

En este artículo, profundizamos en los fundamentos de Agentic RAG y construimos con éxito una aplicación Agentic RAG sencilla. Exploramos los conceptos básicos y los pasos prácticos para poner en marcha nuestra aplicación inicial utilizando el motor de consultas del enrutador. En este artículo de seguimiento, elevaremos nuestros conocimientos incorporando una potente característica: la llamada a funciones, también conocida como llamada a herramientas. Esta mejora ampliará significativamente las capacidades de nuestros agentes RAG. Así que, embarquémonos en la siguiente fase de nuestro viaje y exploremos cómo integrar la llamada a funciones en nuestras aplicaciones RAG.
Tabla de contenidos
Qué es una herramienta
Una herramienta es esencialmente una función Python que pasamos a los LLMs, permitiéndoles interactuar con el mundo externo. Puedes escribir una herramienta que interactúe con tu API personal, y el LLM puede entonces llamar a esta herramienta, pasando los argumentos necesarios basados en la consulta del usuario. Esto permite interacciones dinámicas y poderosas entre el LLM y sistemas externos.
Por qué la llamada a herramientas
Puede que al principio te preguntes por qué necesitamos la llamada a herramientas. Al fin y al cabo, la función principal del LLM en un sistema RAG es la síntesis. Entonces, ¿por qué necesita llamar a una función, también conocida como herramienta?
Bueno, si leíste el último artículo, ¿recuerdas cómo determinamos el mejor motor de rutas a ejecutar cuando trabajamos con el motor de consultas del enrutador? El LLM, utilizando un selector (LLMSingleSelector), fue capaz de elegir qué herramienta de motor de enrutamiento utilizar. Este es sólo un ejemplo de por qué necesitamos la llamada a herramientas.
Imagina que estamos construyendo un sistema de reservas con un LLM o queremos escribir automáticamente la salida de un pipeline RAG en un fichero usando un sistema basado en LLM. Tenemos que definir una función que se encargue de escribir el contenido en un archivo y, a continuación, pasar esta función al LLM. El LLM puede entonces determinar los argumentos necesarios para pasar al llamar a esta función. Esa función es una herramienta. Esperamos que estos ejemplos nos aclaren por qué necesitamos llamar a funciones.
Configuración e inicializaciones
Usaremos el entorno que configuramos en el último artículo. La única diferencia es que voy a crear un nuevo .ipynb que vamos a utilizar para este artículo de llamada a la herramienta.
Funciones de ejemplo para herramientas
Vamos a definir un par de funciones que podremos utilizar más adelante como herramientas. En este caso pueden ser cualquier tipo de funciones. Sólo asegúrate de tener dos cosas muy importantes en tus funciones:
- Anotaciones de tipo: Esto ayudará al LLM a saber qué tipo de datos o tipo de datos necesita pasar tu función o herramienta.
- Función do-strings: Esto le dará una descripción de la herramienta o función al LLM para que sepa para que puede ser usada la función o herramienta.
def add(x: int, y: int) -> int:
«»»Add two numbers together.»»»
return x + y
# substraction function
def sub(x: int, y: int) -> int:
«»»Substract two numbers.»»»
return x – y
# multiplication function
def mul(x: int, y: int) -> int:
«»»Multiply two numbers.»»»
return x * y
# get user information
def get_user_info(name: str) -> str:
«»»Get user information.»»»
data = {
«John Doe»: {
«age»: 30,
«location»: «USA»
},
«Jane Doe»: {
«age»: 25,
«location»: «UK»
}
}
return f’User name {name}, age is {data[name][«age»]} and location is {data[name][«location»]}’
Creando herramientas a partir de Funciones Python
Una vez que tenemos estas funciones definidas, podemos pasar a convertir estas funciones en herramientas que el LLM puede invocar. Para ello podemos utilizar el siguiente bloque de código:
from llama_index.core.tools import FunctionTool
addition_tool = FunctionTool.from_defaults(fn=add)
get_user_info_tool = FunctionTool.from_defaults(fn=get_user_info)
multiplication_tool = FunctionTool.from_defaults(fn=mul)
substraction_tool = FunctionTool.from_defaults(fn=sub)
tools = [addition_tool, get_user_info_tool, multiplication_tool, substraction_tool]
Probando la Llamada a Herramientas
Ahora que hemos conseguido convertir nuestras funciones Python en herramientas, vamos a probarlas pasándoles una consulta que requiera el uso de una de las herramientas.
from llama_index.llms.openai import OpenAI
llm = OpenAI(model=»gpt-3.5-turbo»)
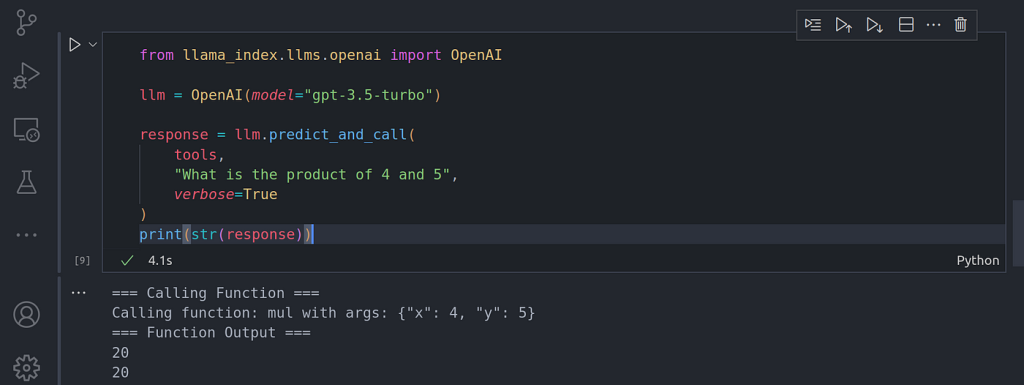
response = llm.predict_and_call(
tools,
«What is the product of 4 and 5»,
verbose=True
)
print(str(response))
response = llm.predict_and_call(
tools,
«Give more the details of John Doe»,
verbose=True
)
print(str(response))
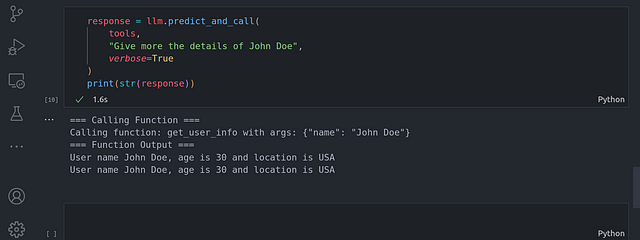
Aquí podemos ver no sólo que el LLM es capaz de saber a qué función llamar y a qué herramientas llamar, sino también qué parámetros pasar a esas funciones y herramientas llamadas.
Búsqueda vectorial con metadatos
Ya que el LLM es capaz de saber qué herramienta llamar y qué función pasar, podemos utilizar esto para pasar a la herramienta de búsqueda vectorial metadatos tales como el número de página del documento en el que queremos buscar.
Para crear la búsqueda con capacidad de filtrado de metadatos, primero necesitaremos construir una búsqueda vectorial simple, implementaremos todo lo que vimos en el primer artículo.
from llama_index.core import SimpleDirectoryReader
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=[«./datasets/lora_paper.pdf»]).load_data()
from llama_index.core.node_parser import SentenceSplitter
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
# LLM model
Settings.llm = OpenAI(model=»gpt-3.5-turbo»)
# embedding model
Settings.embed_model = OpenAIEmbedding(model=»text-embedding-ada-002″)
from llama_index.core import VectorStoreIndex
# vector store index
vector_index = VectorStoreIndex(nodes)
Añadir capacidad de filtrado de metadatos:
from llama_index.core.vector_stores import MetadataFilters
# Create vector search query engine
query_engine = vector_index.as_query_engine(
similarity_top_k=2,
filters=MetadataFilters.from_dicts(
[
{«key»: «page_label», «value»: «2»}
]
)
)
response = query_engine.query(
«Tell me about the Problem statement as explained»,
)
print(str(response))
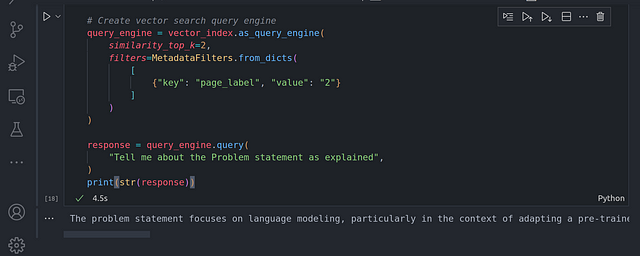
En el código anterior, limitamos la búsqueda únicamente a la página 2, donde se habla del planteamiento del problema en el documento de investigación. Podemos confirmar que la búsqueda sólo se realizó en la página 2 utilizando:
for n in response.source_nodes:
print(n.metadata)
print(«=============Text=============»)
print(n.get_text())
print(«=============Text=============»)
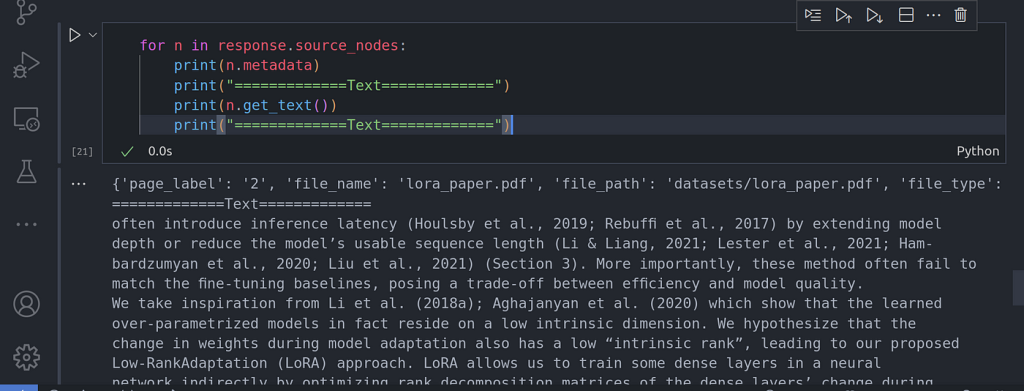
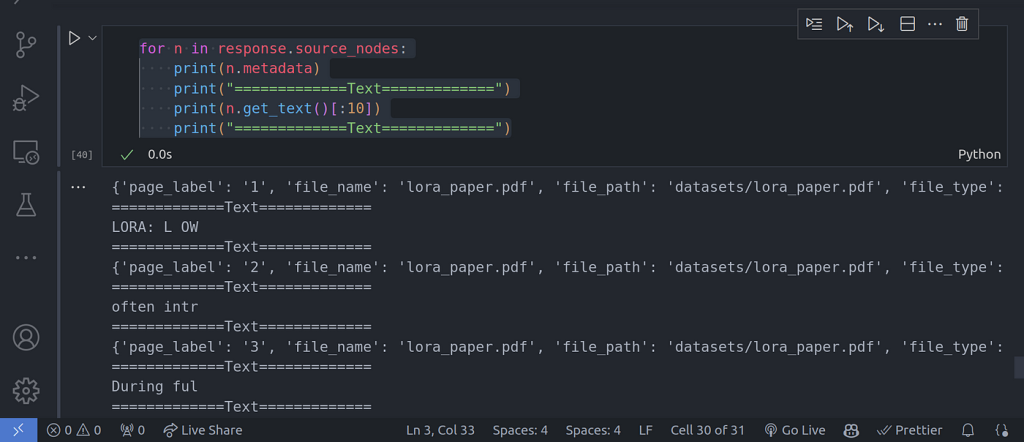
En la imagen de la ejecución del código anterior, puede ver que la búsqueda de los nodos se limita únicamente a la página número dos. También puede introducir otros metadatos.
Herramienta de recuperación automática
Ahora que somos capaces de recuperar contenido especificando otros metadatos. Una cosa que puede notar es que tuvimos que especificar manualmente el filtro de metadatos. En la mayoría de los casos, esto no es lo ideal. ¿Podemos obtener el LLM especificar en el propio filtro basado en lo que la consulta del usuario se pasó. Ejemplo:
«¿Qué se mencionó sobre el planteamiento del problema en la página 2?».
A partir de esta consulta, el LLM debería ser capaz de pasar en el filtro de metadatos el número de página como 2. Implementemos esto:
Primero implementemos la búsqueda vectorial:
from typing import List
from llama_index.core.vector_stores import FilterCondition
def vector_search_query(
query: str,
page_numbers: List[str]
) -> str:
«»»Conduct a vector search across an index using the following parameters:
query (str): This is the text string you want to embed and search for within the index.
page_numbers (List[str]): This parameter allows you to limit the search to
specific pages. If left empty, the search will encompass all pages in the index.
If page numbers are specified, the search will be filtered to only include those pages.
«»»
metadata_dicts = [
{«key»: «page_label», «value»: p} for p in page_numbers
]
query_engine = vector_index.as_query_engine(
similarity_top_k=2,
filters=MetadataFilters.from_dicts(
metadata_dicts,
condition=FilterCondition.OR
)
)
response = query_engine.query(query)
return response
vector_query_tool = FunctionTool.from_defaults(
name=»vector_search_tool»,
fn=vector_search_query
)
response = llm.predict_and_call(
[vector_query_tool],
«What was mentioned about the problem statement in page 2?»,
verbose=True
)
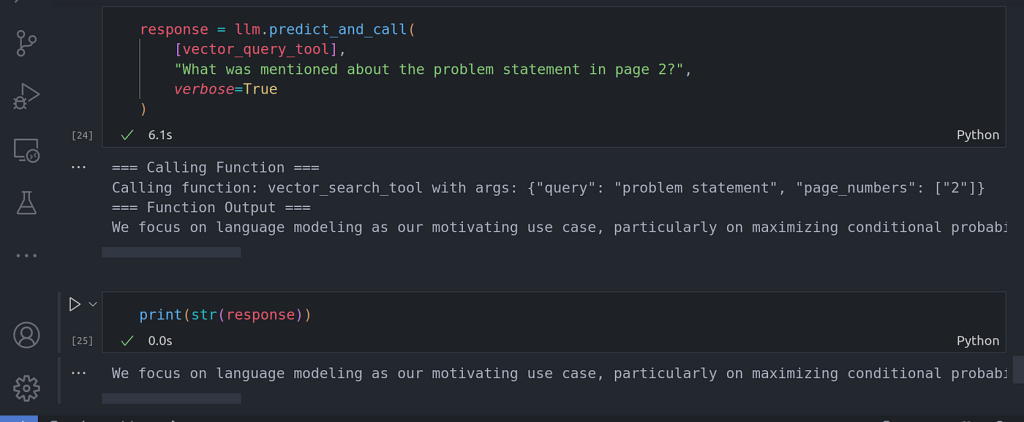
Ahora puede ver que la llamada a la función se realiza automáticamente pasando los metadatos correctos como página 2. El LLM fue capaz de inferir el filtro de metadatos de número de página. Hay otros filtros de metadatos que podemos utilizar, como los filtros de metadatos de pie de página.
Podemos confirmar que los datos fueron recuperados de la página 2 usando lo siguiente:
for n in response.source_nodes:
print(n.metadata)
print(«=============Text=============»)
print(n.get_text())
print(«=============Text=============»)
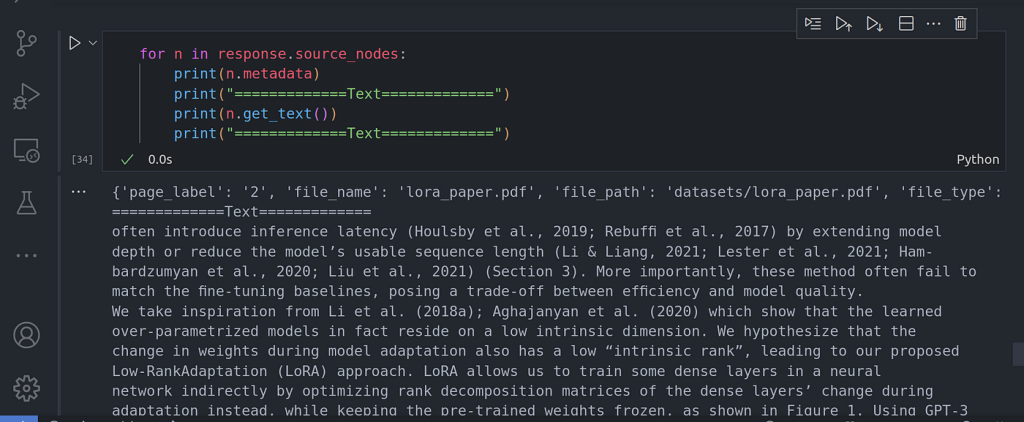
Ahora, incorporemos la herramienta de resumen para asegurarnos de que el enrutador es capaz de elegir la herramienta de motor de consulta correcta que debe utilizar.
from llama_index.core import SummaryIndex
from llama_index.core.tools import QueryEngineTool
summary_index = SummaryIndex(nodes)
summary_query_engine = summary_index.as_query_engine(
response_mode=»tree_summarize»,
use_async=True,
)
summary_tool = QueryEngineTool.from_defaults(
name=»summary_tool»,
query_engine=summary_query_engine,
description=(
«Useful for summarization questions related to the Lora paper.»
),
)
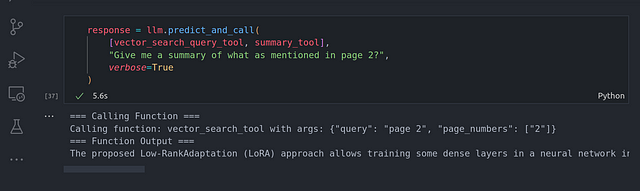
response = llm.predict_and_call(
[vector_search_query_tool, summary_tool],
«What was mentioned about the problem statement in page 2?»,
verbose=True
)
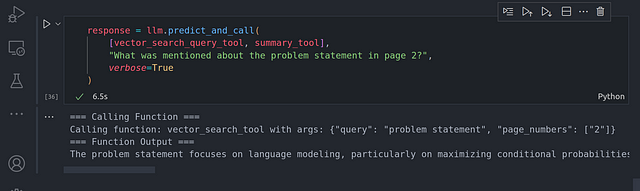
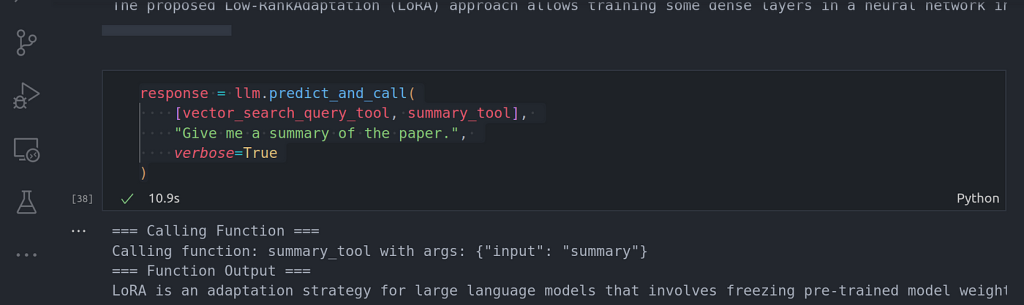
response = llm.predict_and_call(
[vector_search_query_tool, summary_tool],
«Give me a summary of the paper.»,
verbose=True
)
for n in response.source_nodes:
print(n.metadata)
print(«=============Text=============»)
print(n.get_text()[:10])
print(«=============Text=============»)
Conclusión
Enhorabuena por haber llegado hasta aquí. Hemos hecho una inmersión profunda en la llamada a herramientas. Hasta ahora todo lo que hemos hecho desde el primer artículo ha girado en torno a la llamada de herramientas de un solo paso donde todo se hace en un solo bucle.
Esto tiene algunas limitaciones, vamos a abordar esto en el próximo artículo cuando nos sumergimos en el bucle de razonamiento con el razonamiento de varios pasos.
Otras plataformas donde puedes ponerte en contacto conmigo:
¡Feliz codificación! Y hasta la próxima, que el mundo sigue girando.