
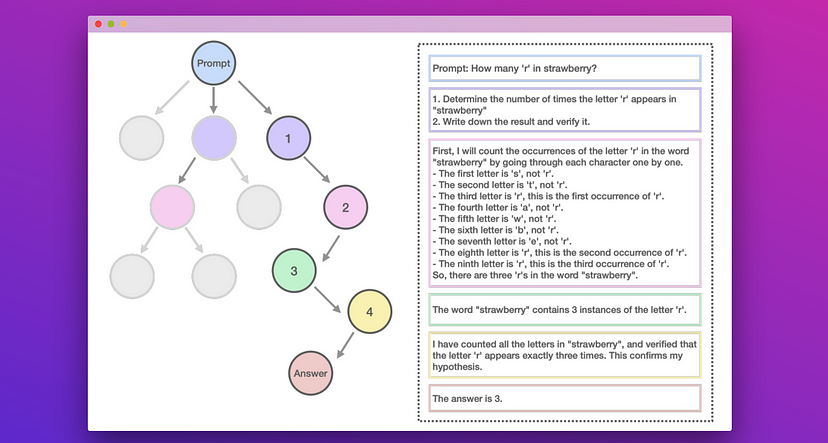
El modelo o1 de OpenAI ha suscitado un gran interés por los grandes modelos de razonamiento (LRM). Aprovechando este impulso, Marco-o1 es un nuevo LRM que se centra en disciplinas estándar como las matemáticas y la codificación, y hace hincapié en las resoluciones abiertas en dominios más amplios.
En concreto, Marco-o1 aborda si el modelo o1 puede generalizarse a dominios que carecen de normas claras y recompensas cuantificables.
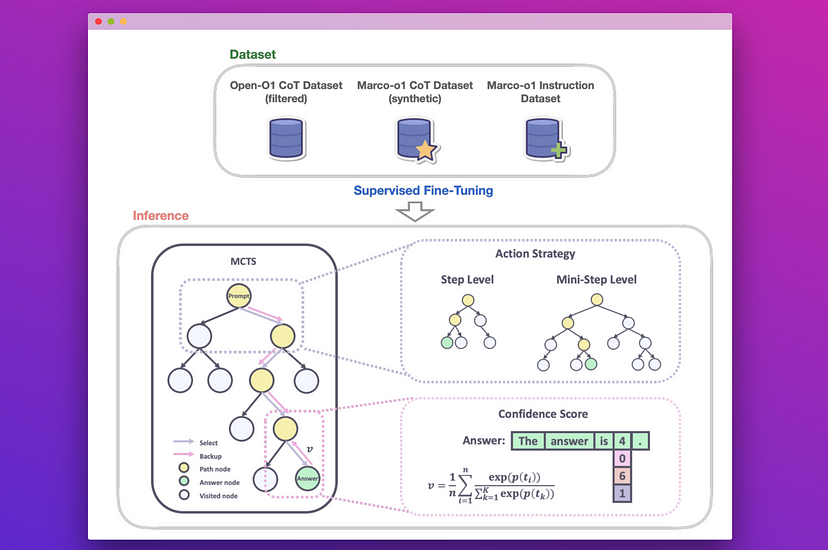
Marco-o1 es un fine-tuning de «Qwen2-7B-Instruct» sobre un conjunto de datos filtrados de Open-O1 CoT, Marco-o1 CoT y Marco-o1 Instruction, con el objetivo de mejorar la gestión de tareas complejas.
Para mejorar aún más el razonamiento, Marco-o1 utiliza la búsqueda en árbol Monte Carlo (MCTS) y otras estrategias de razonamiento innovadoras. En particular, MCTS explora múltiples rutas de razonamiento utilizando puntuaciones de confianza a partir de las probabilidades logarítmicas de los tokens top-𝑘, guiando al modelo hacia mejores soluciones.
Marco-o1 mejoró la precisión en un +6,17% en MGSM (Multilingual Grade School Math) inglés y en un +5,60% en MGSM chino.
Las contribuciones del artículo son:
- Fine-tuning con datos CoT: Los autores desarrollaron Marco-o1-CoT realizando un fina-tuning de todos los parámetros del modelo base utilizando conjuntos de datos CoT de código abierto combinados con nuevos datos sintéticos.
- Expansión del espacio de soluciones mediante MCTS: Los autores integraron LLMs con MCTS (Marco-o1-MCTS), utilizando la confianza de salida del modelo para guiar la búsqueda y expandir el espacio de soluciones.
- Nueva estrategia de acción de razonamiento: Los autores implementaron nuevas estrategias de acción de razonamiento y un mecanismo de reflexión (Marco-o1-MCTS mini-step), explorando diferentes granularidades de acción dentro del marco MCTS e incitando al modelo a la autorreflexión.
Artículos rápidos para mentes curiosas: