

OpenAI acaba de anunciar un nuevo modelo con nuevas e increíbles capacidades de razonamiento. Pero, ¿es realmente así?
Antes de probarlo, mi primera pregunta fue preguntarle a ChatGPT 4o qué piensa:

Pareció tomárselo bien, pero la pregunta ácida que lanza al final, parece abrir la puerta (tal vez) indicando algo de celos hacia su nuevo y brillante hermanito (bienvenido al club querido ChatGPT, incluso a los humanos no les gusta que les digan que la IA es mejor que ellos).
OpenAI ha desvelado su nuevo modelo como un rayo. Los rumores anteriores afirmaban que los próximos modelos costarían bastante, pero por el momento ChatGPT4o1 (Strawberry) parece estar disponible sin recargo.
«Hemos desarrollado una nueva serie de modelos de IA diseñados para pasar más tiempo pensando antes de responder. Pueden razonar sobre tareas complejas y resolver problemas más difíciles que los modelos anteriores en ciencias, codificación y matemáticas» (Fuente)
Al parecer, este modelo es el famoso modelo Strawberry. Ahora no es GPT5, es GPT4 con entrenamiento adicional. Pero para OpenAI, esto representa un paso adicional de inteligencia artificial similar a la humana. Mientras tanto, el modelo está disponible para pruebas tanto en la versión ChatGPT-4o1 como en la versión mini (que supuestamente es más rápida), también está disponible como versión API con algún coste adicional:
«El acceso de los desarrolladores a o1 es realmente caro: en la API, o1-preview cuesta 15 dólares por cada millón de tokens de entrada, o trozos de texto analizados por el modelo, y 60 dólares por cada millón de tokens de salida. En comparación, GPT-4o cuesta 5 dólares por cada millón de tokens de entrada y 15 dólares por cada millón de tokens de salida». (Fuente)
Aunque es más caro, este modelo debería ser mejor que su predecesor. De hecho, lo supera en prácticamente todas las pruebas.
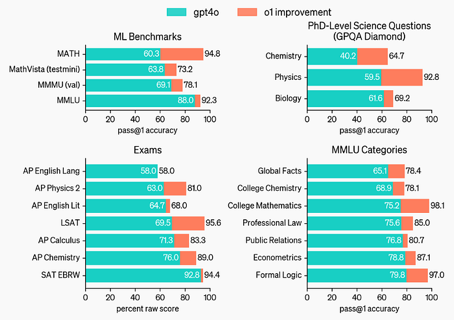
Además, este modelo puede resolver rompecabezas lógicos, problemas matemáticos, etc.
Según los autores, este modelo tiene unas capacidades extraordinarias cuando se trata de tareas que tienen que ver con la planificación. Por ejemplo, el modelo anterior obtuvo un 13% en un examen clasificatorio para la Olimpiada Internacional de Matemáticas, el nuevo modelo alcanzó el 89%. Además, su rendimiento debería ser comparable al de estudiantes de doctorado en tareas de física, biología y química. Un detalle que llamó la atención es que el modelo es capaz de contar el número de erres de la palabra «strawberry» (debido a la tokenización, los anteriores LLM fracasaron en esta tarea que puede parecer trivial a primera vista).
«Para ser claros, o1-preview no lo hace todo mejor. No es mejor escritor que GPT-4o, por ejemplo. Pero para tareas que requieren planificación, los cambios son bastante grandes» (Fuente).

Se lo dije en el 4º ChatGPT, y me respondió con su habitual diplomacia, pero en realidad creo que está encantado.
«Nuestro algoritmo de aprendizaje por refuerzo a gran escala enseña al modelo a pensar de forma productiva utilizando su cadena de pensamiento en un proceso de entrenamiento altamente eficiente con los datos» (Fuente).
En general, este modelo es ChatGPT con RHLF con esteroides. Los autores utilizaron el mismo algoritmo empleado para crear ChatGPT (o al menos una versión más avanzada) en un conjunto de datos propio. Parece que han recopilado una serie de cadenas de pensamiento para problemas matemáticos y de codificación para mejorar las capacidades de razonamiento del modelo. En resumen, gastaron enormes recursos en contratar programadores y crear estas CoT (explicaciones de cómo resolver un problema) sobre las que luego entrenaron el modelo.
Ahora OpenAI es muy bueno en marketing, y han estado hablando durante un tiempo sobre este misterioso nuevo algoritmo Q* que se supone que hace que el modelo sea capaz de razonar. Al parecer, se suponía que era una amenaza para la humanidad, pero hasta ahora parece que no.
De hecho, ya hay una acalorada discusión sobre si es apropiado hablar de razonamiento y pensamiento al describir estos modelos. El CEO de HuggingFace lo dice muy bien:
«Una vez más, un sistema de IA no está «pensando», está «procesando», «ejecutando predicciones»,… igual que hacen Google o los ordenadores. Dar la falsa impresión de que los sistemas tecnológicos son humanos no es más que aceite de serpiente barato y marketing para engañarte y hacerte creer que es más inteligente de lo que es» (Fuente).
Que luego siempre haya una polémica interminable sobre lo que realmente significa razonar es otra cosa. Pero hablar de razonamiento es impropio; al final, detrás de este modelo reluciente, siempre está el buen viejo transformador incapaz de razonar.
Pero al final, ¿es este modelo realmente una amenaza para el ser humano?
No, yo diría que en absoluto. Personalmente, me pareció más frustrante que su predecesor. Hace tiempo que se duda de la eficacia real de los puntos de referencia y del rendimiento real de los LLM en la codificación.
En mi experiencia, este modelo es más lento y parece realizar una serie de pasos innecesarios (no se ven los intermedios de razonamiento, aunque anuncia que está haciendo algo, casi como si fuera una barra de carga a la antigua).

No podemos saber si realmente está haciendo estos pasos de razonamiento o si son sólo una manera de hacer que parezca que el modelo está realmente haciendo algo. En cualquier caso, se bloquea de vez en cuando y hay que hacer que se regenere. Para probarlo, le pedí que resolviera una tarea sencilla de la que incluso su predecesor era incapaz: «Dado un resumen científico, utiliza un modelo huggingface para identificar entidades y extraerlas. A continuación, quiero trazar el texto y resaltar las entidades extraídas con diferentes colores. Dame el código Python«.

Varios intentos después, fracasa estrepitosamente como su predecesor. Tantos intermedios de razonamiento y no pudo encontrar el modelo correcto. Le di el modelo correcto y lo utilizó de forma equivocada.
«Llevamos muchos meses trabajando en el razonamiento porque creemos que éste es realmente el avance crítico» dice McGrew. «Fundamentalmente, se trata de una nueva modalidad de modelos para poder resolver los problemas realmente difíciles que se necesitan para progresar hacia niveles de inteligencia similares a los humanos«, indica. (Fuente).
A mí, de momento, me parece un estudiante que hace muchas muecas y finge pensar en la solución a una pregunta, pero al final dice la respuesta equivocada. Como resultado de esta nueva metodología de entrenamiento, OpenAI afirma que el modelo debería ser más preciso. «Hemos notado que este modelo alucina menos» afirma Tworek. Pero el problema aún persiste. «No podemos decir que hayamos resuelto las alucinaciones» (Fuente).
Las alucinaciones son uno de los principales problemas de los LLM. De hecho, es una de las principales limitaciones del uso de estos modelos en campos sensibles como las finanzas y la medicina. Por eso también han evolucionado sistemas como RAG o GraphRAG.
En resumen, este modelo es significativamente mejor que el anterior en términos de razonamiento y codificación (o al menos en los puntos de referencia). Al mismo tiempo, escribe peor que el anterior, por lo que no debería utilizarse para todas las tareas. La misteriosa Strawberry se alinea finalmente con GPT4 en un conjunto de datos curados donde no sólo hay problemas y soluciones, sino también razonamientos para resolver el problema. El modelo sigue alucinando. Así que es una versión mejorada de su predecesor, sin duda un modelo interesante, pero tampoco sustituirá a los humanos (y seguirá frustrándome cuando le pida que resuelva problemas de codificación).
Referencias
Esta es la lista de las principales referencias que consulté para escribir este artículo, sólo se cita el nombre de un artículo.
- The Verge, OpenAI lanza o1, su primer modelo con capacidades de ‘razonamiento’ (link).
- OpenAI, Presentación de OpenAI o1-preview (link).
- OpenAI, Aprendiendo a razonar con LLMs, link
- Ars Technica, OpenAI’s new «reasoning» AI models are here: o1-preview and o1-mini, link
- Mi propia frustración al probarlo
Si has encontrado esto interesante:
Puedes buscar mis otros artículos, y también puedes conectarte o ponerte en contacto conmigo en LinkedIn. Consulta este repositorio con noticias actualizadas semanalmente sobre ML e IA. Estoy abierto a colaboraciones y proyectos y puedes contactar conmigo en LinkedIn. También puedes suscribirte gratuitamente para recibir notificaciones cuando publique un nuevo artículo.