

Tabla de contenidos
Introducción
El desarrollo de agentes de inteligencia artificial que puedan, entre otras cosas, pensar, planificar y decidir con una destreza similar a la humana es un área destacada de investigación y debate en la actualidad. Por el momento, los LLM han tomado la delantera como base fundamental de estos agentes. Al perseguir capacidades cada vez más complejas, independientemente de los LLM que se utilicen, inevitablemente nos encontramos con los mismos tipos de preguntas una y otra vez, entre ellas:
- ¿Dispone el modelo de los conocimientos necesarios para realizar una tarea con precisión y eficacia?
- Si dispone de los conocimientos adecuados, ¿cómo podemos activarlos de forma fiable?
- ¿Es capaz el modelo de imitar comportamientos cognitivos complejos como el razonamiento, la planificación y la toma de decisiones con un nivel de competencia aceptable?
Este artículo explora estas cuestiones a través de un miniexperimento que he llevado a cabo recientemente y que aprovecha el último benchmark MMLU-Pro. Los hallazgos conducen a algunas ideas interesantes sobre la flexibilidad cognitiva y cómo podríamos aplicar este concepto de la ciencia cognitiva a nuestro agente de IA y a nuestros esfuerzos de ingeniería prompt.
Blackgroud
MMLU-Pro: un desafío de elección múltiple
El recientemente publicado benchmark MMLU-Pro (Massive Multitask Language Understanding) pone a prueba los límites de capacidad de los modelos de IA presentando un conjunto de tareas más robusto y desafiante en comparación con su predecesor, MMLU [1]. El objetivo era crear una evaluación exhaustiva que cubriera una amplia gama de temas, exigiendo a los modelos que poseyeran una amplia base de conocimientos y demostraran la capacidad de aplicarlos en contextos variados. Para ello, MMLU-Pro pone a prueba los modelos con preguntas tipo test muy complejas, orientadas al razonamiento y repartidas en 14 dominios de conocimiento diferentes.
Todos estamos familiarizados con los exámenes tipo test por nuestra propia trayectoria académica. Las estrategias que utilizamos en este tipo de pruebas suelen consistir en una combinación de razonamiento, resolución de problemas, memoria, eliminación, inferencia y conjetura. Nuestra capacidad para alternar sin problemas entre estas estrategias se basa en la flexibilidad cognitiva, que empleamos para adaptar nuestro enfoque a las exigencias de cada pregunta concreta.
La flexibilidad cognitiva abarca capacidades mentales como cambiar de un concepto a otro y pensar en varios conceptos a la vez. Nos permite adaptar nuestro pensamiento a cada situación. ¿Es este concepto potencialmente útil para nuestro agente de IA y para nuestros esfuerzos de ingeniería? Antes de analizarlo, examinemos un ejemplo de pregunta de MMLU-Pro en la categoría «negocios»:
Pregunta 205: Si los beneficios anuales por acción tienen una media de 8,6 $ y una desviación típica de 3,4 $, ¿cuál es la probabilidad de que un BPA observado sea inferior a 5,5 $?
Respuestas: A: 0,3571, B: 0,0625, C: 0,2345, D: 0,5000, E: 0,4112, F: 0,1814, G: 0,3035, H: 0,0923, I: 0.2756, J: 0.1587
Aunque categóricamente etiquetada como «negocios», esta pregunta requiere conocimientos de estadística. Tenemos que normalizar el valor y calcular cuántas desviaciones estándar se aleja de la media para obtener una estimación de la probabilidad. Esto se hace calculando la puntuación Z de la siguiente manera:
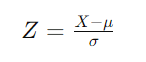
Dónde:
X es el valor en cuestión (5,50 $ en este caso).
μ es la media (dada como 8,6 $).
σ es la desviación típica (dada como 3,4 $).
Si sustituimos esos valores en la fórmula obtenemos -0,09118. A continuación, consultamos la tabla de distribución normal estándar y descubrimos que la probabilidad de que Z sea inferior a -0,9118 es de aproximadamente el 18,14%, que corresponde a la respuesta «F» de nuestras opciones.
Creo que se puede afirmar con seguridad que se trata de un problema no trivial que debe resolver un LLM. La respuesta correcta no se puede memorizar y hay que calcularla. ¿Tendría un LLM los conocimientos y la flexibilidad cognitiva necesarios para resolver este tipo de problema? ¿Qué estrategias de ingeniería prompt podríamos emplear?
Ingeniería prompt al rescate
Al abordar el problema anterior con un LLM, podríamos plantearnos: ¿tiene nuestro modelo elegido los conocimientos de estadística necesarios? Suponiendo que los tenga, ¿cómo podemos activar de forma fiable los conocimientos sobre distribuciones normales estándar? Y, por último, ¿puede el modelo imitar los pasos del razonamiento matemático para llegar a la respuesta correcta?
La conocida estrategia de ingeniería de prompts de la «cadena de pensamiento» (CoT) parece encajar a la perfección. Esta estrategia se basa en incitar al modelo a generar pasos de razonamiento intermedios antes de llegar a la respuesta final. Existen dos enfoques básicos.
- Cadena de pensamiento (CoT): Consiste en dar unos cuantos ejemplos del proceso de razonamiento para guiar el modelo [2].
- Cadena de Pensamiento Cero (CoT Cero): Consiste en pedir al modelo que genere pasos de razonamiento sin ejemplos previos, a menudo utilizando frases como «Pensemos paso a paso» [3].
Existen muchas otras estrategias, que generalmente se basan en una combinación de activación de características previa a la generación, es decir, centrada en la activación de conocimientos en la solicitud inicial, y activación de características intrageneración, es decir, centrada en la activación dinámica de conocimientos por parte del LLM a medida que genera su salida token a token.
Miniexperimento
Diseño del experimento
Para diseñar el miniexperimento, utilicé ChatGPT-4o y tomé muestras aleatorias de 10 preguntas de cada uno de los 14 dominios de conocimiento del conjunto de datos MMLU-Pro. El experimento pretendía evaluar dos aspectos principales:
- Eficacia de las distintas técnicas de ingeniería de prompt: Específicamente, el impacto del uso de diferentes técnicas para activar el conocimiento necesario y el comportamiento deseado en el modelo. Las técnicas se seleccionaron para que se ajustaran a distintos grados de flexibilidad cognitiva y todas se basaron en el disparo cero.
- El impacto de limitar deliberadamente el razonamiento y la flexibilidad cognitiva: En concreto, cómo afecta a la precisión el hecho de limitar la capacidad del modelo para razonar abiertamente (y, en consecuencia, limitar gravemente la flexibilidad cognitiva).
Las diferentes técnicas de pregunta probadas se basaban en las siguientes plantillas:
- Pregunta directa – {Pregunta}. Seleccione la respuesta correcta entre las siguientes opciones:{Respuestas}. Responda con la letra y la respuesta seleccionadas.
- TdC – {Pregunta}. Pensemos paso a paso y seleccionemos la respuesta correcta de entre las siguientes opciones de respuesta: {Respuestas}. Responda con la letra y la respuesta seleccionadas.
- Activación del Dominio del Conocimiento – {Pregunta}. Pensemos en los conocimientos y conceptos necesarios y seleccionemos la respuesta correcta de entre las siguientes opciones de respuesta:
- {Respuestas}. Responda con la letra y la respuesta seleccionadas.
- Andamios contextuales – {Pregunta}. Mis expectativas son que responda correctamente a la pregunta. Crea un contexto operativo para ti mismo que maximice el cumplimiento de mis expectativas y selecciona la respuesta correcta de entre las siguientes opciones de respuesta: {Respuestas}. Responda con la letra y la respuesta seleccionadas. [4]
El enfoque de Pregunta Directa sirvió como línea de base, permitiendo probablemente el mayor grado de flexibilidad cognitiva del modelo. Es probable que CoT genere la menor flexibilidad cognitiva, ya que el modelo debe proceder paso a paso. La Activación del Dominio del Conocimiento y los Andamios Contextuales se sitúan entre la Pregunta Directa y el CoT.
El razonamiento deliberadamente restrictivo se consiguió tomando la última línea de las plantillas de preguntas anteriores, es decir, «Responde con la letra y la respuesta seleccionadas» y especificando en su lugar «Responde sólo con la letra y la respuesta seleccionadas y nada más».
Si te interesa el código que utilicé para realizar el experimento y los resultados, puedes encontrarlos en este repositorio de GitHub enlazado aquí.
Resultados
A continuación se presentan los resultados de las distintas técnicas de pronóstico y sus variantes con restricciones de razonamiento:
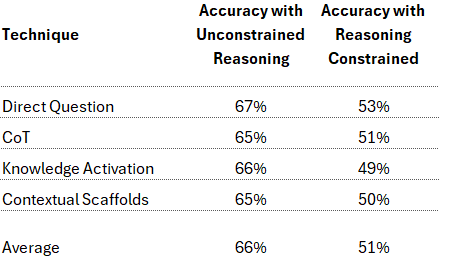
Todas las preguntas de razonamiento sin restricciones obtuvieron resultados comparables, aunque el enfoque de pregunta directa fue ligeramente mejor que los demás. Esto fue una sorpresa, ya que el artículo de MMLU-Pro [1] señala un rendimiento significativamente inferior en la pregunta directa y un fuerte aumento del rendimiento con CoT de pocos disparos. No me detendré aquí en la discrepancia, ya que el propósito del miniexperimento no era replicar su configuración.
Lo más importante para este miniexperimento es que, cuando se restringió deliberadamente el razonamiento, todas las técnicas mostraron un descenso comparable en la precisión, pasando de una media del 66% al 51%. Este resultado coincide con lo que esperábamos. La observación más pertinente es que ninguna de las técnicas consiguió mejorar la activación del conocimiento previo a la generación más allá de lo que ocurriría con la pregunta directa, en la que la activación de características previas a la generación se produce principalmente al exponer el modelo al texto de las opciones de pregunta y respuesta.
La conclusión general de estos resultados de alto nivel sugiere que una combinación óptima para una pronta eficacia de la ingeniería puede muy bien implicar:
- Permitir que el modelo ejerza cierto grado de flexibilidad cognitiva, como se ejemplifica mejor en el enfoque de Pregunta Directa.
- Permitir que el modelo razone abiertamente, de forma que las trazas de razonamiento formen parte activa de la generación.
La dimensión del coste computacional
Aunque no se discute a menudo, la eficiencia de los tokens es cada vez más importante a medida que los LLM se abren camino en diversos casos de uso de la industria. El siguiente gráfico muestra la precisión de cada técnica de consulta sin restricciones frente a la media de tokens generados en la respuesta.
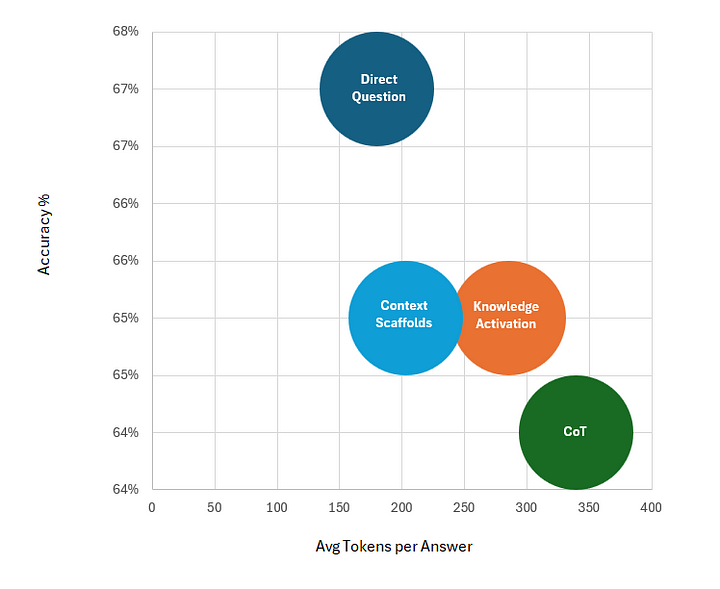
Aunque el diferencial de precisión no es el objetivo principal, la eficiencia del enfoque de Pregunta Directa, que genera una media de 180 tokens por respuesta, es notable en comparación con CoT, que produjo aproximadamente 339 tokens por respuesta (es decir, un 88% más). Dado que la precisión es comparable, cabe suponer que CoT es, por término medio, menos eficaz que las demás estrategias en lo que se refiere a la activación del conocimiento intrageneracional, lo que produce resultados excesivamente verborreicos. Pero, ¿a qué se debe este exceso de verbosidad? Para intentar responder a esta pregunta, resultó útil examinar las preguntas de razonamiento sin restricciones y el número de veces que el modelo optó por responder sólo con la respuesta y sin ningún rastro de razonamiento, aunque no se le hubiera indicado explícitamente que lo hiciera. Los resultados fueron los siguientes

Lo que resultó aún más interesante fue la precisión cuando el modelo optó por responder directamente sin ningún rastro de razonamiento, lo que se muestra en la tabla siguiente:
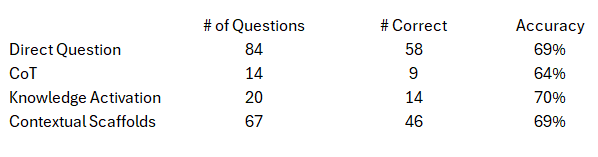
La precisión osciló entre el 64% y el 70% sin que se generara ningún rastro de razonamiento. Incluso con las preguntas de MMLU-Pro, diseñadas a propósito para requerir razonamiento y resolución de problemas, el modelo parece demostrar algo parecido a la selección de diferentes estrategias en función de la pregunta concreta, cuando no está excesivamente condicionado por la pregunta.
Implicaciones prácticas
Lo que se desprende de estos resultados es que las estrategias sencillas pueden ser tan eficaces como las excesivamente estructuradas. Aunque el objetivo de CoT es simular el razonamiento induciendo activaciones de rasgos específicos orientados al razonamiento, puede que no siempre sea necesario u óptimo, especialmente si la generación excesiva de fichas es un problema. En su lugar, un enfoque potencialmente más adecuado puede ser permitir que el modelo ejerza su flexibilidad cognitiva.
Conclusiones: Preparando el camino para la flexibilidad cognitiva en los agentes de IA
Los resultados de este miniexperimento ofrecen una visión convincente de la importancia de la flexibilidad cognitiva en los LLM y los Agentes de IA. En la cognición humana, la flexibilidad cognitiva se refiere a la capacidad de adaptar el pensamiento y el comportamiento en respuesta a tareas o demandas cambiantes. Implica pasar de un concepto a otro, mantener varios conceptos simultáneamente y cambiar la atención según sea necesario. En el contexto de los LLM, puede entenderse como la capacidad del modelo para ajustar dinámicamente sus activaciones internas en respuesta a estímulos textuales.
Si se sigue prestando atención al desarrollo de tecnologías y técnicas en este ámbito, se podría mejorar significativamente la capacidad de los agentes de IA en una serie de tareas complejas. Por ejemplo, la exploración de esta idea junto con otras ideas como las expuestas por Anthropic en su reciente artículo «Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet», podría dar lugar a técnicas que desbloqueen la capacidad de observar y adaptar dinámicamente el nivel de flexibilidad cognitiva empleado en función de la complejidad y el dominio de la tarea.
A medida que ampliemos los límites de la IA, la flexibilidad cognitiva será probablemente clave para crear modelos que no sólo funcionen con fiabilidad, sino que también comprendan y se adapten a las complejidades del mundo real.
Gracias por leerme y sígueme para conocer los resultados de futuras exploraciones relacionadas con este trabajo. Si quieres hablar de ello, no dudes en ponerte en contacto conmigo en LinkedIn.
Salvo que se indique lo contrario, todas las imágenes de este artículo son del autor.