
En esta serie de artículos, repasaremos lo siguiente:
- Motores de consulta de enrutadores: Esta es la forma más simple de un RAG agéntico. Esto nos da la habilidad de añadir sentencias lógicas que pueden ayudar al LLM a decidir sobre qué ruta enrutar una tarea específica dependiendo de la(s) tarea(s) que necesite(n) ser llevada(s) a cabo y del conjunto de herramientas que hayamos puesto a disposición del LLM.
- Llamada a Herramientas: Aquí veremos cómo añadir nuestras propias herramientas personalizadas a la arquitectura agentic RAG. Aquí implementaremos interfaces para que los agentes seleccionen una herramienta de entre un conjunto de herramientas que les proporcionaremos y luego dejaremos que el LLM proporcione los argumentos necesarios que hay que pasar para llamar a estas herramientas, ya que estas herramientas son simplemente funciones de Python, al menos las que tú mismo has definido.
- RAG Agentico con Capacidades de Razonamiento Multipaso
- RAG Agenética con Capacidades de Razonamiento Multipaso con Múltiples Documentos
Motor de consulta del enrutador
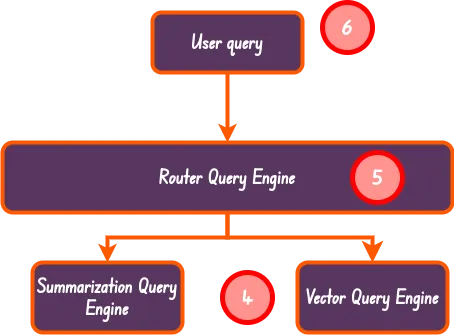
Esta es la forma más simple de RAG agentic, al menos en Llama-index. En este enfoque simplemente tenemos un motor de enrutamiento que, con la ayuda de un LLM, determina qué herramienta o motor de consulta utilizar para abordar una consulta de usuario dada.
Esta es la implementación básica de cómo funciona un motor de consulta de enrutador.

Configuración del entorno del proyecto
Para configurar tu entorno de desarrollo, crea una carpeta llamada agentic_rag, dentro de esta carpeta, crea otra carpeta llamada basics. Una vez hecho esto, navega dentro de la carpeta basics e inicializa un Python Poetry project
$ poetry init
Para empezar, asegúrate de que tienes tu clave API OpenAI lista, puedes obtener tu clave desde aquí si aún no la tienes. Una vez que tengas tu clave api lista, añádela a tu archivo .env:
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Entonces, ¿dónde está este archivo .env? Bueno, he creado una configuración env desarrollo de la siguiente manera:


Sigue esta estructura de directorios y añada sus archivos como se muestra en las imágenes anteriores.
Instalación de paquetes
Usaremos Llama-index para esto. Vamos a instalarlo junto con otras librerías que utilizaremos:
$ poetry add python-dotenv ipykernel llama-index nest_asyncio
Descarga del conjunto de datos
Necesitaremos un archivo PDF para experimentar. Puedes descargar este PDF desde aquí. De nuevo, siéntete libre de utilizar cualquier archivo PDF de su agrado.

Cargar y escupir el documento en los nodos
Ahora estamos listos para empezar, primero vamos a cargar nuestras variables de entorno utilizando la biblioteca python-dotenv que acabamos de instalar:
import dotenv
%load_ext dotenv
%dotenv
También usaremos la biblioteca nest-asyncio ya que Llama-index usa muchas funciones asyncio en segundo plano:
import nest_asyncio
nest_asyncio.apply()
Ahora, carguemos nuestros datos:
from llama_index.core import SimpleDirectoryReader
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=[«./datasets/lora_paper.pdf»]).load_data()
Crear fragmentos de documentos
Una vez que hayamos cargado los datos correctamente, avancemos para dividir el documento más grande en fragmentos de 1024 tamaños de fragmentos:
from llama_index.core.node_parser import SentenceSplitter
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
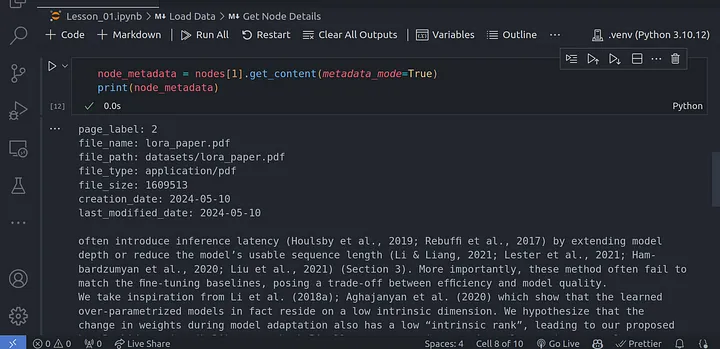
Podemos obtener más información sobre cada uno de estos nodos usando:
node_metadata = nodes[1].get_content(metadata_mode=True)
print(node_metadata)
Creación de LLM e incorporación de modelos
Usaremos el modelo OpenAI gpt-3.5-turbo como LLM y el modelo de incrustación text-embedding-ada-002 para crear las incrustaciones.
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
# LLM model
Settings.llm = OpenAI(model=»gpt-3.5-turbo»)
# embedding model
Settings.embed_model = OpenAIEmbedding(model=»text-embedding-ada-002″)
Creando índices
Como se muestra en las imágenes anteriores, tendremos dos índices principales que usaremos:
- Índice resumido: obtuve esta explicación de los documentos oficiales de Llamaindex:
El índice resumido es una estructura de datos simple donde los nodos se almacenan en una secuencia. Durante la construcción del índice, los textos del documento se fragmentan, se convierten en nodos y se almacenan en una lista.
Durante el tiempo de consulta, el índice de resumen recorre los nodos con algunos parámetros de filtro opcionales y sintetiza una respuesta de todos los nodos.
- Índice vectorial: este es solo un almacén de índice normal creado a partir de incrustaciones de palabras desde el cual podemos realizar búsquedas de similitud para obtener el n índice más similar.
Podemos usar el siguiente código para crear estos dos índices:
from llama_index.core import SummaryIndex, VectorStoreIndex
# summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)
Convertir índices vectoriales en motores de consulta
Una vez que tengamos los índices vectoriales creados y almacenados, tendremos que continuar con la creación de los motores de consulta que convertiremos en herramientas, también conocidas como herramientas de consulta, que nuestros agentes podrán usar más adelante.
# summary query engine
summary_query_engine = summary_index.as_query_engine(
response_mode=»tree_summarize»,
use_async=True,
)
# vector query engine
vector_query_engine = vector_index.as_query_engine()
En el caso anterior, tenemos dos motores de consulta diferentes. Colocaremos cada uno de estos motores de consulta debajo de un motor de consulta de enrutador que luego decidirá a qué motor de consulta enrutar según la consulta del usuario.

En el código anterior, especificamos el parámetro use_async para realizar consultas más rápidas; esta es una de las razones por las que también tuvimos que usar la biblioteca next_asyncio.
Herramientas de consulta
Una herramienta de consulta es simplemente un motor de consulta con metadatos, específicamente una descripción de para qué se puede utilizar o para qué sirve la herramienta de consulta. Esto ayuda al motor de consultas del enrutador a poder decidir a qué herramienta del motor de consultas enrutar dependiendo de la consulta que recibe.
from llama_index.core.tools import QueryEngineTool
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
«Useful for summarization questions related to the Lora paper.»
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
«Useful for retrieving specific context from the the Lora paper.»
),
)
Motor de consulta de enrutador
Finalmente, podemos continuar con la creación de la herramienta del motor de consulta del enrutador. Esto nos permitirá utilizar todas las herramientas de consulta que creamos a partir de los motores de consulta que definimos anteriormente, específicamente summary_tool y vector_tool.
from llama_index.core.query_engine.router_query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelector
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[
summary_tool,
vector_tool,
],
verbose=True
)
LLMSingleSelector: este es un selector que utiliza LLM para seleccionar una única opción de una lista de opciones. Puedes leer más al respecto desde aquí.
Probando el motor de consulta del enrutador
Sigamos adelante y usemos el siguiente código para probar el motor de consulta del enrutador:
response = query_engine.query(«What is the summary of the document?»)
print(str(response))
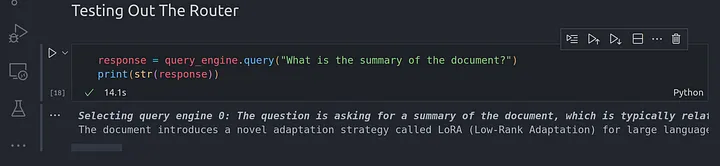
Arriba está el resumen del artículo que se resume en todo el contexto en el documento Lora dado que pasamos al motor de consulta de resumen.
Dado que estamos utilizando el índice de resumen que almacena todos los nodos en una lista secuencial, se visitan todos los nodos y se genera un resumen general de todos los nodos para obtener el resumen final.
Puedes confirmar esto comprobando la longitud de la respuesta, el atributo source_nodes nos devuelve las fuentes utilizadas para generar el resumen.
print(len(response.source_nodes))

Puedes notar que el número 38 es el mismo que el número de nodos que obtuvimos después de realizar la fragmentación del documento. Esto significa que todos los nodos fragmentados se han utilizado para generar el resumen.
Hagamos otra pregunta que no implique el uso de la herramienta de resumen.
response = query_engine.query(«What is the long from of Lora?»)
print(str(response))

Esto utiliza la herramienta de índice de vectores; sin embargo, la respuesta no es tan precisa.
Poniendolo todo junto
Ahora que hemos entendido esta canalización básica, avancemos para convertirla en una función de canalización que llamaremos utilizar más adelante.
async def create_router_query_engine(
document_fp: str,
verbose: bool = True,
) -> RouterQueryEngine:
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=[document_fp]).load_data()
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
# LLM model
Settings.llm = OpenAI(model=»gpt-3.5-turbo»)
# embedding model
Settings.embed_model = OpenAIEmbedding(model=»text-embedding-ada-002″)
# summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)
# summary query engine
summary_query_engine = summary_index.as_query_engine(
response_mode=»tree_summarize»,
use_async=True,
)
# vector query engine
vector_query_engine = vector_index.as_query_engine()
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
«Useful for summarization questions related to the Lora paper.»
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
«Useful for retrieving specific context from the the Lora paper.»
),
)
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[
summary_tool,
vector_tool,
],
verbose=verbose
)
return query_engine
Entonces podemos llamar a esta función de la siguiente manera:
query_engine = await create_router_query_engine(«./datasets/lora_paper.pdf»)
response = query_engine.query(«What is the summary of the document?»)
print(str(response))

Sigamos adelante y creemos un archivo utils.py y tengamos lo siguiente dentro de él:

from llama_index.core.query_engine.router_query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelector
from llama_index.core.tools import QueryEngineTool
from llama_index.core import SummaryIndex, VectorStoreIndex
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import SimpleDirectoryReader
async def create_router_query_engine(
document_fp: str,
verbose: bool = True,
) -> RouterQueryEngine:
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=[document_fp]).load_data()
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
# LLM model
Settings.llm = OpenAI(model=»gpt-3.5-turbo»)
# embedding model
Settings.embed_model = OpenAIEmbedding(model=»text-embedding-ada-002″)
# summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)
# summary query engine
summary_query_engine = summary_index.as_query_engine(
response_mode=»tree_summarize»,
use_async=True,
)
# vector query engine
vector_query_engine = vector_index.as_query_engine()
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
«Useful for summarization questions related to the Lora paper.»
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
«Useful for retrieving specific context from the the Lora paper.»
),
)
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[
summary_tool,
vector_tool,
],
verbose=verbose
)
return query_engine
Luego podremos utilizar esta llamada de función desde este archivo más adelante:
from utils import create_router_query_engine
query_engine = await create_router_query_engine(«./datasets/lora_paper.pdf»)
response = query_engine.query(«What is the summary of the document?»)
print(str(response))

Conclusión
Felicitaciones por llegar hasta aquí. Eso es todo lo que cubriremos en este artículo; en el próximo artículo, veremos cómo usar una llamada de herramienta, también conocida como llamada de función.
Otras plataformas donde puedes comunicarte conmigo:
¡Feliz codificación! Y hasta la próxima, el mundo sigue girando.