

Esta es la segunda parte de los materiales (2 de 4) que creé para una clase sobre programación con grandes modelos de lenguaje (LLMs). En el artículo anterior, compartí acerca de las diferentes formas en que podemos acceder a proveedores de IA remotos como OpenAI, Google, Anthropic, etc. En este artículo, nos adentraremos en los LLM de código abierto.
Disclaimer: aquí utilizo el término LLM abierto con bastante libertad y me centro principalmente en la tecnología más que en la «apertura» de los modelos. Para un análisis más profundo de este debate en curso, te sugiero este artículo.
Los LLM abiertos son grandes modelos lingüísticos que puedes descargar y ejecutar en tu servidor o en tu propio ordenador portátil y que puedes controlar por completo. En algunas publicaciones, también se les llama LLM offline, haciendo hincapié en el hecho de que se pueden utilizar completamente sin conexión si los estás desplegando en tu propio entorno.
Aunque la mayoría de los LLM que están disponibles para su descarga suelen afirmar que son de código abierto, la verdad es mucho más matizada que eso. Algunos tienen el código fuente disponible, pero otros no. Algunos proporcionan sus ponderaciones libremente, otros no. Algunos proporcionan los conjuntos de datos y explican cómo se entrena el LLM, otros no. En general, la mayoría permite el uso gratuito del LLM, pero con ciertas condiciones, entre las que se incluye su uso exclusivo con fines de investigación. En este artículo, utilizo el término LLM abierto para referirme a cualquier cosa que no sea un LLM de código cerrado como GPT-4 o Gemini.
No obstante, los LLM abiertos son una bendición para muchos porque son una alternativa real a los proveedores comerciales de código cerrado como OpenAI, Anthropic, Google, etc. Algunos de los más populares hasta la fecha son Llama de Meta, Mistral de Mistral AI, Falcon de TII, Gemma de Google, Phi de Microsoft, etc. (desafortunadamente, todos ellos no son totalmente abiertos). En este artículo, utilizaré principalmente el modelo Llama 3 de Meta, en particular su modelo Llama-3-8B-Instruct.
Llama 3 es la tercera iteración del modelo Llama de Meta AI, con la primera versión lanzada hace sólo 16 meses, en febrero de 2023, seguida de una segunda versión en julio de 2023. Llama 3 se lanzó hace apenas 2 meses, en abril de 2024.
Para utilizar Llama 3, tienes que solicitar el acceso a Meta. Esto suele llegar en unas pocas horas. Si acabas de leer esto y quieres probar algunas de las cosas que vienen a continuación, te sugiero que hagas una pausa aquí y rellenes el formulario y hagas la solicitud antes de seguir leyendo. Alternativamente, si realmente prefieres no hacerlo, también puedes utilizar otro LLM como el Phi-3-mini-4k-instruct de Microsoft.
Tabla de contenidos
Despliegue de LLM abiertos
En términos generales, hay dos formas de desplegar tus propios LLM abiertos:
- Como una API a ser llamada por una aplicación LLM
- Como componente integrado, parte de una aplicación LLM
Hay muchas variaciones de lo anterior, pero aquí hay algunas comunes:
- Desplegar el LLM en una nube comercial como Google Cloud o AWS, utilizando sus servicios de alojamiento de modelos de terceros como Model Garden de Google Cloud o Bedrock de AWS.
- Despliega el LLM en un servicio especializado de alojamiento de modelos como Replicate o Banana
- Desplegar el LLM en una instancia en la nube (o incluso en un servidor de metal desnudo) directamente, con o sin GPU.
- Despliega el LLM en un entorno local utilizando un servicio como llama.cpp, Ollama o KoboldCpp, y llama a las APIs desde allí.
- Integrar el LLM en una aplicación LLM que se ejecute en un escritorio.
En este artículo, no voy a discutir la ruta de proveedor de nube comercial (primer punto). Más bien, voy a ir a través de algunas alternativas populares para el despliegue como una API o como un componente integrado.
Permíteme comenzar con la fuente de la mayoría de los LLM abiertos – Huggingface.
Huggingface 🤗
Huggingface es una empresa de tecnología iniciada en 2018 que proporciona herramientas y servicios para construir aplicaciones de IA, incluidas aplicaciones LLM. Uno de los servicios más populares que proporciona es un repositorio de LLM abiertos. Al momento de escribir, hay cerca de 700,000 LLM abiertos en el repositorio de Huggingface, que es probablemente el más grande que existe.
En el resto de este artículo, independientemente de si usamos otras herramientas de Huggingface, la mayoría de los modelos, a menos que se mencione lo contrario, se descargan de un repositorio de Huggingface. Esto significa que debes obtener una cuenta de Huggingface y crear un token de Huggingface, que te proporcionará permiso para descargar el modelo cuando sea necesario.
🤗 Transformadores
Huggingface proporciona una biblioteca llamada transformadores que permite a los desarrolladores descargar y utilizar LLMs abiertos. En particular, la característica pipeline proporciona capacidades para hacer inferencia usando cualquier modelo de Huggingface de una manera relativamente sencilla.
Veamos algo de código. Como en muchas aplicaciones LLM, esto es en Python.
import transformers
import torch
pipeline = transformers.pipeline(
"text-generation",
model="meta-llama/Meta-Llama-3-8B-Instruct",
model_kwargs={
"torch_dtype": torch.float32,
"low_cpu_mem_usage": True,
},
)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": """Why is the sky blue?"""},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
El primer bloque de código define una canalización utilizando el paquete de transformadores. En este ejemplo, vamos a utilizar el mismo caso de uso del chat del artículo anterior. El parámetro model en el pipeline define el modelo que vamos a utilizar. Los siguientes bloques definen el prompt y también los terminadores que significarán el final del mensaje en un turno. No te preocupes si no estás seguro de qué token usar, en realidad el token <|eot_id|> lo proporciona el propio Meta.
Una vez que hayas preparado los parámetros, puedes llamar a la función de tubería con esos parámetros y la tubería va a resolver todo y le devolverá una respuesta.
Puedes notar que la primera vez que ejecutes esto, se descargará todo el LLM a tu ordenador. Las siguientes llamadas serán al LLM local.
Además de Python, Huggingface también proporciona Transformers.js, el equivalente en Javascript del paquete de transformadores de Python. Esto se ejecutará tanto en tu navegador, como en el servidor usando node.js.
Como puedes imaginar, si escribes código Python o Javascript, puedes utilizar fácilmente Huggingface Transformers para integrar el acceso LLM.
🤗 Inferencia de generación de texto (TGI)
Huggingface Transformers es bastante simple, pero no muy eficiente, por desgracia. Lo que Huggingface realmente utiliza en producción para su propia API de inferencia es la Inferencia de Generación de Texto (TGI, por sus siglas en inglés). Lanzado por primera vez en julio de 2023, Text Generation Inference (TGI) es un conjunto de herramientas que proporciona generación de texto de alto rendimiento para los LLM de código abierto más populares. Es compatible con varios tipos de hardware, como Nvidia, AMD, Intel, Inferentia de AWS y TPU de Google. TGI proporcionó una gran mejora en términos de velocidad y procesamiento concurrente debido a su cola interna y mecanismo de procesamiento por lotes y su uso de gRPC para la comunicación con los fragmentos del modelo.
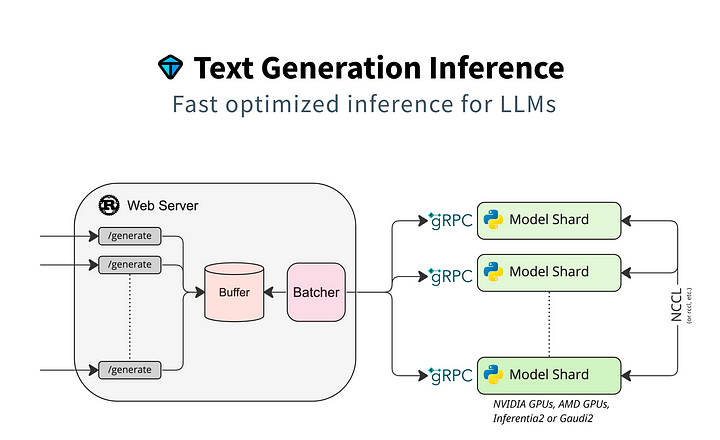
Usar TGI no es difícil, si sólo usas su Docker oficial:
$ vol=$PWD/data
$ model=meta-llama/Meta-Llama-3-8B-Instruct
$ token=<your huggingface token>
$ docker run \
--gpus all \
--shm-size 1g \
--env HUGGING_FACE_HUB_TOKEN=$token \
--publish 5000:80 \
--volume $vol:/data ghcr.io/huggingface/text-generation-inference:2.0 \
--model-id $model
La variable de entorno HUGGING_FACE_HUB_TOKEN es necesaria aquí porque Meta requiere una verificación antes de que su modelo Llama-3 sea descargado y utilizado. Puede utilizar otros modelos de Huggingface libremente si esto no es necesario por el proveedor de modelos. La variable vol aquí es almacenar los modelos localmente para que no tenga que ser descargado cada vez.
Si no quieres ejecutarlo en el puerto 5000, una alternativa sencilla es usar iptables para redirigir el tráfico del puerto 80.
$ sudo iptables -t nat -A PREROUTING -p tcp --dport 80 \
-j REDIRECT --to-port 5000
Recuerda que si quieres detener el contenedor docker, debes usar docker para hacerlo.
A diferencia de Huggingface Transformers, el uso de TGI sin embargo requiere que inicies TGI por separado como servidor y accedas a él a través de una API.
curl http://34.142.153.101/generate \
-H 'Content-Type: application/json' \
-d '{
"inputs":"Whis the sky blue?"
}'
Esto devuelve algo como esto:
{
"generated_text": " The sky appears blue because of the way that light interacts with the tiny molecules of gases in the Earth's atmosphere. Here's a simplified explanation:\n\n1. Sunlight enters the Earth's atmosphere: When the sun shines, it emits a wide range of wavelengths of light, including many different colors.\n2. Light interacts with the atmosphere: As the light travels through the atmosphere, it encounters tiny molecules of gases like nitrogen (N2) and oxygen (O2). These molecules scatter the light in"
}Sin embargo, también cuenta con una API compatible con OpenAI.
curl http://34.142.153.101/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Meta-Llama-3-8B-Instruct",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Why is the sky blue?"
}
]
}'
Esto devolverá una respuesta compatible con OpenAI.
{
"id": "",
"object": "text_completion",
"created": 1717416376,
"model": "meta-llama/Meta-Llama-3-8B-Instruct",
"system_fingerprint": "2.0.4-sha-f426a33",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The sky appears blue because of a phenomenon called scattering. When sunlight enters Earth's atmosphere, it encounters tiny molecules of gases such as nitrogen (N2) and oxygen (O2). These molecules scatter the light in all directions, but they scatter shorter (blue) wavelengths more than longer (red) wavelengths.\n\nThis is known as Rayleigh scattering, named after the British physicist Lord Rayleigh, who first described the phenomenon in the late 19th century. The scattered blue light is then reflected back"
},
"logprobs": null,
"finish_reason": "length"
}
],
"usage": {
"prompt_tokens": 27,
"completion_tokens": 100,
"total_tokens": 127
}
}¿Bastante sencillo? Sí, pero si intentas ejecutar pipeline o TGI en tu propio portátil, te darás cuenta rápidamente de que no funciona (a menos que tengas un ordenador de sobremesa bastante potente). Para ejecutarlo correctamente necesitamos una máquina más potente, con al menos 1 GPU, para tener un tiempo de respuesta razonable.
Hagamos un breve inciso para hablar de los requisitos de hardware.
Hardware
¿Cuánta memoria de GPU se necesita para ejecutar una Llama-3-8B?
Los cálculos son relativamente sencillos. El modelo Meta-Llama por defecto utiliza 16 bits para representar 1 parámetro, es decir, 2 bytes. Con 8.000 millones de parámetros, esto significa que necesitamos 8.000 millones x 2 bytes = 16.000 millones de bytes o 16 GB. Para ejecutar el LLM, tenemos que cargarlo en la memoria de la GPU, por lo que necesitamos 16 GB de memoria de la GPU para los pesos del LLM.
Sin embargo, además de los pesos, hay otros gastos adicionales que requieren memoria de la GPU, lo que supone aproximadamente un 20% sobre el número calculado. En el caso de Llama-3-8B, esto significa 16 + (0,2 x 16) ~= 20 GB de memoria de la GPU.
Si nos fijamos en la lista de GPU de Nvidia, entre las GPU de consumo, las series 4090 y 3090 son las que tienen 24 GB de memoria. En cuanto a las GPU para centros de datos, la T4 y la V100 sólo tienen 16 GB de memoria, mientras que las que tienen 24 GB son la A10 y la L4. Por supuesto, hay GPUs mucho más potentes como la A100 y la H100 que también funcionarán muy bien, pero son bastante caras.
Esta es una interesante aplicación en Huggingface que puede ayudarte a estimar el número de GPUs y la cantidad de memoria GPU necesaria.
En mi caso, utilizo Google Cloud con una instancia G2 con 1 GPU L4, 12 vCPUs y 48GB de memoria normal, porque no tengo un ordenador de sobremesa con una GPU Nvidia (utilizo un Macbook Pro). Si estás ejecutando un servidor sin CUDA preinstalado, no olvides instalar los controladores CUDA para tu máquina. Este es un buen tutorial para instalar CUDA en un servidor Ubuntu 22.04 LTS.
VLLM
VLLM es una conocida biblioteca de inferencias LLM desarrollada por primera vez en la Universidad de Berkeley. Cuando se lanzó por primera vez, las pruebas comparativas mostraron que era hasta 24 veces más rápida que HuggingFace Transformers (HF) y hasta 3,5 veces más rápida que TGI.
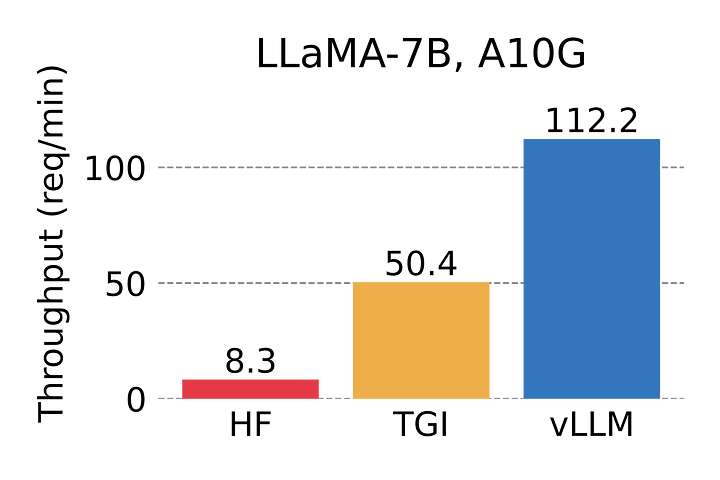
Hay dos maneras de ejecutar VLLM, ya sea directamente como en el uso de Huggingface (documentación VLLM llama a esta inferencia fuera de línea) o servirlo como API a través de un servidor compatible con OpenAI. En este artículo, me centraré en la ejecución del servidor VLLM.
Instalación de VLLM
La instalación de VLLM es como la de cualquier otro paquete de Python.
$ pip install vllm
Ejecutar el servidor VLLM
Ejecutar el servidor VLLM es bastante sencillo. Pero recuerda que tendrás que descargar el modelo de Huggingface así que recuerda configurar tu entorno con el token de Huggingface:
$ export HF_TOKEN=<your Huggingface token>
Ahora pon en marcha el servidor.
$ python -m vllm.entrypoints.openai.api_server \
--host 0.0.0.0 \
--port 5000 \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--api-key abc123
Observa que también estás configurando la clave API para acceder a este servidor. Si no estás muy interesado en establecerla aquí, también puedes establecerla en la variable de entorno VLLM_API_KEY, y el servidor la recogerá.
Como antes, si no quieres ejecutarlo en el puerto 5000, puedes usar iptables para redirigir el tráfico desde el puerto 80.
$ sudo iptables -t nat -A PREROUTING -p tcp --dport 80 \
-j REDIRECT --to-port 5000
Ya está.
Uso del servidor VLLM
Comprobemos cómo funciona. VLLM proporciona un servidor compatible con la API OpenAI, lo que significa que puedes utilizarlo para enviar una solicitud de finalización de chat al servidor VLLM.
$ curl http://34.142.153.101/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer abc123" \
-d '{
"model": "meta-llama/Meta-Llama-3-8B-Instruct",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Why is the sky blue?"
}
]
}'
Esto también significa que puedes utilizar la biblioteca OpenAI Python casi exactamente de la misma manera.
from openai import OpenAI
client = OpenAI(
base_url="http://34.142.153.101/v1",
api_key="abc123",
)
completion = client.chat.completions.create(
model="meta-llama/Meta-Llama-3-8B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Why is the sky blue?"}
]
)
print(completion.choices[0].message.content)
La única diferencia es que ahora necesita establecer la base_url.
Esta es la respuesta que obtendrá del servidor VLLM.
{
"id": "cmpl-0f1d9a9e515846069b96ed80b7d2d03a",
"object": "chat.completion",
"created": 1717172261,
"model": "meta-llama/Meta-Llama-3-8B-Instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The sky appears blue because of a phenomenon called Rayleigh scattering, which is the scattering of light by small particles or molecules in the atmosphere.\n\nWhen sunlight enters Earth's atmosphere, it encounters tiny molecules of gases such as nitrogen (N2) and oxygen (O2). These molecules scatter the light in all directions, but they scatter shorter (blue) wavelengths more than longer (red) wavelengths. This is because the smaller molecules are more effective at scattering the shorter wavelengths.\n\nAs a result, the blue light is scattered in all directions and reaches our eyes from all parts of the sky, making it appear blue. The longer wavelengths of light, such as red and orange, continue to travel in a more direct path to our eyes, which is why the sun appears yellow or orange.\n\nThis effect is more pronounced during the daytime when the sun is overhead, and the light has to travel through more of the atmosphere to reach our eyes. At sunrise and sunset, the sun's light has to travel through more of the atmosphere at an angle, which scatters the shorter wavelengths even more, giving the sky its reddish hue.\n\nSo, to summarize, the sky appears blue because of the scattering of sunlight by the tiny molecules in the atmosphere, with shorter wavelengths of light (like blue) being scattered more than longer wavelengths (like red)."
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 28,
"total_tokens": 295,
"completion_tokens": 267
}
}Llama.cpp
Hemos visto Huggingface y VLLM para inferencias en una máquina Linux, principalmente en un servidor. Ahora veamos el otro extremo – máquinas de usuario final. Para ello me centraré en la biblioteca Llama.cpp.
Llama.cpp es un proyecto de código abierto de Georgi Gerganov, que reescribió de forma impresionante el código de inferencia de Llama en C++ en una noche de marzo de 2023. El proyecto también cuantizó el modelo Llama utilizando la biblioteca de tensores GGML. Mientras que la cuantización original utilizaba enteros de 4 bits, desde entonces se ha actualizado para soportar la cuantización de enteros de 2 a 6 bits.
Llama.cpp es un gran avance porque antes de eso, ejecutar LLM en dispositivos de usuario final era casi imposible. Con llama.cpp y su cuantización GGML, ahora podemos ejecutar LLMs más pequeños en portátiles e incluso en dispositivos iOS y Android.
Es un poco confuso, pero GGML es tanto una biblioteca tensorial como el nombre original del formato de archivo para los modelos cuantizados. Posteriormente Georgi lanzó un nuevo formato de archivo llamado GGUF en agosto de 2023, que es una mejora de GGML y se ha utilizado desde entonces. Ahora, GGML se refiere únicamente a la biblioteca tensorial.
Llama.cpp puede usarse tanto en servidores como en portátiles, pero hay un par de razones por las que es una implementación interesante. Primero, fue implementado en C/C++ sin ninguna dependencia. Esto hace que sea mucho más fácil de implementar y desplegar en comparación con el número de dependencias de Python que necesitan otras librerías. Y en segundo lugar, Apple Silicon es un ciudadano de primera clase. Esto es importante para las máquinas MacOS ahora que todas las últimas máquinas MacOS se ejecutan en Apple Silicon desde junio de 2023.
Llama.cpp es un proyecto repleto de características y capacidades. Esto incluye un completo servidor API compatible con OpenAI. Una vez que hayas conseguido el repositorio en tu portátil, ejecuta esto en ese directorio:
$ make
Eso es todo lo que tienes que hacer si estás ejecutando MacOS en una máquina Apple Silicon. Si tienes otros entornos, puedes consultar la documentación.
Luego, para ejecutar el servidor, sólo tienes que hacer esto en la línea de comandos:
$ ./server -m models/Meta-Llama-3-8B-Instruct.Q4_0.gguf --api-key abc123
Por supuesto, esto supone que has descargado un archivo de modelo GGUF en el directorio de modelos. Debería haber un montón de ellos en Huggingface, éste por ejemplo, funciona para mí.
Una vez que lo tengas funcionando, puedes usar curl de nuevo para llamar al servidor, que por defecto se ejecuta en el puerto 8080.
$ curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer abc123" \
-d '{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Why is the sky blue?"
}
]
}'
Deberías ver una respuesta como esta:
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "What a great question!\n\nThe sky appears blue because of a phenomenon called Rayleigh scattering, named after the British physicist Lord Rayleigh. Here's what happens:\n\n1. **Light from the sun**: When sunlight enters Earth's atmosphere, it contains all the colors of the visible spectrum, including red, orange, yellow, green, blue, indigo, and violet.\n2. **Molecules in the air**: The atmosphere is made up of tiny molecules of gases like nitrogen (N2) and oxygen (O2). These molecules are much smaller than the wavelength of light.\n3. **Scattering**: When light travels through the atmosphere, it encounters these tiny molecules. The smaller molecules scatter shorter (blue) wavelengths of light more than longer (red) wavelengths. This is because the smaller molecules are more effective at scattering the shorter wavelengths.\n4. **Blue light dominates**: As a result of the scattering, the blue light is distributed throughout the atmosphere in all directions. This is because the blue light is scattered in every direction, whereas the longer wavelengths (like red light) continue to travel in a more direct path to our eyes.\n5. **Our perception**: When we look at the sky, we see the combined effect of all the scattered blue light, which gives the sky its blue appearance. The longer wavelengths of light, like red and orange, are not scattered as much and reach our eyes from a more direct path, which is why we see the sun as yellowish or reddish during sunrise and sunset.\n\nSo, to summarize, the sky appears blue because the tiny molecules in the atmosphere scatter shorter blue wavelengths of light more than longer wavelengths, making blue the dominant color we see.\n\nI hope that helps!",
"role": "assistant"
}
}
],
"created": 1717423767,
"model": "unknown",
"object": "chat.completion",
"usage": {
"completion_tokens": 346,
"prompt_tokens": 29,
"total_tokens": 375
},
"id": "chatcmpl-nlB7zVf13P5FDSm2wA2udezBPKzMDjgS"
}Llama.cpp es muy potente y ha habido un montón de herramientas y bibliotecas posteriores escritas sobre él, proporcionando aún más características y capacidades. Una de las más populares, y que me gustó mucho es Ollama.
Ollama
Ollama, iniciado en julio de 2023, es un proyecto muy interesante y uno de mis proyectos de código abierto LLM favoritos. Esto no es sólo porque utiliza mi biblioteca favorita llama.cpp y está construido con mi lenguaje de programación favorito, Go. Me gusta por su enfoque sencillo, casi minimalista.
Ollama sólo tiene un instalador descargable, uno para MacOS, Linux y Windows (experimental por ahora). Una vez que lo instalas, puedes ejecutarlo inmediatamente desde la línea de comandos.
Sí, la interfaz principal es la línea de comandos.
Por ejemplo, cuando ejecutes esto:
$ ollama run llama3
Esto descarga inmediatamente el modelo cuantificado de 4 bits Llama-3-8B-Instruct y le permite interactuar con él directamente a través de la misma interfaz de línea de comandos. No hay ninguna complicación.
Ollama proporciona una lista de modelos (todos en GGUF, porque la base de Ollama es llama.cpp) que ha sido limpiada y preparada para su uso por Ollama en https://ollama.com/library. La lista está bien mantenida y tiene descripciones claras y limpias de los modelos y varias cuantizaciones y tamaños del mismo modelo. Por ejemplo, hay 68 ‘etiquetas’ Llama 3 diferentes en Ollama, cada una representando un tamaño de modelo con una cuantización. Puedes elegir simplemente llama3:70b (que es lo mismo que llama3:70b-instruct y llama3:70b-instruct-q4_0) o puedes elegir llama3:70b-instruct-q5_K_M si prefieres el modelo cuantizado de 5 bits o incluso llama3:70b-instruct-fp16 si te apetece el modelo completo sin cuantizar (que probablemente no puedas ejecutar en tu portátil).
Ollama también tiene modelos multimodales como Llava y modelos de incrustación como artic-embed de Snowflake y nomic-embed-text de Nomic. Aunque la tecnología subyacente es llama.cpp, Ollama simplemente la simplifica y facilita proporcionando herramientas simplificadas y también un ecosistema en torno a los modelos.
En cuanto al hardware, dado que Ollama se ejecuta en llama.cpp y admite cuantización (4 bits por defecto), en general los requisitos de hardware son relativamente bajos, lo que lo hace ideal para ejecutarse en dispositivos de usuario final como los portátiles. Como regla general, Ollama sugiere que tu dispositivo debería tener al menos 8GB de RAM para ejecutar los modelos 7B, 16GB de RAM para ejecutar los modelos 13B y 32GB de RAM para ejecutar los modelos 33B. Puedes extrapolar las cifras en consecuencia.
Ni que decir tiene que Ollama también proporciona un servidor API compatible con OpenAI, aunque de momento sigue siendo una función experimental.
Ejecutando el servidor Ollama
Si has instalado el instalador de Ollama y has iniciado Ollama, ¡el servidor ya está funcionando! Y si has ejecutado algún modelo utilizando ollama run habrá descargado ese modelo. En cualquier caso, si sólo quieres descargar el modelo sin ejecutarlo inmediatamente, puedes hacerlo:
$ ollama pull <model name>
Ahora que tienes el modelo, puedes simplemente hacer esto:
$ curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama3",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Why is the sky blue?"
}
],
"stream": false
}'
Y como era de esperar obtendrás la siguiente respuesta JSON.
{
"id": "chatcmpl-643",
"object": "chat.completion",
"created": 1717465944,
"model": "llama3",
"system_fingerprint": "fp_ollama",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The sky appears blue to our eyes because of a combination of factors related to light, atmosphere, and physics. Here's a simplified explanation:\n\n1. **Light**: When sunlight enters Earth's atmosphere, it contains all the colors of the visible spectrum (ROYGBIV: Red, Orange, Yellow, Green, Blue, Indigo, Violet). Each color has its own unique wavelength.\n2. **Scattering**: As light travels through the atmosphere, it encounters tiny molecules of gases like nitrogen and oxygen, as well as larger particles like dust, water vapor, and pollutants. These particles scatter shorter-wavelength blue light more than longer-wavelength red light.\n3. **Atmospheric conditions**: The atmosphere's density, temperature, and humidity also affect how light behaves. For example:\n\t* Water vapor and aerosols absorb certain wavelengths of light, making them appear less intense or even invisible to our eyes.\n\t* Temperature and pressure variations can change the way light interacts with atmospheric particles.\n\nGiven these factors, here's what happens:\n\n* **Blue dominance**: The scattered blue light is spread out over a larger area, reaching our eyes from all directions. This makes it more visible than other colors, which are either absorbed or scattered in different ways.\n* **Red absorption**: Longer-wavelength red light tends to be absorbed by atmospheric particles and gases, reducing its visibility.\n\nSo, the combination of scattering, absorption, and atmospheric conditions results in our perception of the sky as blue!"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 28,
"completion_tokens": 297,
"total_tokens": 325
}
}Integrar Ollama
Ollama está construido con Go. Aunque podemos llamar a las APIs OpenAI de Ollama ejecutándolas localmente, sería más fácil si ya estamos desarrollando en Go, incrustar Ollama en tu aplicación y llamar a las funciones directamente.
Para incrustar Ollama, tendremos que hacer algunas cosas.
Tenemos que crear Ollama como un submódulo de nuestra aplicación más grande. En este caso, suponiendo que estamos en el directorio raíz de la aplicación.
$ git submodule add https://github.com/ollama/ollama.git
Una vez añadido el submódulo tendrá un subdirectorio llamado ollama. Posteriormente puede entrar en ese subdirectorio y hacer lo siguiente para obtener las últimas actualizaciones.
$ git pull
Ahora que es un submódulo, puedes usarlo en tu código Go. Empecemos por generar las dependencias que necesitará tu código. Ejecuta esto en el directorio ollama.
$ go generate ./...
Esto generará y compilará llama.cpp (que a su vez está incrustado dentro de Ollama) y configurará las cosas para que podamos usarlo a través de import.
Veamos algunos ejemplos de código. El siguiente fragmento de código proviene del proyecto Kaze, donde mostré cómo crear un chatbot simple usando Ollama embebido.
import (
"github.com/ollama/ollama/api"
)
const system = "You are an AI assistant who can answer questions and follow instructions."
func predict(model string, query string, doc string, w http.ResponseWriter) (string, error) {
t0 := time.Now()
f := w.(http.Flusher)
client, err := api.ClientFromEnvironment()
if err != nil {
return "", err
}
// By default, GenerateRequest is streaming.
req := &api.GenerateRequest{
Model: model,
System: system,
Prompt: query + "\n\n" + doc,
}
results := ""
ctx := context.Background()
respFunc := func(resp api.GenerateResponse) error {
results += resp.Response
w.Write([]byte(resp.Response))
f.Flush()
return nil
}
err = client.Generate(ctx, req, respFunc)
if err != nil {
return "", err
}
elapsed := durafmt.Parse(time.Since(t0)).LimitFirstN(2)
fmt.Fprintf(w, "```(%s)```", elapsed)
f.Flush()
return results, nil
}
En primer lugar, importamos github.com/ollama/ollama/api . A continuación, tenemos que crear un cliente Ollama.
client, err := api.ClientFromEnvironment()
if err != nil {
return "", err
}
También necesitamos definir una petición. El modelo es básicamente el nombre del modelo, por ejemplo, Llama3, mientras que el sistema es la solicitud del sistema.
req := &api.GenerateRequest{
Model: model,
System: system,
Prompt: query + "\n\n" + doc,
}También necesitamos crear una función que procese la respuesta del modelo.
respFunc := func(resp api.GenerateResponse) error {
results += resp.Response
w.Write([]byte(resp.Response))
f.Flush()
return nil
}Esta función, incluida la solicitud, se transmite a la función Generar del cliente.
err = client.Generate(ctx, req, respFunc)
if err != nil {
return "", err
}
Esto es todo.
Antes de terminar, me gustaría destacar otro proyecto popular, también basado en llama.cpp pero este es más para gente en el entorno Windows (que yo no uso en absoluto). El proyecto se llama KoboldCpp.
KoboldCpp fue originalmente bifurcado de llama.cpp para la comunidad de jugadores, usado para escribir historias y personajes para juegos y para compartir. Con el tiempo se ha convertido en una herramienta de generación de texto fácil de usar, tanto con una interfaz web como con una API. Además de la generación de texto a través de llama.cpp también incorporó la generación de imágenes a través de Stable Diffusion.
Koboldcpp no debe confundirse con KoboldAI aunque ambos fueron creados por la misma comunidad. KoboldAI se centra en la WebUI y no está tan bien actualizado como KoboldCpp.
Resumen
Este artículo es bastante largo, pero sólo toca la punta del iceberg. La presa estalló en febrero de 2023 (¡el año pasado!) cuando Meta lanzó Llama. En ese momento Simon Willison escribió:
Ese furioso sonido de tecleo que puedes oír son miles de hackers de todo el mundo empezando a indagar y averiguar cómo es la vida cuando puedes ejecutar un modelo de clase GPT-3 en tu propio hardware.
De eso hace poco más de un año y todas estas cosas asombrosas se han logrado desde entonces y es casi seguro que hay mucho más por venir.