

¿Frustrado por las limitadas canalizaciones de Generación Mejorada de Recuperación (RAG) que sólo manejan un documento a la vez? Abróchate el cinturón, porque Agentic RAG está aquí para desbloquear el poder de la recuperación multidocumento.
En esta continuación de nuestra serie Agentic RAG, nos sumergiremos en el uso de las capacidades de razonamiento multipaso que exploramos anteriormente, pero esta vez a través de una colección diversa de documentos.
Ésta es la parte emocionante: Imagina un agente inteligente capaz de examinar un tesoro de información. Tú formulas una pregunta y este agente te dirige sin problemas al documento más relevante para obtener la respuesta. Agentic RAG lo hace realidad.
Desvelaremos los secretos de este enfoque. Veremos cómo crear una red de “information vaults” específicas para cada documento y cómo capacitar a un agente para navegar por ellas. Por último, seremos testigos de cómo este potente sistema aprovecha los procedimientos tradicionales de RAG para desenterrar las respuestas que busca, independientemente del documento que contenga la clave.
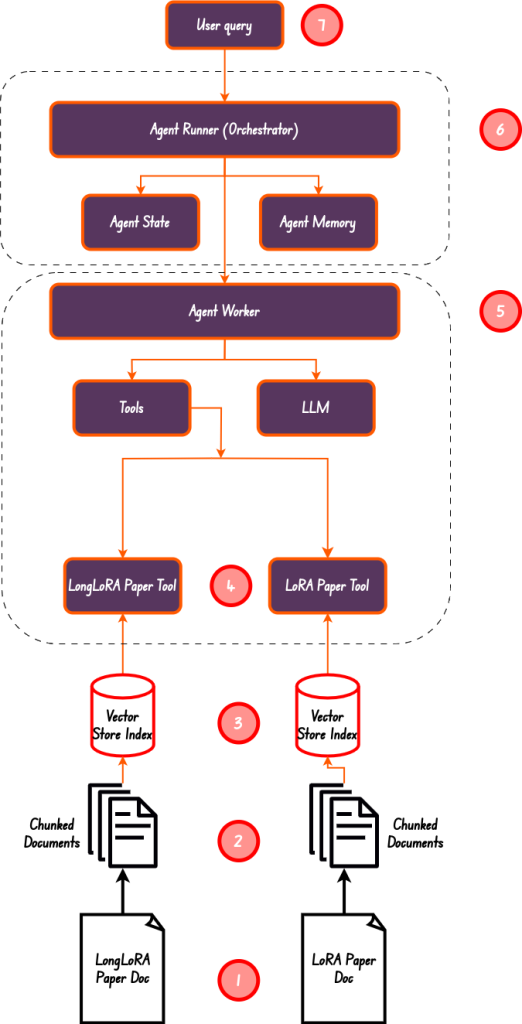
Comencemos con la implementación de una canalización RAG de Agentic para chatear con múltiples documentos.
Tabla de contenidos
Configurar el entorno
El primer paso que daremos es configurar nuestro entorno de desarrollo y prepararlo para codificar. Usaremos el mismo entorno que configuramos en el primer artículo. Simplemente crearé un nuevo archivo ipynb para esta lección en particular.
Nuevo archivo de descarga
También vamos a utilizar un nuevo archivo que se puede descargar desde aquí, este archivo en mi caso se llama longlora_efficient_fine_tuning.pdf
Utils.py actualizado
También tendremos que actualizar el archivo utils.py para alojar una nueva función: create_docs_tool . Esta nueva función nos permitirá crear motores de consulta para un resumen y motores de consulta vectoriales.
from llama_index.core.query_engine.router_query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelector
from llama_index.core.tools import QueryEngineTool
from llama_index.core import SummaryIndex, VectorStoreIndex
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import SimpleDirectoryReader
from typing import Tuple
async def create_router_query_engine(
document_fp: str,
verbose: bool = True,
) -> RouterQueryEngine:
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=[document_fp]).load_data()
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
# LLM model
Settings.llm = OpenAI(model="gpt-3.5-turbo")
# embedding model
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
# summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)
# summary query engine
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
# vector query engine
vector_query_engine = vector_index.as_query_engine()
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
"Useful for summarization questions related to the Lora paper."
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
"Useful for retrieving specific context from the the Lora paper."
),
)
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[
summary_tool,
vector_tool,
],
verbose=verbose
)
return query_engine
async def create_doc_tools(
document_fp: str,
doc_name: str,
verbose: bool = True,
) -> Tuple[QueryEngineTool, QueryEngineTool]:
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=[document_fp]).load_data()
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
# LLM model
Settings.llm = OpenAI(model="gpt-3.5-turbo")
# embedding model
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
# summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)
# summary query engine
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
# vector query engine
vector_query_engine = vector_index.as_query_engine()
summary_tool = QueryEngineTool.from_defaults(
name=f"{doc_name}_summary_query_engine_tool",
query_engine=summary_query_engine,
description=(
f"Useful for summarization questions related to the {doc_name}."
),
)
vector_tool = QueryEngineTool.from_defaults(
name=f"{doc_name}_vector_query_engine_tool",
query_engine=vector_query_engine,
description=(
f"Useful for retrieving specific context from the the {doc_name}."
),
)
return vector_tool, summary_tool
Creación de vectores y la herramienta de resumen
Vamos a utilizar la función que acabamos de crear para generar vectores y herramientas de resumen para cada uno de los documentos que hemos configurado.
import dotenv %load_ext dotenv %dotenv
import nest_asyncio nest_asyncio.apply()
papers = [
"./datasets/lora_paper.pdf",
"./datasets/longlora_efficient_fine_tuning.pdf"
]
from utils import create_doc_tools
from pathlib import Path
paper_to_tools_dict = {}
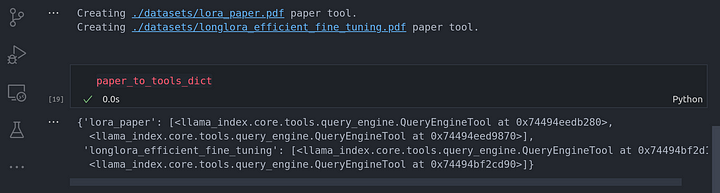
for paper in papers:
print(f"Creating {paper} paper tool.")
path = Path(paper)
vector_tool, summary_tool = await create_doc_tools(doc_name=path.stem, document_fp=path)
paper_to_tools_dict[path.stem] = [vector_tool, summary_tool]
paper_to_tools_dict
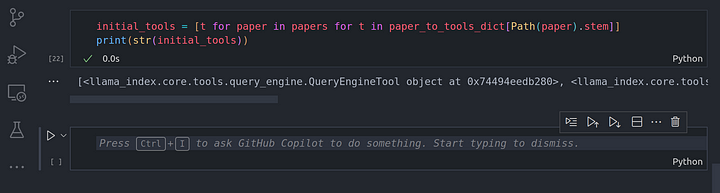
initial_tools = [t for paper in papers for t in paper_to_tools_dict[Path(paper).stem]]
print(str(initial_tools))
len(initial_tools)

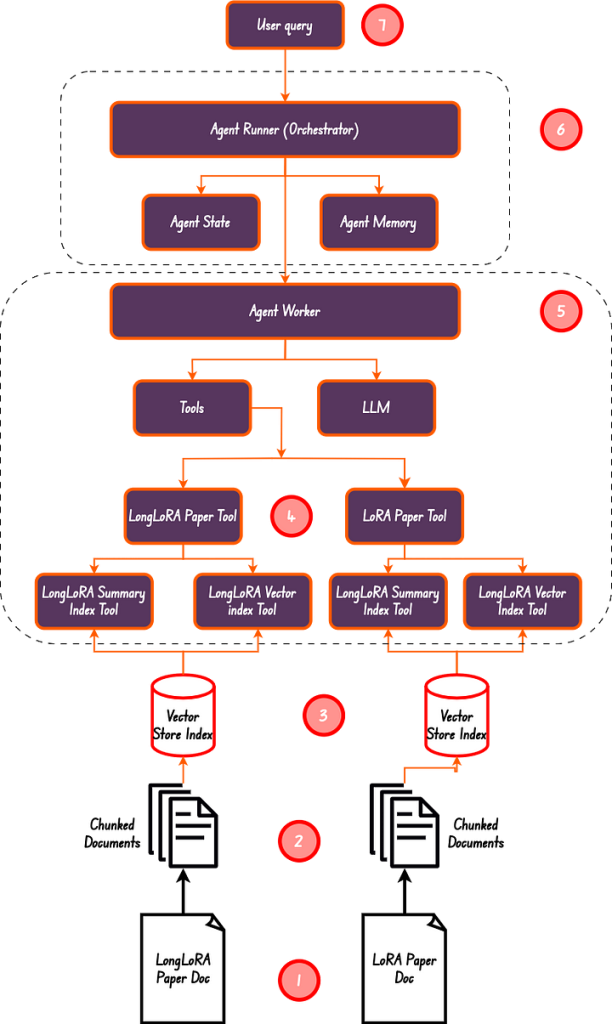
En el diagrama anterior, hemos realizado del paso 1 al paso 5. Hemos creado un resumen y un índice vectorial, asegurándonos de que tenemos 4 herramientas en total, que es también la longitud de la lista de herramientas.
Creando el Agente Trabajador
El trabajador agente es el Orquestador responsable de asignar tareas al trabajador agente. Este es el paso número 6 en el diagrama anterior.
from llama_index.llms.openai import OpenAI llm = OpenAI(model="gpt-3.5-turbo")
from llama_index.core.agent import FunctionCallingAgentWorker from llama_index.core.agent import AgentRunner agent_worker = FunctionCallingAgentWorker.from_tools( initial_tools, llm=llm, verbose=True ) agent = AgentRunner(agent_worker)
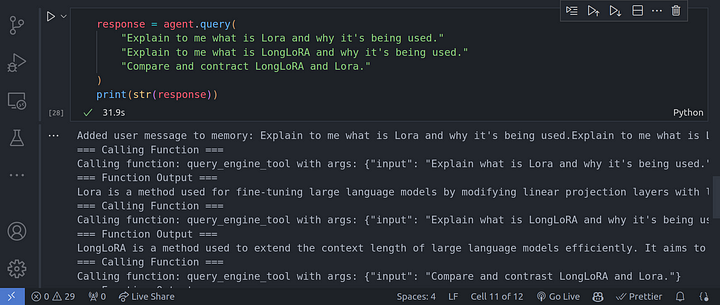
response = agent.query(
"Explain to me what is Lora and why it's being used."
"Explain to me what is LongLoRA and why it's being used."
"Compare and contract LongLoRA and Lora."
)
print(str(response))
Canalización RAG Agentic Multi-Documento más avanzada
Hasta ahora hemos podido utilizar dos documentos y todo funciona correctamente. Esto lleva a un problema con más documentos que se añaden. Imagina que tuviéramos 20 documentos que serían 40 herramientas diferentes, eso es un poco salvaje:
- Desbordamiento de la ventana de contexto: Al añadir más documentos a la ventana de contexto se añaden más herramientas, lo que puede provocar un desbordamiento de la ventana de contexto. La forma más sencilla de solucionar este problema es añadir una especie de RAG a la sección de herramientas, de forma que primero realicemos algún tipo de recuperación de las herramientas para ver qué herramienta(s) es(son) la(s) más adecuada(s) para la tarea en cuestión y, a continuación, alimentar el LLM sólo con los resultados de esa herramienta. No queremos pasar demasiadas herramientas a la ventana de contexto, es mejor recuperar primero las herramientas más relevantes y luego pasarlas al LLM.
- Aumento de los costes: Meter muchas herramientas en la ventana de contexto significa más uso de tokens por tu parte. No sé hasta dónde llega tu bolsillo, pero es mejor que me envíes ese dinero a mí.
- LLM puede confundirse: La investigación ha demostrado que en la mayoría de los casos, los LLM recuerdan principalmente las cosas al principio de la ventana de contexto y las del final, el concurso en el medio puede ser olvidado por el LLM. Esto significa que a pesar de las grandes ventanas de contexto que los LLMs tienen hoy en día como Gemini con su 1 millón de tokens, todavía puede sufrir de esto.
La solución a esto es realizar una recuperación de las herramientas para obtener las más relevantes y pasar estas herramientas relevantes al bucle de razonamiento del agente. Al menos esto es lo que Llama-index ha hecho en segundo plano. Proporcionan una recuperación de herramientas que ayuda en esta tarea.
Implementación de RAG multidocumento con recuperación de herramientas
Para implementar esto, te aconsejo que descargues más documentos. En mi caso, sólo utilizaré los documentos existentes con los que hemos estado trabajando hasta ahora. Si lo deseas, puedes utilizar este código para descargar más documentos.
urls = [ "https://arxiv.org/pdf/2106.09685" ] papers = [ "lora_paper.pdf", ]
# poetry add wget
import wget
for url, paper in zip(urls, papers):
!wget "{url}" -O "{paper}"
Asegúrate de ejecutar el comando para instalar wget
$ poetry add wget
Pero en aras de la simplicidad y para ahorrar tiempo a todo el mundo, me ceñiré a los documentos que ya hemos estado utilizando:
papers = [ "./datasets/lora_paper.pdf", "./datasets/longlora_efficient_fine_tuning.pdf" ]
from utils import create_doc_tools from pathlib import Path paper_to_tools_dict = {} for paper in papers: print(f"Creating {paper} paper tool.") path = Path(paper) vector_tool, summary_tool = await create_doc_tools(doc_name=path.stem, document_fp=path) paper_to_tools_dict[path.stem] = [vector_tool, summary_tool] tools_list = [t for paper in papers for t in paper_to_tools_dict[Path(paper).stem]]
print(str(tools_list))
Crea el ObjectIndex que utilizaremos para recuperar las herramientas más adecuadas:
from llama_index.core import VectorStoreIndex from llama_index.core.objects import ObjectIndex obj_index = ObjectIndex.from_objects( tools_list, index_cls=VectorStoreIndex, )
obj_retriever = obj_index.as_retriever(similarity_top_k=3)
retrieved_tools = obj_retriever.retrieve(
"Write me a summary of the LoRA paper."
"Write me a summary of the LongLoRA paper."
"Compare and contract LongLoRA and Lora."
)
print(str(retrieved_tools))
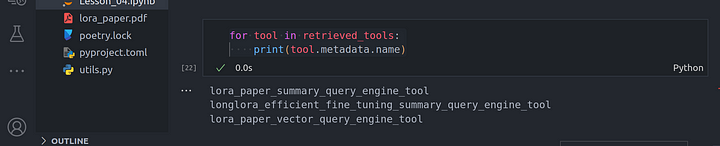
From these set of questions, we can view the tools that have been selected through retrieval:
for tool in retrieved_tools:
print(tool.metadata.name)
Creación del agente
Necesitaremos crear el agente runner y el agente worker:
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
tool_retriever=obj_retriever,
llm=llm,
system_prompt=""" \
You are an AI agent programmed to respond to questions based on a
specified collection of documents. Always utilize the tools available
to generate answers, ensuring that responses are based directly on the
provided materials rather than on any pre-existing knowledge. All your responses should be formatted in markdown text
""",
verbose=True
)
agent = AgentRunner(agent_worker)
We can then go ahead and call the agent:
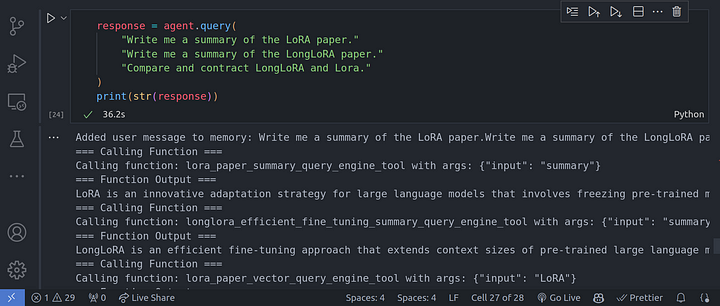
response = agent.query(
"Write me a summary of the LoRA paper."
"Write me a summary of the LongLoRA paper."
"Compare and contract LongLoRA and Lora."
)
print(str(response))
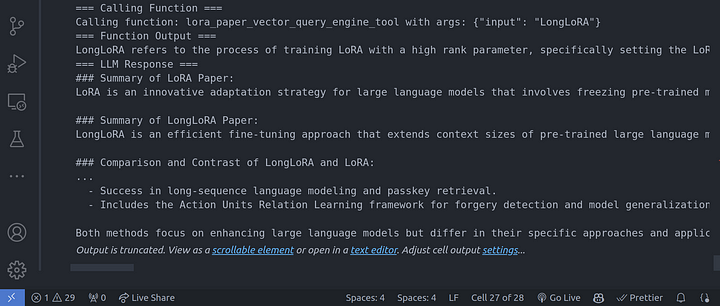
Conclusión
Enhorabuena por haber llegado hasta aquí. En este artículo hemos visto cómo trabajar con un bucle de razonamiento multipaso sobre múltiples documentos en un sistema RAG agéntico. No sólo hemos visto la implementación de alto nivel, sino también el funcionamiento de bajo nivel del bucle de razonamiento multipaso.
Esperamos que este artículo te proporcione una clara comprensión de la capacidad de razonamiento multipaso sobre múltiples documentos.
Otras plataformas en las que puedes ponerte en contacto conmigo: