

Bienvenido de nuevo a la tercera entrega de nuestra serie RAG de Agentic. En este artículo, abordaremos la limitación de los avisos de una sola vez de la que hablamos anteriormente. Hasta ahora, nos hemos centrado en los avisos de un solo paso, en los que las tareas se completan en un único bucle. Sin embargo, cuando se trata de tareas complejas que requieren un razonamiento de varios pasos, este enfoque se queda corto. Aquí es donde brillan los agentes, especialmente en el contexto de los LLM y las aplicaciones RAG Agentic.
En este artículo, exploraremos cómo implementar un bucle de razonamiento multipaso en nuestra arquitectura Agentic RAG. Prepárate para una emocionante inmersión profunda en el poder de los agentes y su capacidad para manejar intrincadas tareas de múltiples pasos con precisión y eficiencia. Puedes consultar los anteriores también en nuestra web, Planeta Chatbot:
- Agentic RAG con Llama-index | Llamada a función #02
- Agentic RAG con Llama-index | Motor de consulta del enrutador #01
Tabla de contenidos
Qué son los agentes
Hasta ahora hemos estado trabajando con Llama-index.
Los data agents son trabajadores del conocimiento potenciados por LLM en LlamaIndex que pueden realizar de forma inteligente diversas tareas sobre sus datos, tanto en función de «lectura» como de «escritura». Son capaces de lo siguiente:
- Realizar búsquedas y recuperaciones automatizadas sobre diferentes tipos de datos: no estructurados, semiestructurados y estructurados.
- Llamar a cualquier API de servicio externo de forma estructurada, y procesar la respuesta + almacenarla para más tarde.
En ese sentido, los agentes van un paso más allá de nuestros motores de consulta, ya que no sólo pueden «leer» de una fuente estática de datos, sino que pueden ingerir y modificar dinámicamente datos de una variedad de herramientas diferentes.
Construir un agente de datos requiere los siguientes componentes básicos:
- Un bucle de razonamiento
- Abstracciones de herramientas
Un data agent se inicializa con un conjunto de APIs, o Herramientas, con las que interactuar; el agente puede llamar a estas APIs para devolver información o modificar el estado. Dada una tarea de entrada, el data agent utiliza un bucle de razonamiento para decidir qué herramientas utilizar, en qué secuencia, y los parámetros para llamar a cada herramienta.
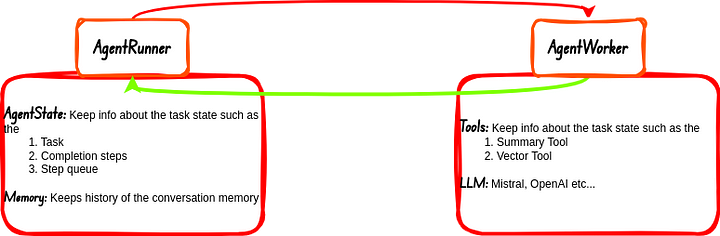
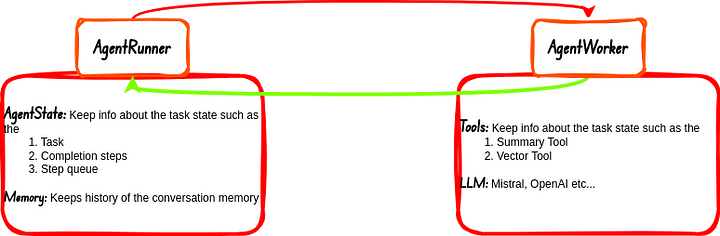
Por defecto los agentes en Llama-index se componen de dos cosas principales:
- AgentRunner: Esta es la parte del agente que se encarga de la orquestación de tareas aka Task Orchestrator. Esta sección del agente también maneja el Estado y la Memoria. El AgentWorker responde a esta sección del agente después de completar cada tarea que se le asigna, la respuesta se comunica al usuario si es necesario.
- AgentWorker: Es lo que realmente ejecuta y razona las tareas. Las tareas son delegadas a esta sección del flujo de trabajo del agente por el AgentRunner. Se ocupa de las Herramientas y LLMs.
Recursos de vídeo
Si te gusta ver vídeos en lugar de leer, también tengo algo para ti.
Configuración del entorno
Utilizaremos el mismo entorno que configuramos en el artículo anterior. Lo único que crearé es un archivo .ipynb, este archivo se llama Lesson_03.ipynb:
Creando Herramientas
Vamos a seguir adelante y crear dos herramientas principales como ya hemos hecho en los últimos artículos.
import dotenv %load_ext dotenv %dotenv import nest_asyncio nest_asyncio.apply()
from llama_index.core import SimpleDirectoryReader
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=["./datasets/lora_paper.pdf"]).load_data()
from llama_index.core.node_parser import SentenceSplitter
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
# LLM model
Settings.llm = OpenAI(model="gpt-3.5-turbo")
# embedding model
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
from llama_index.core import SummaryIndex, VectorStoreIndex # summary index summary_index = SummaryIndex(nodes) # vector store index vector_index = VectorStoreIndex(nodes) # summary query engine summary_query_engine = summary_index.as_query_engine( response_mode="tree_summarize", use_async=True, ) # vector query engine vector_query_engine = vector_index.as_query_engine()
llm = OpenAI(model="gpt-3.5-turbo", temperature=0)
from llama_index.core.tools import QueryEngineTool
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
"Useful for summarization questions related to the Lora paper."
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
"Useful for retrieving specific context from the the Lora paper."
),
)
Bucle de razonamiento
El bucle de razonamiento depende del tipo de agente.
Tenemos soporte para los siguientes agentes:
- Agentes de llamada a función (se integra con cualquier LLM de llamada a función).
- Agente ReAct (funciona a través de cualquier endpoint de finalización de chat/texto).
«Agentes avanzados: LLMCompiler (https://llamahub.ai/l/llama-packs/llama-index-packs-agents-llm-compiler?from=), Chain-of-Abstraction (https://llamahub.ai/l/llama-packs/llama-index-packs-agents-coa?from=), Language Agent Tree Search (https://llamahub.ai/l/llama-packs/llama-index-packs-agents-lats?from=), y más.
AgentWorker
Como hemos comentado anteriormente, el agent worker es el responsable de ejecutar todas las herramientas y los LLMs. Vamos a crear un agent worker pasándole todas las herramientas que hemos creado anteriormente:
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
tools=[vector_tool, summary_tool],
llm=llm,
verbose=True
)
agent = AgentRunner(agent_worker)
Para ello, utilicemos una pregunta que requiera un razonamiento de varios pasos.
response = agent.query(
"Explain to me what is Lora and why it's being used. Are existing solutions not good enough?"
)
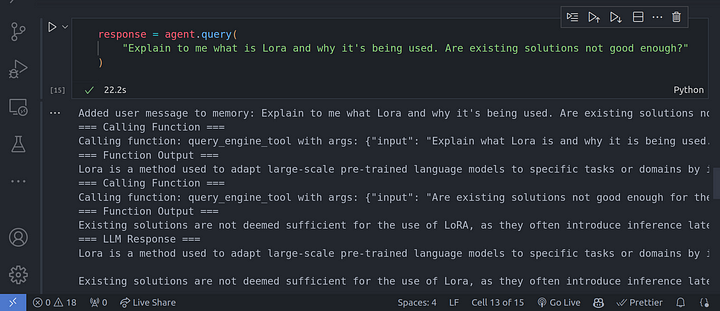
En la imagen de arriba, se puede ver que el LLM está haciendo uso de una cadena de razonamiento CoT para responder a todas las preguntas que le habíamos planteado, una tras otra, basándose en la anterior.
Memoria de conversaciones
Hasta ahora, la arquitectura de agentes RAG funciona bien. Una limitación es que no recuerda conversaciones anteriores. Tenemos la capacidad de mantener una memoria tal que las acciones que realiza el agente no sólo dependen de la consulta del usuario, sino que también se tiene en cuenta el historial de las conversaciones anteriores con los agentes.
La memoria no es más que una lista plana de conversaciones que el agente ha mantenido con el usuario. Esta lista es un buffer de memoria conversacional, la razón es que no queremos tener demasiada conversación almacenada en memoria de tal forma que desbordemos la ventana de contexto de los LLMs. Esta lista actúa como un buffer rodante dependiendo del tamaño de la ventana de contexto del LLM subyacente que estemos usando.
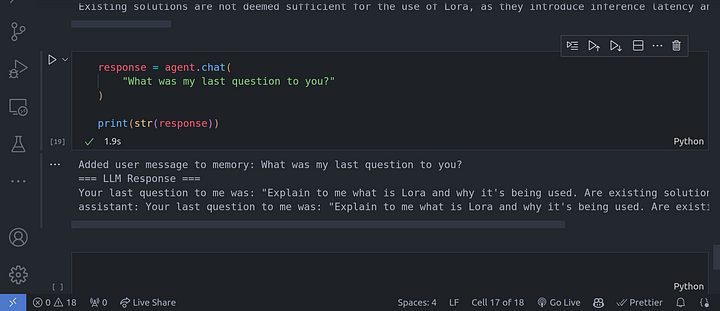
Para utilizar la capacidad de memoria del agente, tenemos que llamar al método chat() en lugar del método query() que hemos utilizado hasta ahora. El método query() no conserva el estado, por lo que no se conserva el historial de la conversación.
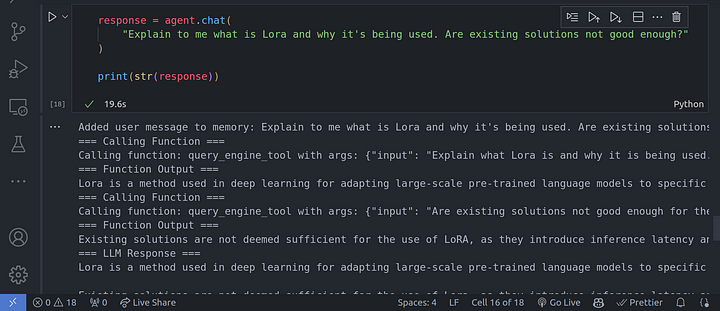
response = agent.chat(
"Explain to me what is Lora and why it's being used. Are existing solutions not good enough?"
)
print(str(response))
response = agent.chat(
"What was my last question to you?"
)
print(str(response))
Cómo funciona a bajo nivel
Hemos visto cómo funciona el agente desde una perspectiva de alto nivel. Echemos un vistazo a cómo funciona en un nivel inferior y obtengamos más control sobre la ejecución del agente y cómo se llevan a cabo las tareas. Esto nos da algunas ventajas añadidas como:
- Programar nuestras propias tareas: Podemos controlar y programar nuestras propias tareas y establecer cuando se ejecutará cada tarea.
- Incorporar feedback humano: Entendiendo cómo funciona el agente a un nivel inferior, podemos ser capaces de proporcionar manualmente feedback humano al agente para hacerle saber si está dando los pasos correctos que queremos o no, en caso contrario podemos especificar manualmente al agente qué acciones queremos que realice.
- Ayuda a la resolución de problemas
En primer lugar, vamos a seguir adelante y crear un agente de ejecución, que se ejecuta el agente de trabajo como hemos discutido anteriormente.
agent_worker = FunctionCallingAgentWorker.from_tools(
[vector_tool, summary_tool],
llm=llm,
verbose=True
)
agent = AgentRunner(agent_worker)
Ahora vamos a crear manualmente una tarea para el agentrunner Orchestrator:
task = agent.create_task(
"Explain to me what is Lora and why it's being used."
"Are existing solutions not good enough?"
)
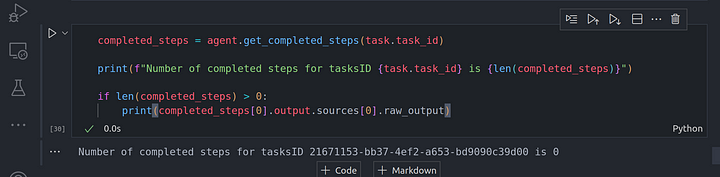
Una vez que tenemos esta tarea creada, recuerda que no pasamos esta tarea al agent worker por lo que no se ejecuta. Así que si comprobamos si se ha completado alguna tarea, deberíamos obtener cero, veamos esto en acción:
completed_steps = agent.get_completed_steps(task.task_id)
print(f"Number of completed steps for tasksID {task.task_id} is {len(completed_steps)}")
if len(completed_steps) > 0:
print(completed_steps[0].output.sources[0].raw_output)
Ahora, vamos a comprobar si el agentrunner ha orquestado algunas tareas para que las ejecute el agent worker. Podemos ver esto viendo las próximas tareas:
upcoming_steps = agent.get_upcoming_steps(task.task_id)
print(f"Number of completed steps for tasksID {task.task_id} is {len(upcoming_steps)}")
if len(upcoming_steps) > 0:
print(upcoming_steps[0].input)
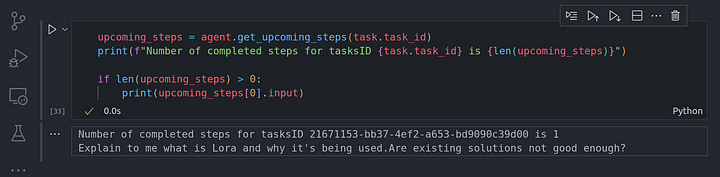
Desde aquí podemos ver la entrada que el agentrunner debe pasar al agent worker para que la ejecute. La entrada es la pregunta original que pasamos a la tarea que acabamos de crear. Ahora, vamos a seguir adelante y ejecutar la próxima tarea programada para ver y volvemos.
step_output = agent.run_step(task.task_id)
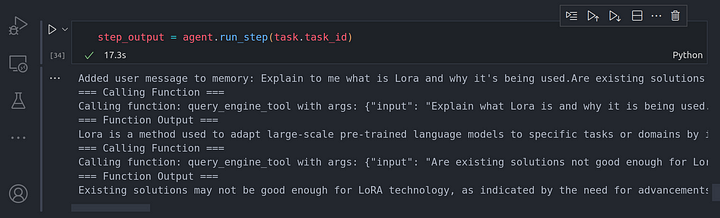
Se puede ver que el agent worker fue capaz de razonar sobre la tarea e identificó que necesitaba dividir la tarea en dos subtareas separadas. Cada subtarea se resolvió mediante el uso de la herramienta de llamada aka función de llamada a la herramienta de motor de consulta en este caso particular.
Una vez hecho esto, podemos seguir adelante para comprobar si hay otras tareas que tenemos que completar y cuáles son sus entradas:
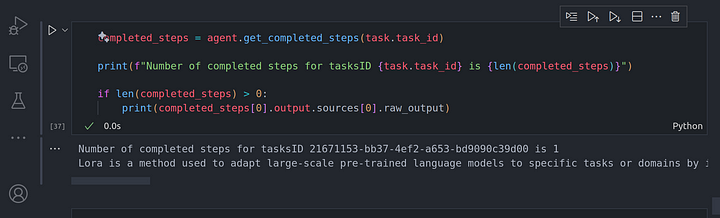
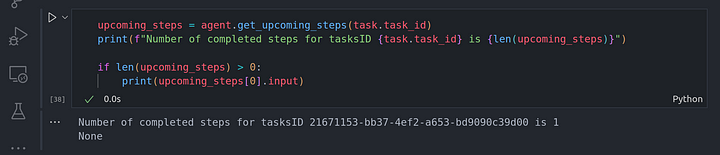
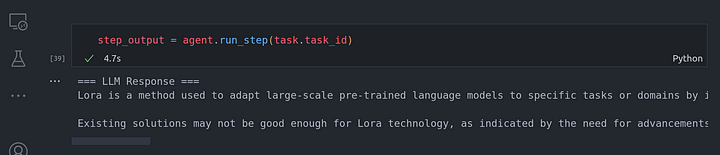
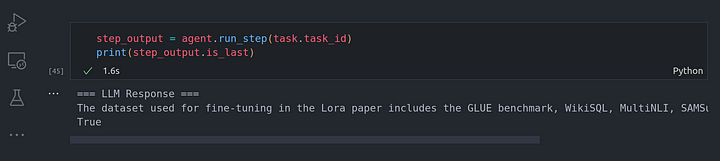
También podemos comprobar si este es el último paso que necesitábamos ejecutar:
print(step_output.is_last)

Se puede ver que hemos obtenido True, concretamente, un Python true indicando que era el último paso en la ejecución de la tarea.
También podemos sobreescribirlo proporcionando nuestras tareas personalizadas, esto puede actuar como un humano corrigiendo al agente sobre lo que necesita hacer, una especie de feedback guía humano.
Para ello, voy a crear una nueva tarea, y luego añadir la retroalimentación humana en el bucle y cambiar la pregunta de la tarea.
task = agent.create_task(
"Explain to me what is Lora and why it's being used."
"Are existing solutions not good enough?"
)
step_output = agent.run_step(
task.task_id, input="Explain to me the dataset used to fine-tune in the Lora paper."
)
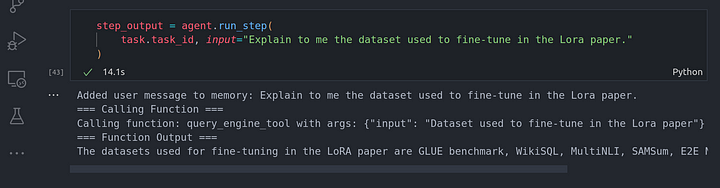
Tenemos que comprobar si es el último paso, esto es importante o te dará un error. No sé por qué tuvieron que hacer eso.
Una vez hecho esto, podemos pasar a obtener la respuesta definitiva:
response = agent.finalize_response(task.task_id)
print(str(response))

Conclusión
Enhorabuena por haber llegado hasta aquí. En este artículo hemos repasado cómo trabajar con un bucle de razonamiento multipaso en un sistema RAG agéntico. No sólo hemos visto la implementación de alto nivel, sino también el funcionamiento a bajo nivel del bucle de razonamiento multipaso y la posibilidad de proporcionar feedback al agente (feedback humano en el bucle).
Espero que este artículo te proporcione una clara comprensión de la capacidad de razonamiento multipaso de un agente. En el próximo artículo, veremos cómo realizar capacidades RAG utilizando múltiples documentos.
Otras plataformas en las que puedes ponerte en contacto conmigo:
Referencias