

Esta es la parte final (4 de 4) de los materiales que preparé para mi clase de Programación con IA. Los artículos anteriores te los comparto a continuación:
En este artículo, voy a explorar cómo utilizar LLMs de visión. En particular voy a analizar cómo los LLMs son capaces de procesar imágenes.
Los LLM de visión son una clase de LLM que se ocupan de algo más que texto y, como su nombre indica, también entienden imágenes. Algunos de los modelos más avanzados, de hecho, entienden más que texto e imágenes, también entienden audio, haciéndolo multimodal. En este artículo sólo me centraré en las imágenes, por lo que el nombre LLM de visión es más adecuado. A veces también se les llama Modelos de Lenguaje de Visión (VLM), pero en este artículo me ceñiré al término LLM de visión.
Los modelos insignia de todos los principales proveedores de LLM actuales son multimodales (incluida la visión), por ejemplo, GPT 4o, Claude 3, Gemini 1.5, etcétera. También existen varios LLM de visión abiertos como Llava 1.6, BakLlava, PaliGemma, Intern-VL, Qwen-VL, etc. En este artículo, repasaré algunos modelos, concretamente GPT 4o, Gemini 1.5 Flash, Llava 1.6 y también variantes de Llava.
Tabla de contenidos
Respuesta visual a preguntas (VQA)
Uno de los casos de uso más comunes para los LLM de visión es la respuesta visual a preguntas. Como su nombre indica, la respuesta visual a preguntas (VQA) permite a los usuarios enviar una imagen y una pregunta sobre la imagen al LLM de visión, que responde con una respuesta.
Veamos un ejemplo de cómo funciona.
En el siguiente fragmento, utilizamos curl para enviar una solicitud JSON a la API REST de finalización de chat de OpenAI. La petición JSON incluye tanto una pregunta como una imagen. Hay dos formas de pasar la imagen a OpenAI:
- Puedes elegir una imagen que ya esté disponible públicamente para que OpenAI pueda acceder a ella a través de una URL.
- Puedes elegir convertir la imagen en una url de datos (esencialmente una versión codificada en base64 de la imagen).
Aquí vamos a utilizar una url de datos.
$ curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What'\''s in this image?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,/9j/4QrMR..." // rest of image
}
}
]
}
],
"max_tokens": 300
}'
Esta es la imagen, un plato de frutas.

Este es el resultado de usar curl para llamar a gpt-4o con la imagen y la pregunta «¿Qué hay en esta imagen?»
{
"id": "chatcmpl-9fNZ3FRq77jSW8RrxVCC7eD4uU3nB",
"object": "chat.completion",
"created": 1719649057,
"model": "gpt-4o-2024-05-13",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The image shows a bowl with a combination of sliced fruits. It contains:\n\n- Sliced cantaloupe melon\n- Sliced honeydew melon\n- Sliced banana\n- Orange slices"
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 777,
"completion_tokens": 38,
"total_tokens": 815
},
"system_fingerprint": "fp_4008e3b719"
}También puedes utilizar un cliente HTTP en un paquete en el lenguaje de programación de tu elección, y luego analizar el JSON. O aún más fácil, podemos utilizar las muchas bibliotecas disponibles para hacer eso.
OpenAI GPT 4o
He aquí un ejemplo de cómo hago esto usando Go con el paquete langchaingo.
func gpt(model string, filepath string, query string) (string, error) {
c := context.Background()
llm, err := openai.New(openai.WithModel(model))
if err != nil {
return "", err
}
dataurl, err := imageurl(filepath)
if err != nil {
fmt.Println("Error reading image file:", err)
return "", err
}
resp, err := llm.GenerateContent(
c, []llms.MessageContent{
{
Role: llms.ChatMessageTypeHuman,
Parts: []llms.ContentPart{
llms.ImageURLPart(dataurl),
llms.TextPart(query),
},
},
},
)
if err != nil {
return "", err
}
return resp.Choices[0].Content, nil
}Primero, genero la url de datos usando la función imageurl. Esta es una función bastante sencilla que toma el archivo, detecta el tipo de contenido, codifica la imagen a base64 y devuelve la url de datos ensamblada.
func imageurl(filepath string) (string, error) {
imageData, err := os.ReadFile(filepath)
if err != nil {
fmt.Println("Error reading image file:", err)
return "", err
}
contentType := http.DetectContentType(imageData[:512])
return "data:" + contentType + ";base64," +
base64.StdEncoding.EncodeToString(imageData), nil
}
func show(filepath string) {
imageData, err := os.ReadFile(filepath)
if err != nil {
fmt.Println("Error reading image file:", err)
return
}
}Luego creo un mensaje para encapsular tanto la url de datos como la pregunta, y se lo paso al GPT 4o.
Ahora veamos los resultados.
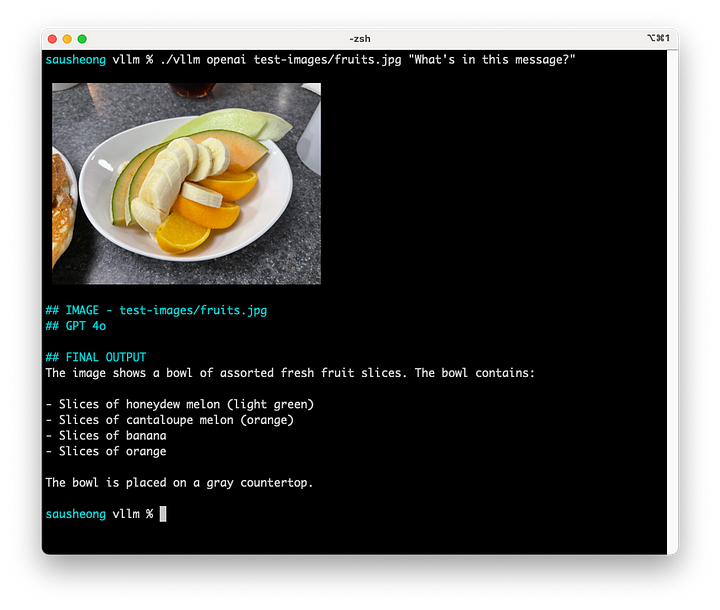
¡Tiene muy buena pinta! Puede detectar no sólo lo que esta foto es, puede decir exactamente lo que las frutas son, e incluso decir que el color de las frutas y también la encimera.
Google Gemini 1.5 Pro
A continuación, vamos a probar Gemini 1.5 Pro de Google. Este es el código, también con langchaingo.
func gemini(model string, filepath string, query string) (string, error) {
c := context.Background()
llm, err := googleai.New(c,
googleai.WithDefaultModel(model),
googleai.WithAPIKey(os.Getenv("GEMINI_API_KEY")))
if err != nil {
return "", err
}
imageData, err := os.ReadFile(filepath)
if err != nil {
fmt.Println("Error reading image file:", err)
return "", err
}
contentType := http.DetectContentType(imageData[:512])
resp, err := llm.GenerateContent(
c, []llms.MessageContent{
{
Role: llms.ChatMessageTypeHuman,
Parts: []llms.ContentPart{
llms.BinaryPart(contentType, imageData),
llms.TextPart(query),
},
},
},
)
if err != nil {
return "", err
}
return resp.Choices[0].Content, nil
}Langchaingo hace que el código sea bastante similar al que usamos en GPT 4o. Sin embargo Gemini no usa urls de datos, en su lugar, tienes que leer los datos binarios y crear una parte binaria y añadirla al mensaje.
Aquí están los resultados.
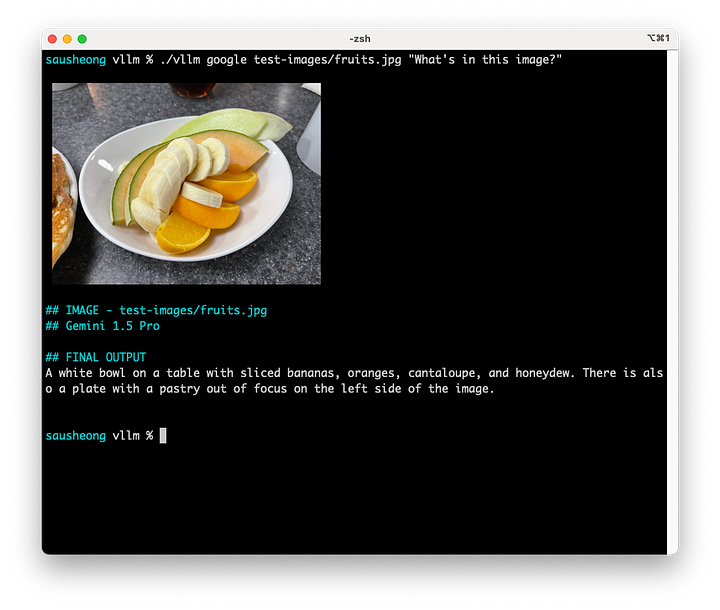
Gemini 1.5 Pro parece un poco más escueta, pero, no obstante, lo ha hecho todo correctamente, ¡incluso el trozo de hojaldre de la izquierda de la imagen!
Llava 1.6
Por último, nos fijamos en el uso de Ollama y un LLM abierto instalado localmente. Hay varios LLM abiertos de visión, pero el más popular es probablemente Llava. Llava (Large Language and Vision Assistant) es un LLM de visión abierto que está basado en CLIP (un codificador de visión) y Vicuna (otro LLM). Hablaremos un poco más sobre CLIP más adelante.
Pero mientras tanto, aquí está el código de langchaingo para llamar a Llava, a través de Ollama.
func local(model string, filepath string, query string) (string, error) {
c := context.Background()
llm, err := ollama.New(ollama.WithModel(model))
if err != nil {
return "", err
}
imageData, err := os.ReadFile(filepath)
if err != nil {
fmt.Println("Error reading image file:", err)
return "", err
}
contentType := http.DetectContentType(imageData[:512])
resp, err := llm.GenerateContent(
c, []llms.MessageContent{
{
Role: llms.ChatMessageTypeHuman,
Parts: []llms.ContentPart{
llms.BinaryPart(contentType, imageData),
llms.TextPart(query),
},
},
},
)
if err != nil {
return "", err
}
return resp.Choices[0].Content, nil
}De nuevo verás que el código es bastante similar. De hecho, este es uno de los puntos fuertes de usar una librería como langchaingo – simplifica ir a múltiples LLMs.
Este es el resultado de usar Llava 1.6.
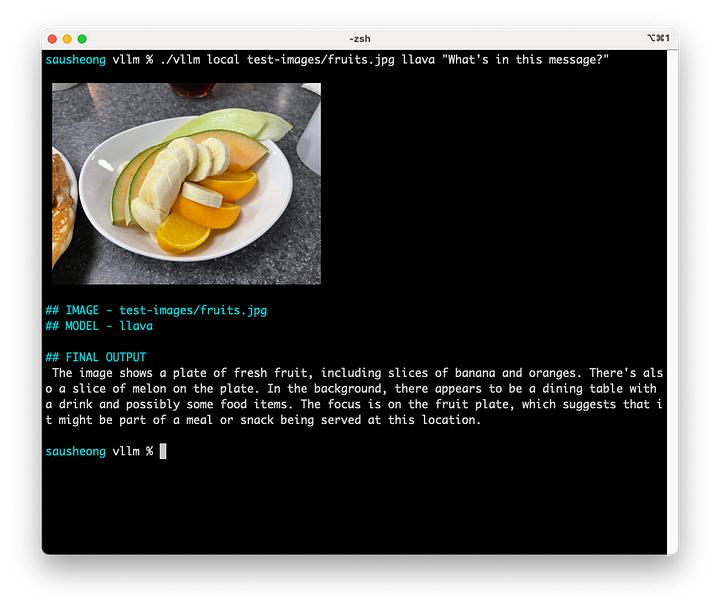
Llava es bastante verborreico, pero no tan preciso. Aunque puede detectar el plátano y la naranja, sólo detectó una rodaja de melón y tampoco nos dijo qué tipo de melón era (a diferencia de GPT 4o).
Como puedes ver, VQA funciona bastante bien con los mejores LLM multimodales, pero el LLM de visión abierta no es tan bueno (aunque no es tan malo).
Otros casos de uso
VQA funciona bastante bien con una pregunta muy genérica como «¿Qué es esta imagen? »Sin embargo, ¿cómo de bien funciona para diferentes casos de uso? En esta sección, exploraremos algunos casos de uso de LLM. Utilizaremos GPT 4o porque es uno de los mejores modelos disponibles.
Detectar, comprender y contar objetos
Empecemos con el plato de frutas de antes. Queremos detectar los tipos de frutas y también contar el número de rodajas.
¿Cuáles son las frutas del plato y cuántas piezas hay de cada tipo de fruta?
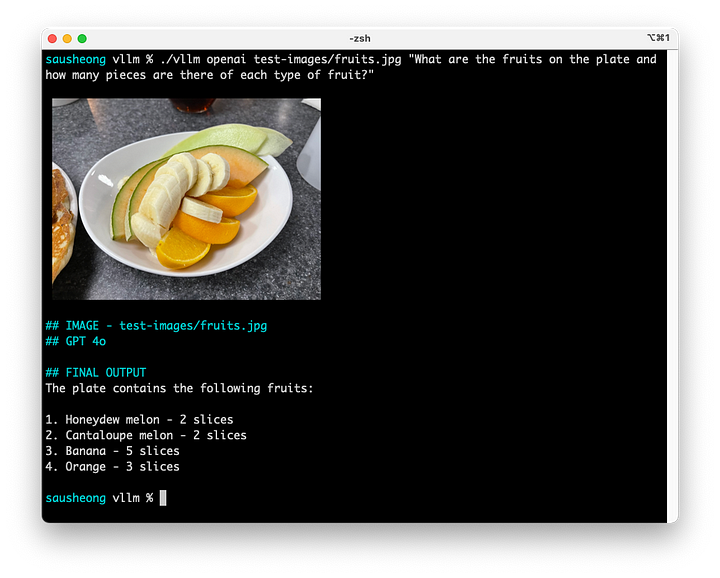
Determinó con precisión los tipos de fruta y el número de piezas, excepto en el caso del plátano (hay 8 piezas).
Tratamiento de recibos
El procesamiento de recibos es un caso de uso muy popular. Este es el recibo de una comida que comí en un viaje a Estados Unidos. La idea es ver si el LLM es capaz de determinar los artículos del recibo y calcular el coste total. Como truco, la propina está en otro recibo y no se indica claramente.

¿Cuánto se gastó en la comida y cuáles fueron los platos? Incluye las propinas.
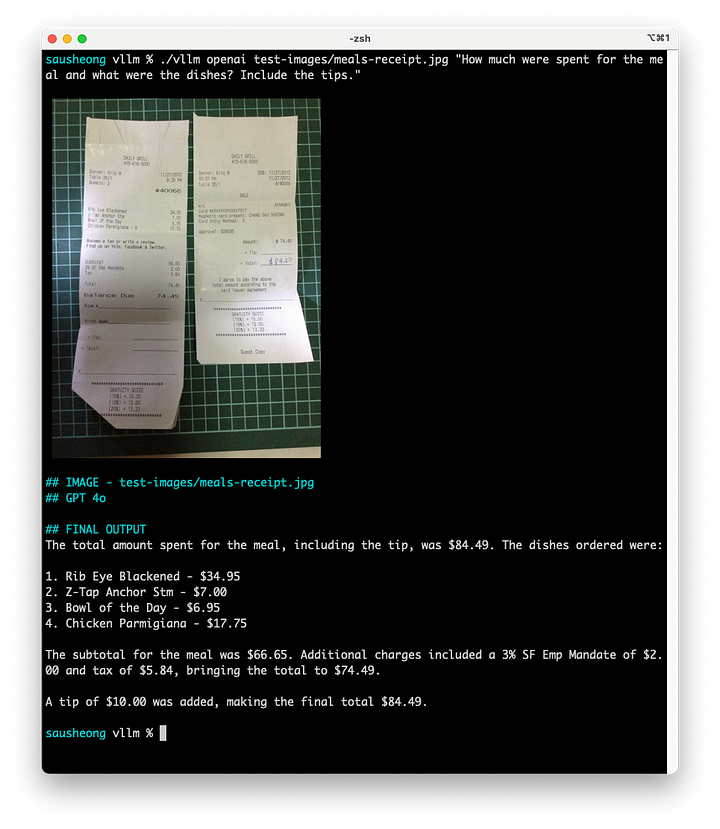
Como puedes ver, la visión LLM puede detectar los artículos y sus costes, el total y también las propinas que se dieron. Incluso puede averiguar que di una propina de 10 dólares restando el coste final del coste de los artículos.
Razonamiento con conocimientos incorporados
Esta es una foto de un paquete de bombones Toblerone de un supermercado cercano. La idea es averiguar si el LLM puede leer la información sobre los ingredientes de los alimentos y razonar con ella. En concreto, quería averiguar si puede decirme que los bombones se consideran alimentos saludables.

¿Qué es y, en función de sus ingredientes, se considera un alimento saludable?

Observa que la imagen no muestra claramente el nombre del producto, y tampoco indica que se trata del producto, pero puede deducirlo a partir de la etiqueta. El LLM puede detectar los ingredientes y a partir de ellos averiguar las implicaciones para la salud de esos contenidos. A partir de las implicaciones también puede deducir si el Toblerone es sano o no y por qué. Es asombroso.
Detectar intenciones y predecir resultados
Los circuitos cerrados de televisión son potencialmente una fuente importante de datos de imágenes para los LLM de visión. Probemos con un caso de uso sencillo.
Se trata de una imagen de un circuito cerrado de televisión que muestra una pelea callejera entre varias personas. La idea es ver si el LLM es capaz de detectar la intención de las personas y predecir lo que va a ocurrir a continuación.

¿Qué está ocurriendo aquí y qué es probable que ocurra a continuación?
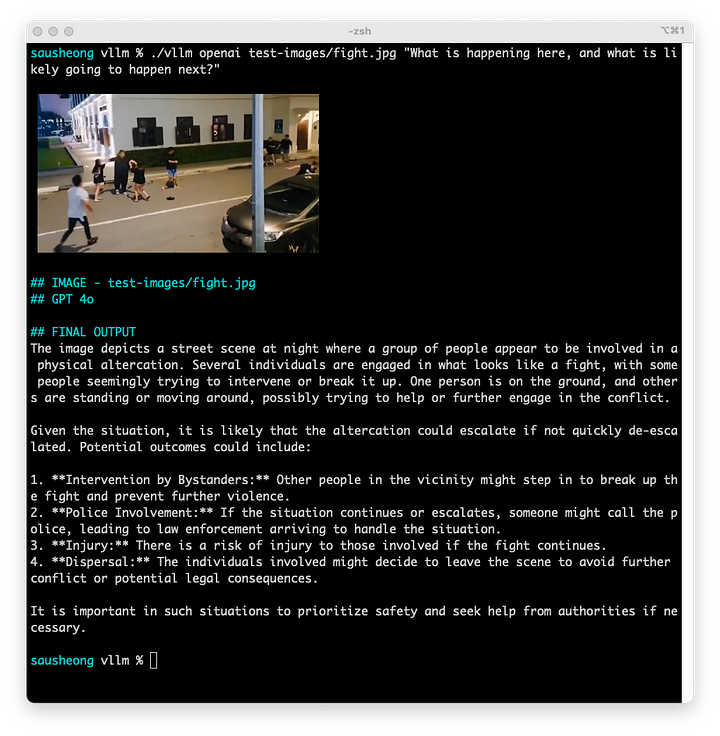
El LLM puede decir claramente que hay un grupo de personas peleándose y también proporciona predicciones de lo que podría ocurrir.
A partir de estos pocos casos de uso, podemos concluir que los LLM de visión más avanzados (por ahora) son bastante buenos procesando imágenes: identificando, contando, razonando e incluso detectando intenciones.
A continuación echaremos un vistazo a otro caso de uso popular para los LLM de visión: encontrar imágenes similares entre sí.
Búsqueda de imágenes
Todos hemos buscado, a través de Google o tu buscador favorito, imágenes, utilizando una descripción textual de la imagen. Incluso hay algunos buscadores de imágenes (o también llamados buscadores inversos) que nos permiten buscar imágenes en función de su similitud con otra búsqueda.
Aunque no estoy al tanto de cómo lo hace Google (u otros motores de búsqueda), es muy fácil reproducir motores de búsqueda de imágenes utilizando LLM de visión. Esto es posible gracias a un LLM de visión llamado CLIP.
CLIP
CLIP (Contrastive Language-Image Pre-training) fue presentado por primera vez por investigadores de OpenAI en el artículo Learning Transferable Visual Models From Natural Language Supervision. Se trata de un LLM de visión que se entrena con una serie de pares imagen/texto y se utiliza a menudo para la comparación de similitudes imagen-texto y para la clasificación de imágenes.
Como se mencionó anteriormente, Llava es un LLM de visión abierto basado en CLIP y Vicuna (otro LLM abierto).
Incrustación de imágenes
Una de las funciones de CLIP es la incrustación de imágenes. Del mismo modo que las incrustaciones de texto son una representación de un fragmento de texto proyectado en un espacio dimensional superior, las incrustaciones de imagen son una representación similar de una imagen.
En este artículo, utilizaré el LLM de visión clip-ViT-B-32 para codificar una imagen en incrustaciones. A diferencia de artículos anteriores en los que utilicé Ollama para interactuar con el LLM, voy a utilizar la biblioteca Sentence Transformers Python para proporcionar las incrustaciones, que serviré como una API a través de Flask. Esto se debe a que, por ahora, Ollama no soporta ningún modelo de incrustación de imágenes.
Este es el servidor API de Flask.
from flask import Flask, request, jsonify
from waitress import serve
from sentence_transformers import SentenceTransformer
from PIL import Image
image_model = SentenceTransformer('./clip-ViT-B-32')
mbed = Flask(__name__)
@mbed.route('/api/image/embeddings', methods=['POST'])
def image():
if 'file' not in request.files:
return "No file part"
file = request.files['file']
embedding = image_model.encode(Image.open(file), convert_to_numpy=True)
return jsonify({'embedding': embedding.tolist()}), 200, {'Content-Type': 'application/json; charset=utf-8'}
if __name__ == '__main__':
print("\033[93mimage embeddings server started. Press CTRL+C to quit.\033[0m")
serve(mbed, port=11333, threads=16)
Veamos cómo obtendremos las incrustaciones de imágenes con Go, con la función getImageEmbeddings.
func getImageEmbeddings(filepath string, filename string) ([]float64, error) {
embeddings := []float64{}
file, err := os.Open(filepath)
if err != nil {
return embeddings, err
}
defer file.Close()
// create a multipart writer
body := &bytes.Buffer{}
writer := multipart.NewWriter(body)
// create the part for a form file
part, err := writer.CreateFormFile("file", filename)
if err != nil {
return embeddings, err
}
// copy the file into the part
_, err = io.Copy(part, file)
if err != nil {
return embeddings, err
}
writer.Close()
// send the file to the server
req, err := http.NewRequest("POST", "http://localhost:11333/api/image/embeddings", body)
if err != nil {
return embeddings, err
}
// send it as multipart form-data
req.Header.Set("Content-Type", writer.FormDataContentType())
client := &http.Client{}
httpResp, err := client.Do(req)
if err != nil {
return embeddings, err
}
// read the response
data, err := io.ReadAll(httpResp.Body)
if err != nil {
return embeddings, err
}
// unmarshal it into an embedding response
resp := &EmbeddingResponse{}
err = json.Unmarshal(data, resp)
if err != nil {
return embeddings, err
}
return resp.Embedding, nil
}Aquí no hay nada del otro mundo, simplemente estamos usando la librería HTTP de la librería estándar de Go y enviando una petición POST a la API de incrustación de imágenes. La petición POST contiene los datos de la imagen. El servidor vuelve con las incrustaciones y nosotros las devolvemos como una porción de float64s.
Incrustaciones de texto
Por supuesto, no podemos prescindir de las incrustaciones de texto, así que también las añadimos en el mismo servidor junto con las incrustaciones de imagen. Ten en cuenta que estamos utilizando el modelo de incrustación de texto all-mpnet-base-v2.
model = SentenceTransformer('./all-mpnet-base-v2')
@mbed.route('/api/text/embeddings', methods=['POST'])
def text():
data = request.json
embedding = image_model.encode(data['prompt'])
return jsonify({'embedding': embedding.tolist()}), 200, {'Content-Type': 'application/json; charset=utf-8'}Así es como podemos obtener las incrustaciones de texto con Go, utilizando la función getTextEmbeddings.
func getTextEmbeddings(prompt string) ([]float64, error) {
embeddings := []float64{}
req := &EmbeddingRequest{
Prompt: prompt,
}
reqJson, err := json.Marshal(req)
if err != nil {
return embeddings, err
}
r := bytes.NewReader(reqJson)
httpResp, err := http.Post("http://localhost:11333/api/text/embeddings", "application/json", r)
if err != nil {
return embeddings, err
}
data, err := io.ReadAll(httpResp.Body)
if err != nil {
return embeddings, err
}
resp := &EmbeddingResponse{}
err = json.Unmarshal(data, resp)
if err != nil {
return embeddings, err
}
return resp.Embedding, nil
}Ahora que disponemos de funciones para obtener las incrustaciones de imagen y texto de una imagen, veamos cómo podemos almacenar estas incrustaciones.
Configuración de la base de datos vectorial
Utilizaremos la base de datos Postgres 16, con la extensión pgvector. Primero, creamos una base de datos llamada imgsearch. Luego ejecutamos esto usando psql en la base de datos imgsearch para añadir la extensión pgvector.
CREATE EXTENSION vector;
Sólo necesitamos 1 tabla para almacenar las incrustaciones.
CREATE TABLE images (
id SERIAL PRIMARY KEY,
filepath varchar(256),
embeddings vector(512)
);
La columna embeddings almacena un vector de tamaño 512, aquí es donde vamos a almacenar los embeddings. La columna filepath apunta a la ubicación del archivo de imagen (o donde quieras almacenarlo).
Insertar las incrustaciones en la base de datos
Ahora que tenemos la tabla para almacenar las incrustaciones, vamos a ir a través de algunos archivos de imagen, crear incrustaciones para ellos y almacenarlos en la base de datos.
Aquí está la función addImage que permite tomar un archivo de imagen, obtener los embeddings de la imagen llamando a getImageEmbeddings, y luego almacenarlos en la base de datos vectorial.
func addImage(filepath string, filename string) error {
ctx := context.Background()
imageEmbeddings, err := getImageEmbeddings(filepath, filename)
if err != nil {
fmt.Println("err in getting embeddings:", err)
return err
}
conn, err := pgx.Connect(ctx, "postgres://localhost/imgsearch")
if err != nil {
return err
}
defer conn.Close(ctx)
var id int
err = conn.QueryRow(ctx, "INSERT INTO images (filepath, embeddings) VALUES ($1, $2) RETURNING id",
filepath, pgvector.NewVector(tof32(imageEmbeddings))).Scan(&id)
if err != nil {
return err
}
return nil
}
// convert float64 slice to float32 slice
func tof32(slice []float64) []float32 {
newslice := make([]float32, len(slice))
var v float64
var i int
for i, v = range slice {
newslice[i] = float32(v)
}
return newslice
}El código es bastante sencillo, sólo tenemos que obtener las incrustaciones de imagen para un archivo, a continuación, almacenar la ruta del archivo y las incrustaciones en la tabla. Ten en cuenta que tenemos que utilizar el paquete pgvector para convertir la rebanada de float32s antes de almacenarlo en la tabla.
Ahora podemos llamar a addImage para cada imagen que queramos almacenar en imgsearch. Aquí está la tabla de imágenes después de añadir algunas imágenes.
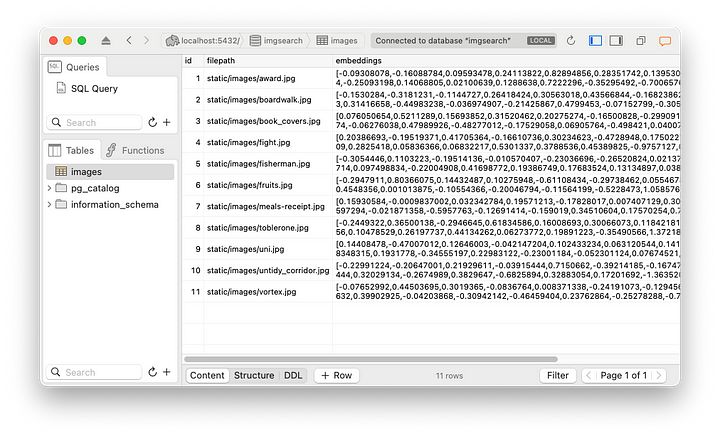
Esto es todo el trabajo preliminar que teníamos que hacer. Veamos cómo podemos buscar la imagen más parecida, dada una imagen.
Encontrar la imagen más parecida a otra imagen
Encontrar la imagen más parecida a la imagen dada es fácil con las incrustaciones de imágenes.
func getMostSimiliarImageByImage(filepath string, filename string)
(string, error) {
ctx := context.Background()
conn, err := pgx.Connect(ctx, "postgres://localhost/imgsearch")
if err != nil {
return "", err
}
defer conn.Close(ctx)
imageEmbeddings, err := getImageEmbeddings(filepath, filename)
if err != nil {
return "", err
}
rows, err := conn.Query(ctx,
"SELECT id, filepath, (1 - (embeddings <=> $1)) as cosine_distance "+
"FROM images ORDER BY cosine_distance DESC LIMIT 3",
pgvector.NewVector(tof32(imageEmbeddings)))
if err != nil {
return "", err
}
defer rows.Close()
filepaths := []string{}
for rows.Next() {
var id, path string
var distance float64
err = rows.Scan(&id, &path, &distance)
if err != nil {
return "", err
}
filepaths = append(filepaths, path)
}
if rows.Err() != nil {
return "", err
}
return filepaths[0], nil
}
En primer lugar, obtenemos las imágenes incrustadas de la imagen cargada. A continuación, buscamos en la base de datos vectorial la imagen incrustada que tenga la menor distancia coseno de la que obtuvimos de la imagen cargada.
Esto se hace utilizando una única sentencia SQL SELECT.
SELECT id, filepath, (1 - (embeddings <=> $1)) as cosine_distance
FROM images ORDER BY cosine_distance DESC LIMIT 3
El parámetro $1 son, por supuesto, las incrustaciones de nuestra imagen subida. Una vez que tenemos las filas devueltas, podemos extraerlas en las variables respectivas y devolvemos la primera imagen, puesto que ya han sido ordenadas. Por supuesto, si quieres devolver más de 1 imagen también está bien.
Veamos cómo funciona esto. Digamos que subimos esta imagen.
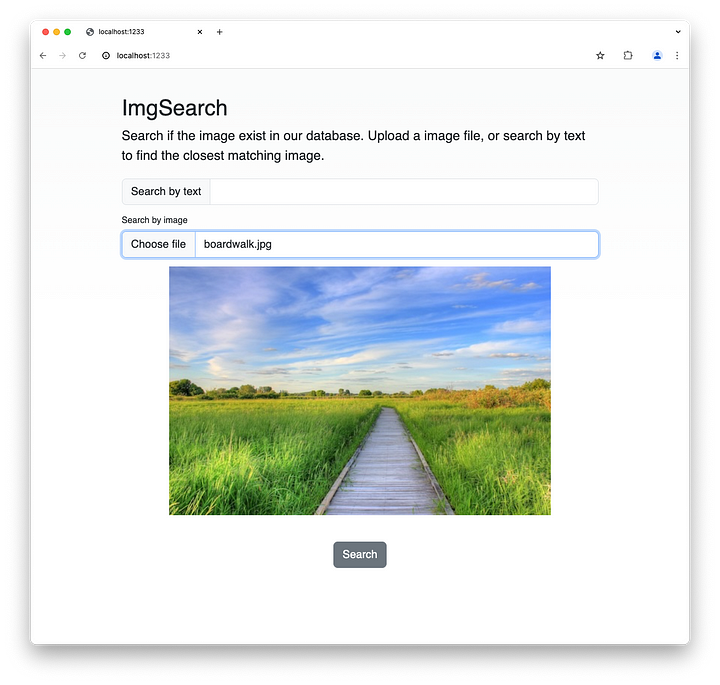
Cuando hacemos clic en Buscar, podemos encontrar la imagen que mejor se adapte a la que has subido.
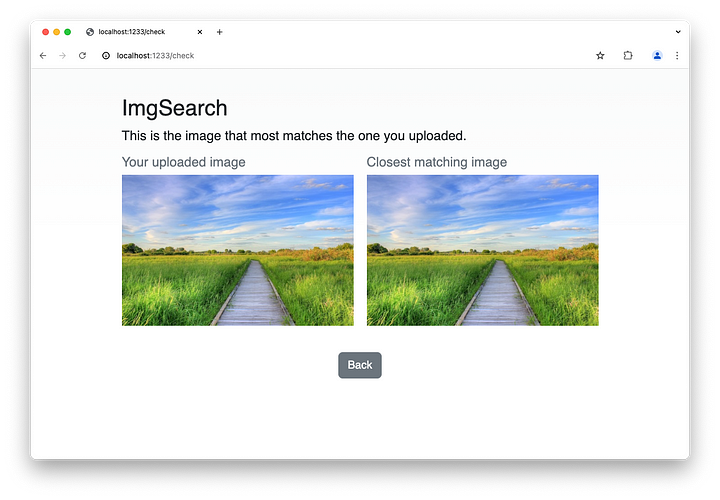
Eso es todo para las imágenes, vamos a ver cómo podemos encontrar imágenes con entrada de texto.
Encontrar la imagen más parecida con la entrada de texto
Aquí está la función getMostSimilarImageByText, que puede parecerte familiar ya que es muy parecida a la función getMostSimiliarImageByImage anterior.
func getMostSimiliarImageByText(prompt string) (string, error) {
ctx := context.Background()
conn, err := pgx.Connect(ctx, "postgres://localhost/imgsearch")
if err != nil {
return "", err
}
defer conn.Close(ctx)
textEmbeddings, err := getTextEmbeddings(prompt)
if err != nil {
return "", err
}
filepaths := []string{}
rows, err := conn.Query(ctx,
"SELECT id, filepath, (1 - (embeddings <=> $1)) as cosine_distance "+
"FROM images ORDER BY cosine_distance DESC LIMIT 10",
pgvector.NewVector(tof32(textEmbeddings)))
if err != nil {
return "", err
}
defer rows.Close()
for rows.Next() {
var id, path string
var distance float64
err = rows.Scan(&id, &path, &distance)
if err != nil {
return "", err
}
filepaths = append(filepaths, path)
}
if rows.Err() != nil {
return "", err
}
return filepaths[0], nil
}En primer lugar, obtenemos las incrustaciones de texto de la solicitud mediante getTextEmbeddings. Después, como antes, ejecutamos una consulta SQL en la base de datos imgsearch para encontrar los archivos de imagen.
Si no estás muy familiarizado con CLIP, puede que te sorprenda un poco por qué funciona esto. Recuerde que CLIP (que utilizamos para crear las incrustaciones de imágenes) se entrena con pares imagen/texto. Por tanto, las incrustaciones también reflejan el texto asociado a la imagen. Si lo piensas, esto es similar a la visión anterior LLMs que es capaz de obtener el contenido del texto asociado a la imagen dada.
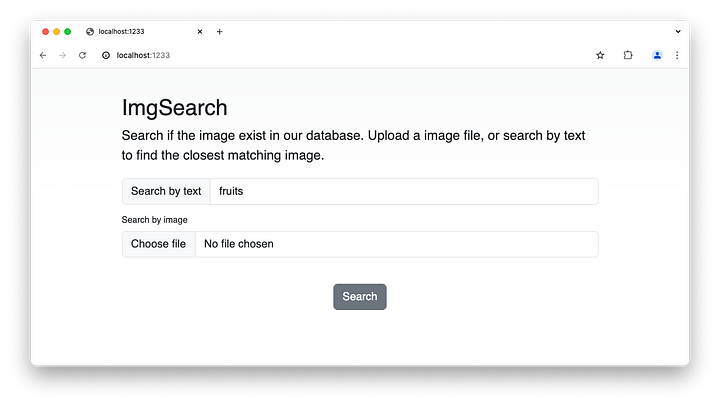
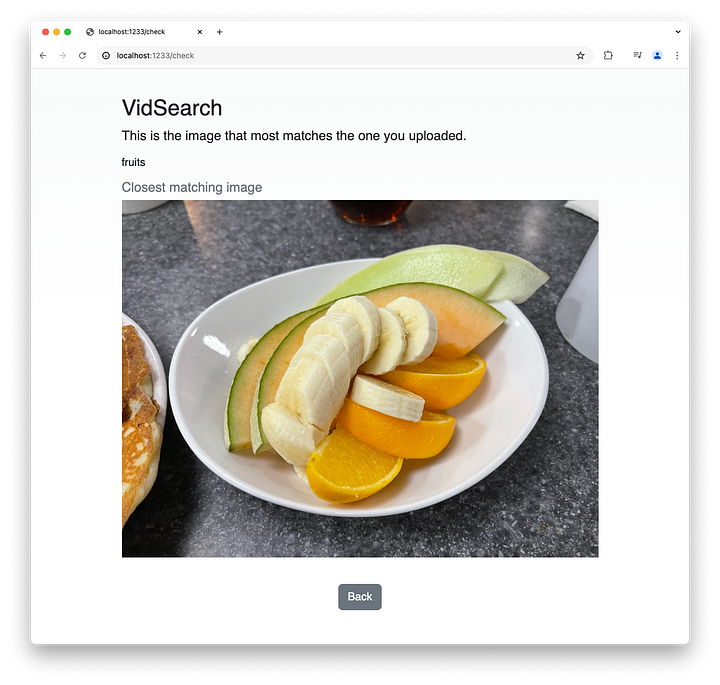
Veámoslo en acción. Busquemos una imagen con una sola palabra: frutas.
Recuerda que las imágenes no están etiquetadas y no hay metadatos asociados a ellas. Este es el resultado de la búsqueda.
Aquí tienes un vídeo para verlo mejor. Te sorprenderá la velocidad de la búsqueda. Por supuesto, sólo hay muy pocos registros en la base de datos, pero también hay muy poco procesamiento necesario para la búsqueda, y por lo tanto es rápido.
Ahora que ya podemos hacer búsquedas en imágenes, ¡vamos a dar el siguiente paso para buscar en vídeos!
Búsqueda de vídeos
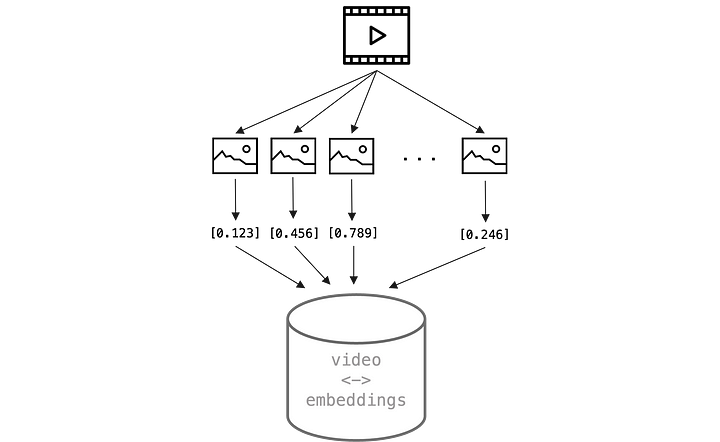
Un vídeo no es más que una serie de fotogramas mostrados uno tras otro, con audio añadido. Si sólo nos ocupamos de la parte visual de un vídeo, podemos descomponerlo en un gran número de imágenes.
Esto hace que todo el proceso sea muy similar al que realizamos para la búsqueda de imágenes. Sin embargo, a menos que se trate de vídeos muy cortos, habrá un gran número de fotogramas y la mayoría de ellos serán redundantes de todos modos. Así que en lugar de obtener incrustaciones para cada imagen, sólo tomamos los fotogramas en un momento determinado y los utilizamos para crear las incrustaciones de imagen.
Configuración de la base de datos vectorial
Podemos almacenar los fotogramas (imágenes) y las incrustaciones en la base de datos vectorial como antes, pero hay una diferencia, necesitamos agrupar los fotogramas como un vídeo. Por lo tanto necesitamos tener 2 tablas – vídeos y fotogramas.
CREATE TABLE videos (
id SERIAL PRIMARY KEY,
title varchar(256),
filepath varchar(256),
);
CREATE TABLE frames (
id SERIAL PRIMARY KEY,
video_id int NOT NULL REFERENCES videos,
embeddings vector(512)
);
La tabla de fotogramas tiene una clave externa asociada a las tablas de vídeos, de forma que podemos asociar varios fotogramas a un único vídeo. Cada fila de la tabla de vídeos corresponde a un archivo de vídeo, por lo que almacenamos también la ruta a ese archivo.
Añadir fotogramas en la tabla de fotogramas es muy similar a añadir imágenes en la tabla de imágenes.
func addFrame(ctx context.Context, conn *pgx.Conn, frame Frame) error {
_, err := conn.Exec(ctx, "INSERT into frames (video_id, embeddings) VALUES ($1, $2)",
frame.VideoId, pgvector.NewVector(tof32(frame.Embeddings)))
return err
}
// convert float64 slice to float32 slice
func tof32(slice []float64) []float32 {
newslice := make([]float32, len(slice))
var v float64
var i int
for i, v = range slice {
newslice[i] = float32(v)
}
return newslice
}A continuación, la función addVideo llama a la función addFrame para crear las asociaciones.
func addVideo(video Video) error {
ctx := context.Background()
videoEmbeddings, err := getEmbeddingsFromVideo(video.Filepath)
if err != nil {
return err
}
conn, err := pgx.Connect(ctx, "postgres://localhost/vidsearch")
if err != nil {
return err
}
defer conn.Close(ctx)
var id int
err = conn.QueryRow(ctx, "INSERT INTO videos (title, filepath) VALUES ($1, $2) RETURNING id",
video.Title, video.Filepath).Scan(&id)
if err != nil {
return err
}
for _, frameEmbeddings := range videoEmbeddings {
frame := Frame{
VideoId: id,
Embeddings: frameEmbeddings,
}
addFrame(ctx, conn, frame)
}
return nil
}Esta es la tabla de fotogramas después de añadir varios vídeos.
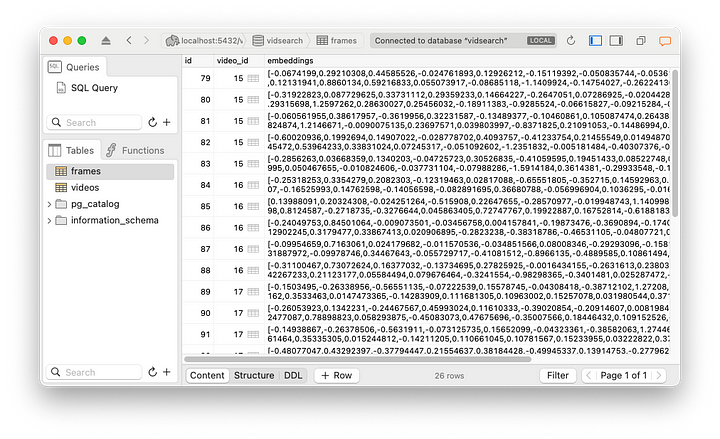
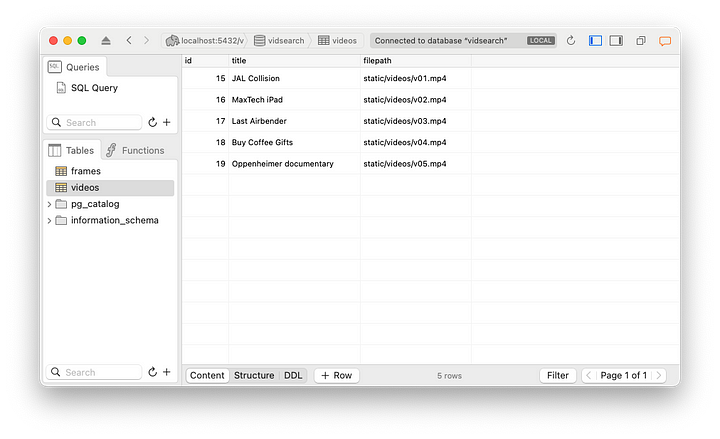
Y aquí está la tabla de vídeos que muestra esos vídeos.
Ahora que tenemos nuestras incrustaciones, podemos empezar a buscar un vídeo basado en otro vídeo.
Encontrar el vídeo más similar con otro vídeo
Echemos un vistazo a la función que nos ayuda a encontrar el vídeo más similar, dado otro vídeo.
func getMostSimiliarVideoByVideo(filepath string) (Video, error) {
video := Video{}
ctx := context.Background()
conn, err := pgx.Connect(ctx, "postgres://localhost/vidsearch")
if err != nil {
return video, err
}
defer conn.Close(ctx)
videoEmbeddings, err := getEmbeddingsFromVideo(filepath)
if err != nil {
return video, err
}
videoIds := []int{}
for _, embeddings := range videoEmbeddings {
rows, err := conn.Query(ctx,
"SELECT id, video_id, (1 - (embeddings <=> $1)) as cosine_distance "+
"FROM frames ORDER BY cosine_distance DESC LIMIT 3",
pgvector.NewVector(tof32(embeddings)))
if err != nil {
return video, err
}
defer rows.Close()
// var frames []Frame
for rows.Next() {
var frame Frame
var distance float64
err = rows.Scan(&frame.Id, &frame.VideoId, &distance)
if err != nil {
return video, err
}
// frames = append(frames, frame)
videoIds = append(videoIds, frame.VideoId)
}
if rows.Err() != nil {
return video, err
}
}
videoId := most(videoIds)
video, err = getVideoFromId(ctx, conn, videoId)
if err != nil {
return video, err
}
return video, nil
}Estos son los pasos:
- Obtener las incrustaciones asociadas a un vídeo
- Para cada una de las incrustaciones (recuerde que en realidad son incrustaciones de los fotogramas de la imagen dentro del vídeo) encontramos las incrustaciones más cercanas (y por lo tanto el fotograma) en la base de datos vectorial.
- A partir del fotograma obtenemos el vídeo asociado al fotograma
- Hacemos esto para los fotogramas del vídeo de entrada (recuerda que no tomamos todos los fotogramas, sólo algunas muestras)
- De la lista de vídeos que encontramos asociados a los fotogramas devueltos, buscamos el que aparece con más frecuencia, y ese sería el vídeo más similar.
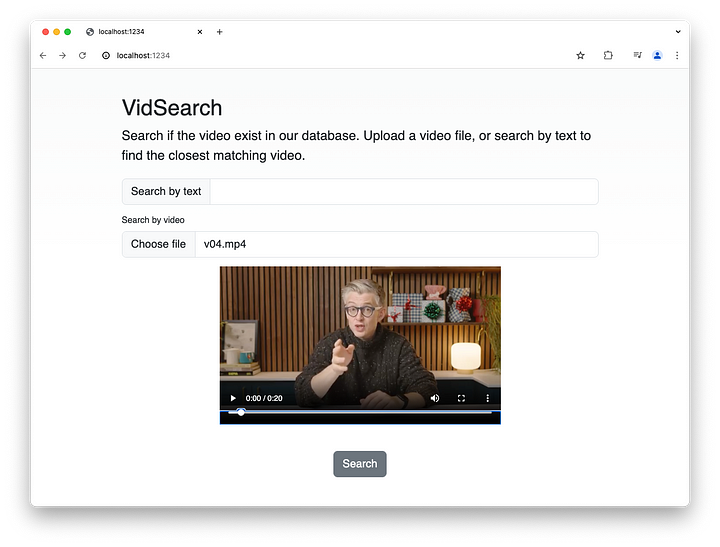
Así es como funciona en acción. Empezamos eligiendo un vídeo corto y pulsando el botón Buscar:
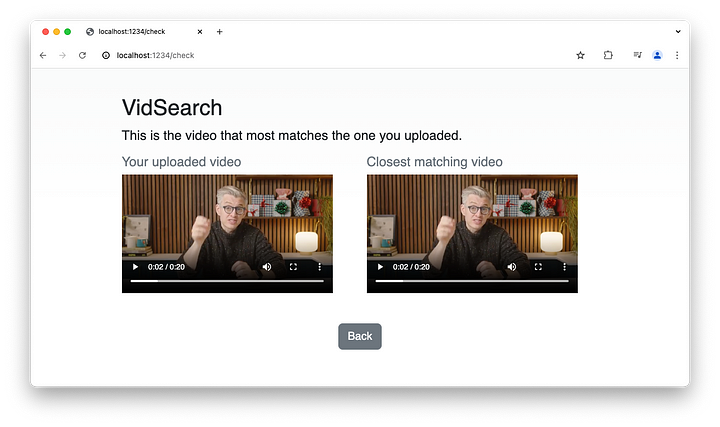
Este es el vídeo que devuelve:
Encontrar el vídeo más similar a partir de texto
Vamos a hacer lo mismo con el texto, que ya debería resultarte muy familiar:
func getMostSimiliarVideoByText(prompt string) (Video, error) {
video := Video{}
ctx := context.Background()
conn, err := pgx.Connect(ctx, "postgres://localhost/vidsearch")
if err != nil {
return video, err
}
defer conn.Close(ctx)
textEmbeddings, err := getTextEmbeddings(prompt)
if err != nil {
return video, err
}
videoIds := []int{}
rows, err := conn.Query(ctx,
"SELECT id, video_id, (1 - (embeddings <=> $1)) as cosine_distance "+
"FROM frames ORDER BY cosine_distance DESC LIMIT 10",
pgvector.NewVector(tof32(textEmbeddings)))
if err != nil {
return video, err
}
defer rows.Close()
// var frames []Frame
for rows.Next() {
var frame Frame
var distance float64
err = rows.Scan(&frame.Id, &frame.VideoId, &distance)
if err != nil {
return video, err
}
// frames = append(frames, frame)
videoIds = append(videoIds, frame.VideoId)
}
if rows.Err() != nil {
return video, err
}
videoId := most(videoIds)
video, err = getVideoFromId(ctx, conn, videoId)
if err != nil {
return video, err
}
return video, nilLos pasos también son los mismos que en el uso de una entrada de vídeo, así que no me repetiré. Así es como funciona.
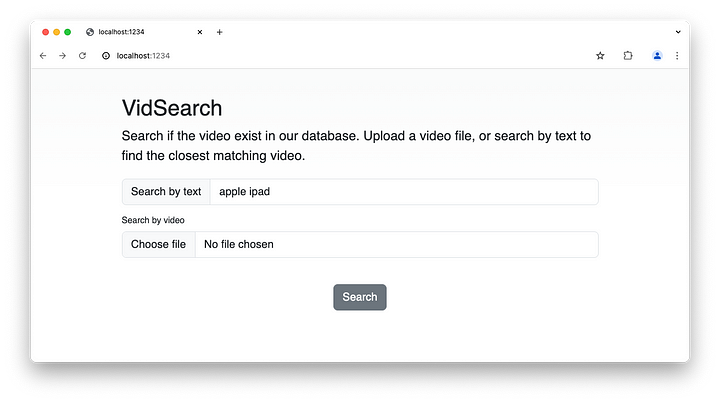
Aquí está el vídeo generado. Como antes, no hay metaetiquetas asociadas a los vídeos y toda la información que se utilizó fue únicamente el texto y las imágenes incrustadas.
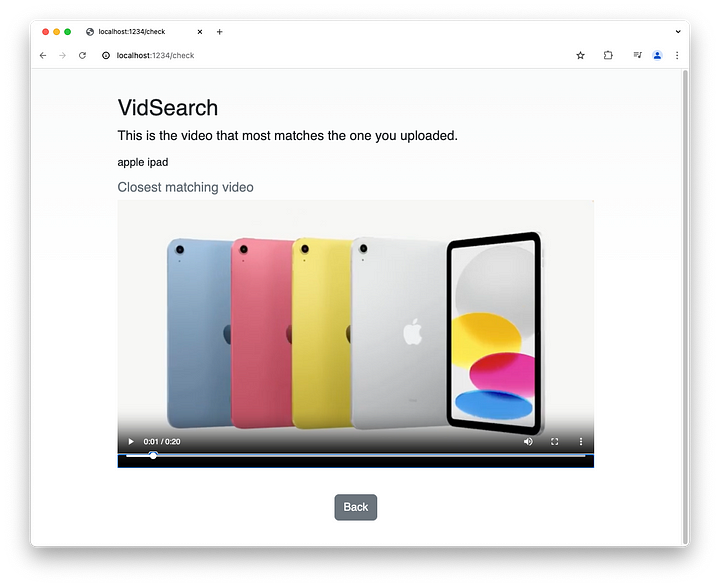
Por último, aquí tienes un vídeo del buscador de vídeos por el que acabamos de pasar:
Resumen
En este artículo, hablé de los LLM de visión, un LLM que puede procesar tanto texto como imágenes. Repasamos la respuesta a preguntas visuales con varios LLMs de visión incluyendo GPT 4o, Gemini 1.5 Pro y Llava 1.6.
También probamos otros casos de uso, como la detección, comprensión y recuento de objetos, el procesamiento de recibos, el razonamiento con conocimientos incorporados y la detección de intenciones y predicción de resultados.
A continuación, analizamos las incrustaciones de imágenes y mostramos un ejemplo de uso de incrustaciones de imágenes para la búsqueda de imágenes. Por último, ampliamos la idea de la búsqueda de imágenes a la búsqueda de vídeos, considerando que los vídeos no son más que una serie de fotogramas de imágenes encadenados.
Este es el último artículo de la serie Programación con IA. Aunque fue escrito principalmente para los participantes de mi clase sobre Programación con IA, espero que hayas aprendido algo de él también si no fuiste uno de ellos.