

Las noticias, repositorios, artículos y recursos más interesantes del mes de junio resumidos en un solo artículo. No te pierdas este repositorio donde se recogerán e indexarán las noticias más destacables de IA y ML.
Tabla de contenidos
Investigación
- Golden Gate Claude. Publicamos un nuevo e importante artículo de investigación sobre la interpretación de grandes modelos lingüísticos, en el que empezamos a trazar el funcionamiento interno de nuestro modelo de IA, Claude 3 Sonnet. En la «mente» de Claude encontramos millones de conceptos que se activan cuando el modelo lee un texto o ve imágenes relevantes, a los que llamamos «características».
- Una mejor combinación de conductores y pasajeros: Aprendizaje por refuerzo en Lyft. El equipo de Lyft emparejó a conductores y pasajeros mediante el aprendizaje por refuerzo en línea, que se ve recompensado por los beneficios futuros de los conductores. Consiguieron 30 millones de dólares más al año para los pasajeros y mejoraron significativamente en tiempo real.
- Lecciones desde las trincheras sobre la evaluación reproducible de modelos lingüísticos. La evaluación de modelos lingüísticos es una tarea ardua, y la información sobre el proceso es escasa fuera de las grandes empresas. Este trabajo presenta un conjunto sólido y repetible de criterios de evaluación. En el apéndice se incluye un útil análisis de la evaluación de la perplejidad.
- RectifID: Personalización del flujo rectificado con guía de clasificador anclada. Los investigadores presentan un método novedoso para adaptar los modelos de difusión con el fin de producir imágenes que preserven la identidad a partir de referencias proporcionadas por el usuario. Esta estrategia dirige los modelos de difusión sin formación adicional mediante el uso de la guía del clasificador, en contraste con los métodos clásicos que necesitan una considerable formación específica del dominio.
- LoRA-Ensemble: Modelización eficiente de la incertidumbre para redes de autoatención. LoRA-Ensemble es una técnica de ensemble profunda y eficiente para redes de autoatención. Este método proporciona predicciones precisas y bien calibradas sin el importante coste computacional asociado a los métodos de ensemble típicos. Lo hace extendiendo Low-Rank Adaptation (LoRA) para ensamblaje implícito.
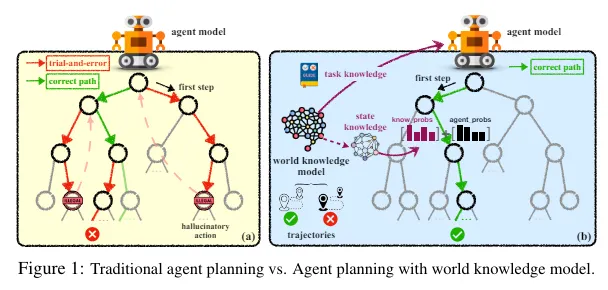
- Agent Planning with World Knowledge Model. Demuestra un rendimiento superior en comparación con varias líneas de base sólidas al adoptar LLM de código abierto como Mistral-7B y Gemma-7B. Introduce un modelo paramétrico de conocimiento del mundo para facilitar la planificación de agentes. El modelo de agente puede autosintetizar el conocimiento a partir de trayectorias expertas y muestreadas; esto se utiliza para entrenar el modelo de conocimiento del mundo. El conocimiento previo de la tarea se utiliza para guiar la planificación global y el conocimiento dinámico del estado se utiliza para guiar la planificación local.
- Mejora de la selección de respuestas en los LLM. Sugiere un marco de agregación de razonamiento jerárquico para mejorar las capacidades de razonamiento de los LLM; el método, conocido como Agregación de Razonamiento (AoR), elige las respuestas basándose en la evaluación de las cadenas de razonamiento; AoR emplea el muestreo dinámico para modificar el número de cadenas de razonamiento en relación con la complejidad de la tarea; hace uso de los resultados de la fase de evaluación para decidir si muestrea más cadenas de razonamiento; Un problema bien conocido de la votación por mayoría es que no funciona cuando la opción correcta está en minoría; AoR se concentra en evaluar las cadenas de razonamiento para mejorar la elección de la respuesta concluyente; AoR puede emplearse con diferentes LLM para mejorar el rendimiento en problemas de razonamiento difíciles, y supera a varios enfoques de conjunto bien conocidos.
- Efficient Inference of LLMs. sugiere una caché KV condensada en capas para lograr una inferencia eficaz en LLMs; puede lograr un rendimiento hasta 26 veces mayor que los transformadores de línea de base, manteniendo un rendimiento satisfactorio; sólo calcula y almacena en caché los valores clave (KV) de un pequeño número de capas, lo que conduce a un menor consumo de memoria y un rendimiento de inferencia mejorado.
- Mapeo de la mente de un modelo lingüístico de gran tamaño. Mediante el mapeo de millones de rasgos que se correlacionan con una amplia gama de conceptos, los antropólogos han mostrado una forma de comprender el funcionamiento interno de su enorme modelo lingüístico, Claude Sonnet. Esta interpretabilidad, que permite ciertas manipulaciones de estos atributos para dirigir los comportamientos del modelo, puede dar lugar a una IA más segura. La investigación indica un notable avance en la comprensión y mejora de los protocolos de seguridad de los modelos lingüísticos de la inteligencia artificial.
- Segmentación de objetos en escenarios complejos. Para mejorar la Segmentación de Expresiones Referenciales Generalizada (GRES), los investigadores han desarrollado el marco de Descodificación Semántica Jerárquica con Asistencia de Recuento (HDC). A diferencia de las técnicas anteriores, la HDC combina las correspondencias semánticas y transmite información complementaria sobre la modalidad a través de granularidades para mejorar la descodificación multinivel.
- Completación semántica de escenas eficiente con anotaciones de garabatos. Un novedoso método de compleción semántica de escenas denominado Scribble2Scene reduce la necesidad de un etiquetado exhaustivo.
- Clasificador semántico y espacial adaptable a nivel de píxel para la segmentación semántica. Las limitaciones de la segmentación semántica se han abordado con la introducción de un nuevo clasificador adaptativo semántico y espacial (SSA). Este novedoso método hace uso de máscaras gruesas para dirigir el ajuste del prototipo, mejorando el reconocimiento de grano fino y delineando los límites de las máscaras.
- RSBuilding: Towards General Remote Sensing Image Building Extraction and Change Detection with Foundation Model. Al integrar la extracción de edificios y la detección de cambios en un único modelo, RSBuilding presenta un método novedoso para descifrar edificios a partir de fotos de teledetección.
- Meteor: travesía basada en Mamba del razonamiento para grandes modelos lingüísticos y de visión. Esta investigación presenta Meteor, un novedoso modelo masivo de lenguaje y visión que es eficiente y emplea varias justificaciones para mejorar la comprensión y los tiempos de respuesta.
- Zip predice leyes de escalado dependientes de los datos. Las reglas de escalado permiten predecir el rendimiento de los modelos a tamaños específicos con una cantidad dada de datos. Obtenerlas es costoso. Para predecir una ley de escalado dependiente de los datos, esta investigación estudia el uso de la relación de compresión gzip como señal potente.
- El camino menos programado. Unas semanas antes, un nuevo optimizador de Meta circulaba como posible sustituto de Adam. El método, incluida la parte relativa a las actualizaciones en línea, se describe en mayor profundidad en este artículo. En general, parece un buen resultado, sobre todo en los casos en los que no se conoce el número completo de pasos de entrenamiento previstos al inicio del proceso de entrenamiento.
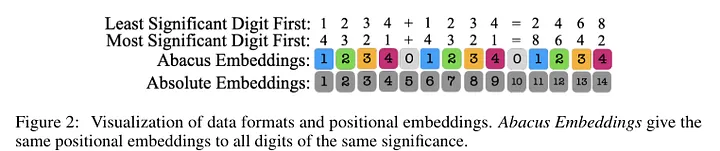
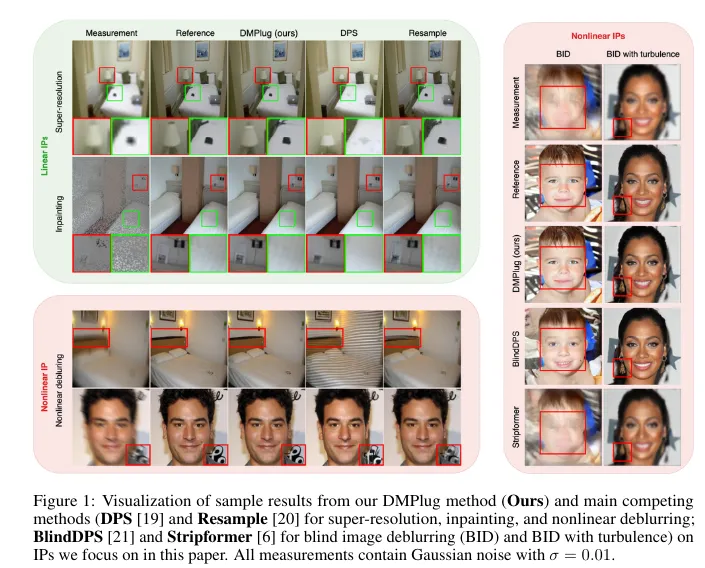
- Los transformadores pueden hacer operaciones aritméticas con las incrustaciones adecuadas. Los investigadores han añadido incrustaciones que codifican la posición de cada dígito con respecto al inicio del número, lo que ha mejorado el rendimiento de los transformadores en tareas aritméticas.DMPlug: Un método complementario para resolver problemas inversos con modelos de difusión.DMPlug es una nueva técnica complementaria que resuelve problemas inversos (PI) utilizando modelos de difusión (DM) previamente entrenados. DMPlug aborda eficientemente tanto la viabilidad del múltiple como la viabilidad de la medida tratando el proceso de difusión inversa como una función, en contraste con otras técnicas de intercalación.
- PatchScaler: Un modelo eficiente de difusión independiente del parche para la superresolución. PatchScaler es una técnica basada en la difusión que mejora enormemente la eficacia de la inferencia para la superresolución (SR) de una sola imagen.
- Reason3D: Búsqueda y razonamiento de segmentación 3D mediante un gran modelo de lenguaje. Se ha creado un revolucionario modelo de gran lenguaje multimodal llamado Reason3D para la comprensión exhaustiva de entornos 3D.
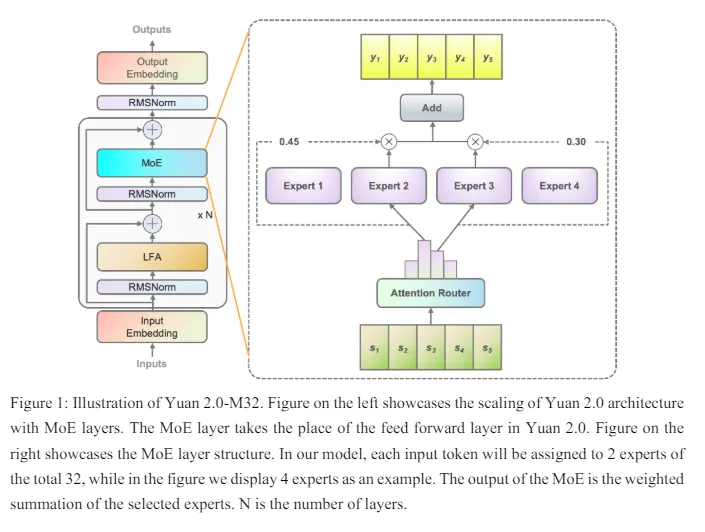
- Yuan 2.0-M32: Mezcla de Expertos con Router de Atención. Un modelo de Mezcla de Expertos con 40B de parámetros y 3,7B activos en todo momento es Yuan 2.0-M32. Aunque sólo utiliza una 19ª parte del cálculo, su rendimiento es similar al de Llama 3 70B. Parece extraordinariamente potente teniendo en cuenta su tamaño, ya que se ha entrenado con 2T de fichas.
- Leyes de escalado y entrenamiento óptimo más allá de duraciones de entrenamiento fijas. La programación de la tasa de aprendizaje Coseno empleada en las publicaciones de las leyes de escalado originales impide una pérdida óptima si el periodo Coseno no está en línea con el número total de pasos de entrenamiento. Por este motivo, resulta difícil entrenar suficientes modelos para producir leyes de escalado útiles. Con el fin de minimizar los costes de GPU para el desarrollo de leyes de escalado, este estudio presenta el concepto de una tasa de aprendizaje constante con un enfriamiento.
- Hacia la eliminación de imágenes de ultra alta definición: Una referencia y un método eficiente. Para abordar el problema de la extracción de fotografías de ultra alta definición (UHD), los investigadores han publicado un nuevo conjunto de datos denominado 4K-Rain13k, que consta de 13.000 pares de imágenes de resolución 4K.
- EasyAnimate, una solución integral para la generación de vídeos largos y de alta resolución. Los transformadores se utilizan en el método EasyAnimate para modificar la arquitectura DiT para la producción avanzada de vídeo en 3D. Para captar la dinámica temporal y garantizar transiciones de movimiento fluidas y fotogramas coherentes, este proyecto integra un bloque de módulo de movimiento.
- Modelos lingüísticos autoexplorables (SELM). La retroalimentación en línea se utiliza en los modelos lingüísticos autoexplorables (SELM), una técnica que mejora la optimización de preferencias en los LLM.
- T2V-Turbo: Breaking the Quality Bottleneck of Video Consistency Model with Mixed Reward Feedback. Cuando se aplica a modelos de vídeo, la destilación de consistencia reduce significativamente el número de procesos necesarios para producir contenidos.
Noticias
- Meta y xAI, de Elon Musk, pugnan por asociarse con el grupo de chatbot Character.ai El pionero de la IA Noam Shazeer lanzó Character.ai, una startup de juegos de rol en rápida expansión, y las empresas de Silicon Valley pugnan por asociarse. Esto ocurre en un momento en que numerosas grandes empresas están invirtiendo fuertemente en startups.
- Scarlett Johansson pidió a OpenAI que no utilizara su voz, y no está contenta con que lo hayan hecho. penAI ha negado que su voz ChatGPT esté basada en Johansson, pero lo cierto es que se parece mucho a ella.
- Ronda de financiación de serie B de xAI. xAI se complace en anunciar su ronda de financiación de serie B por valor de 6.000 millones de dólares.
- El iPhone tendrá una Siri mejor, un creador de emojis con IA, recapitulaciones inteligentes y mucho más con iOS 18. En junio de 2024, el gigante de Cupertino desvelará por fin su enfoque de la IA.

- Una nueva empresa crea mascotas digitales para Vision Pro de Apple. Una nueva empresa está saliendo de la clandestinidad con un plan para ofrecer mascotas digitales para el Apple Vision Pro que utilizan IA para leer y responder a las emociones humanas.
- Humane está buscando un comprador tras el decepcionante debut de la IA Pin. Al parecer, la startup cree que vale entre 750 y 1.000 millones de dólares a pesar de los profundos fallos de software y los problemas de hardware de su primer producto.
- El consejo de OpenAI forma un comité de seguridad. OpenAI declaró que su nuevo modelo fundacional estará capacitado, y estableció un Comité de Seguridad y Protección. A medida que avancen las capacidades del modelo, este comité se encargará de recomendar al consejo qué medidas deben tomarse.
- Anthropic contrata al antiguo responsable de seguridad de OpenAI para dirigir el nuevo equipo. Jan Leike, un destacado investigador de IA que a principios de este mes dimitió de OpenAI antes de criticar públicamente el enfoque de la empresa sobre la seguridad de la IA, se ha unido a Anthropic, rival de OpenAI, para dirigir un nuevo equipo de «superalineación».
- Nuevas capacidades de agente en Microsoft Copilot. En Build 2024, Microsoft presentó nuevas capacidades de Copilot, como Copilot Extensions and Connectors para una personalización sencilla, Team Copilot para la comunicación en equipo y agentes de IA a medida para automatizar operaciones. El objetivo de estas mejoras es aumentar la eficiencia de los procesos y la productividad de las empresas. Se prevé que las mejoras estén ampliamente disponibles a finales de 2024; actualmente se encuentran en una vista previa privada limitada.
- «Perdí la confianza»: Por qué implosionó el equipo de OpenAI encargado de salvaguardar a la humanidad. Información privilegiada de la empresa explica por qué se marchan los empleados preocupados por la seguridad.
- OpenAI envía un memorándum interno liberando a los antiguos empleados de los controvertidos acuerdos de salida. OpenAI se retractó el jueves de su controvertida decisión de obligar a sus antiguos empleados a elegir entre firmar un acuerdo de no despido que nunca expiraría o mantener su participación en la empresa.
- Opera incorpora Gemini de Google a sus navegadores. Los usuarios pueden acceder a Gemini a través del asistente de IA Aria en los navegadores Opera.
- Dos receptores mejor que uno para los fármacos contra la obesidad diseñados por la IA. Los compuestos predichos por el aprendizaje automático se adhieren a dos receptores implicados en el apetito y el peso.
- Nueva licencia de no producción de IA de Mistral. Mistral intenta encontrar un equilibrio entre el éxito empresarial y la transparencia. Tiene una nueva licencia diseñada para lograr ese equilibrio. Seguirá publicando nuevos proyectos bajo la nueva licencia MNPL, además de Apache 2.0.
- Sonic: Un modelo de voz de baja latencia para un habla realista. Los creadores de Mamba, versiones subcuadráticas de Transformer y SSM han lanzado un nuevo modelo. Su empresa Cartesia, de reciente creación, ha desarrollado una tecnología de generación de voz de sonido realista y velocidad vertiginosa. Esto sugiere que quieren instalarse en la zona de los ayudantes.
- Vox Media y The Atlantic firman acuerdos de contenidos con OpenAI. OpenAI sigue estableciendo alianzas con medios de comunicación en su intento de bloquear los datos de formación y evitar demandas.
- Modelo de código de Mistral. Presentamos Codestral, nuestro primer modelo de código. Codestral es un modelo de IA generativa de peso abierto diseñado explícitamente para tareas de generación de código.
- OpenAI contrata a 100.000 trabajadores de PwC para el nivel empresarial de ChatGPT y PwC se convierte en su primer socio de reventa. OpenAI anunció el miércoles que ha contratado a un importante cliente empresarial que espera que indique cómo podría producirse un efecto similar en el mundo laboral. PwC, el gigante de la consultoría de gestión, se convertirá en el mayor cliente de OpenAI hasta la fecha, con 100.000 usuarios.
- Los planes de IA de Apple incluyen una «caja negra» para los datos en la nube. Apple pretende procesar los datos de las aplicaciones de IA dentro de una caja negra virtual. El concepto, conocido internamente como «chips de Apple en centros de datos» (ACDC, por sus siglas en inglés), implicaría el uso exclusivo de hardware de Apple para realizar el procesamiento de IA en la nube. La idea es que controle tanto el hardware como el software de sus servidores, lo que le permitiría diseñar sistemas más seguros.
- Presentación de Perplexity Pages. El motor de búsqueda Perplexity ha anunciado un nuevo producto creado por IA para producir artefactos de investigación compartibles y duraderos.
- Autodesk adquiere Wonder Dynamics, una empresa de VFX basada en IA. Autodesk, el gigante de las herramientas 3D, ha adquirido Wonder Dynamics, una empresa emergente que permite a los creadores crear personajes y efectos visuales complejos de forma rápida y sencilla mediante el análisis de imágenes con IA.
- La IA de Anthropic te permite crear robots que trabajen para ti. Anthropic lanza una nueva función para su chatbot Claude AI que permitirá a cualquiera crear un asistente de correo electrónico, un bot para comprar zapatos u otras soluciones personalizadas. Se llama «uso de herramientas» (o «llamada a funciones») y se conecta a cualquier API externa que elijas.
- Patronus AI recauda 17 millones de dólares para detectar errores LLM a escala. La financiación de serie A liderada por Glenn Solomon de Notable Capital subraya la urgente necesidad de las empresas de desplegar grandes modelos lingüísticos con confianza
- Un rival de Neuralink bate el récord de chips cerebrales con 4.096 electrodos en cerebro humano. La empresa Precision Neuroscience, especializada en interfaces cerebro-ordenador, ha establecido un nuevo récord mundial en el número de electrodos de estimulación neuronal colocados en el cerebro de un ser humano vivo: 4.096, superando el récord anterior de 2.048 establecido el año pasado, según anunció la empresa el martes.
- Google añade funciones de inteligencia artificial a Chromebook. Google ha anunciado hoy nuevas funciones basadas en inteligencia artificial para su línea de dispositivos Chromebook Plus, como un asistente de escritura, un creador de fondos de pantalla y un acceso sencillo al chatbot Gemini de Google.
- ¿Qué es la ciencia? Los pesos pesados de la tecnología se pelean por su definición. Yann LeCun, pionero de la IA, y Elon Musk se enfrentaron en un debate sobre la investigación moderna que suscitó miles de comentarios.
- Google refinará los resúmenes de búsqueda generados por IA en respuesta a resultados extraños. Después de que la nueva función diga a la gente que coma piedras o añada pegamento a la salsa de la pizza, la empresa restringirá las búsquedas que devuelven resúmenes
- Un nuevo servicio de IA permite a los espectadores crear programas de televisión. ¿Estamos condenados? Showrunner permitirá a los usuarios generar episodios con instrucciones, lo que podría ser un paso alarmante o una novedad pasajera.
Recursos
- Mistral-finetune. mistral-finetune es una base de código ligera que permite un ajuste fino de los modelos de Mistral eficiente en cuanto a memoria y rendimiento. Se basa en LoRA, un paradigma de entrenamiento en el que la mayoría de los pesos se congelan y sólo se entrena un 1-2% de pesos adicionales en forma de perturbaciones matriciales de bajo rango.
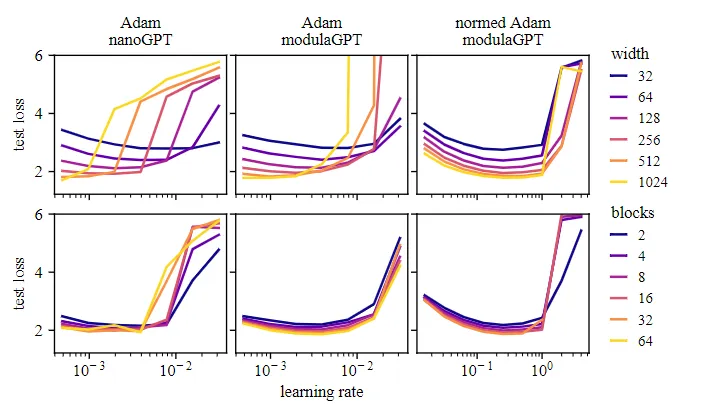
- Modula. Una novedosa técnica denominada norma modular permite a las redes neuronales escalar el entrenamiento de forma eficaz en un rango de tamaños de red mediante la normalización de las actualizaciones de pesos.
- MobileNet-V4. MobileNet es un modelo de visión por ordenador extremadamente rápido y eficaz. Los dispositivos periféricos pueden ejecutarlo. Este artículo de blog describe el nuevo modelo y algunas modificaciones contemporáneas que se le han hecho.
- Características multidimensionales. Este proyecto desafía la hipótesis de la representación lineal examinando si los modelos lingüísticos computan utilizando características multidimensionales.
- Llamafile 0.8.6, referencia para CPU. Gracias a los últimos avances del proyecto Llamafile de Mozilla, ahora es posible ejecutar la inferencia del modelo insignia de Mistral a 20 tokens por segundo en una CPU básica.
- Riesgos y oportunidades de la IA generativa de código abierto. Examina el potencial y los peligros asociados a los modelos de IA generativa de código abierto y defiende que las ventajas generales de estos modelos superan sus inconvenientes.
- How Far Are We From AGI. ofrece un resumen de las tácticas necesarias para alcanzar la inteligencia general artificial (AGI), incluyendo un estudio exhaustivo, un debate y puntos de vista únicos. También aborda cuestiones importantes relativas al futuro próximo de la AGI.
- Efficient Multimodal LLMs. Ofrece un análisis exhaustivo y metódico del estado actual de los grandes modelos lingüísticos multimodales eficientes; abarca aplicaciones, limitaciones, posibles direcciones futuras y estructuras y técnicas eficientes.
- Scientific Applications of LLMs. Presenta INDUS, un conjunto completo de LLM que incluye pequeños modelos destilados, un modelo codificador y modelos de incrustación para las ciencias de la Tierra, la biología, la física y las ciencias planetarias, entre otros temas.
- Guide for Evaluating LLMs. Ofrece consejos y lecciones para evaluar grandes modelos lingüísticos (LLM); también cubre las mejores prácticas y los problemas potenciales, e introduce un marco de código abierto para la evaluación de LLM.
- Medidas de recuperación de la información. Para construir un sistema GAR es necesario conocer la eficacia de la parte de recuperación. Esta caja de herramientas proporciona una amplia gama de métricas de rendimiento eficaces para la recuperación de información.
- Guía para crear diagramas de circuitos neuronales. Esta es una guía para dibujar Diagramas de Circuitos Neuronales por Vincent Abbott del documento Neural Circuit Diagrams: Robust Diagrams for the Communication, Implementation, and Analysis of Deep Learning Architectures. Permite expresar de forma exhaustiva los algoritmos de aprendizaje profundo mediante un novedoso esquema diagramático.
- InstructAvatar: control de emociones y movimientos guiado por texto para la generación de avatares. Un novedoso modelo llamado InstructAvatar utiliza la dirección de texto para generar avatares 2D que son emocionalmente expresivos.
- Marigold Pipelines para tareas de visión por computadora. Los difusores ahora pueden utilizar uno de los mejores modelos de profundidad como tubería. Este tutorial explica cómo utilizar el modelo, qué puede hacer con él y cómo acondicionar las latentes del primer cuadro para que funcione con videos sin esfuerzo.
- Reproducción de GPT-2 (124M) en llm.c en 90 minutos por 20 dólares. Andrej Karpathy ha puesto a disposición una versión de LLM C, una implementación GPT-2 autónoma y solitaria diseñada para replicar el conjunto de modelos de 2019. La biblioteca puede entrenar el más simple de estos modelos en aproximadamente 90 minutos con esta última versión. Tiene pocas dependencias y se ejecuta de principio a fin.
- Desacoplamiento de estilo de contenido para transferencia de maquillaje no supervisada sin generar pseudoverdad fundamental. Una técnica innovadora para mejorar las tareas de transferencia de maquillaje sin depender de imágenes de destino genuinas es la transferencia de maquillaje desacoplada por estilo de contenido (CSD-MT). LaVague.LaVague es un marco de modelo de acción grande de código abierto para desarrollar agentes web de IA. Nuestros agentes web toman un objetivo, como “Imprimir los pasos de instalación para la biblioteca de difusores de Hugging Face” y realizan las acciones necesarias para lograr este objetivo aprovechando nuestros dos componentes principales.
- PRISMA: Un modelo básico para la química de la vida. El modelo PRISM (Representaciones preentrenadas informadas por enmascaramiento espectral) de Enveda se entrenó en 1.200 millones de espectros de masas de moléculas pequeñas, el mayor conjunto de entrenamiento de espectros de masas de moléculas pequeñas jamás ensamblado.
- Escalar la clasificación privada. Scale ha creado una tabla de clasificación de evaluación de modelos de lenguaje privado. Aunque el orden no es tan sorprendente, vale la pena señalar que el Llama 3 70B frecuentemente supera a Claude Opus en términos de seguimiento de instrucciones.
- controlnet-scribble-sdxl-1.0. Dibujar líneas aleatorias se puede utilizar como datos condicionantes para la creación de imágenes utilizando Scribble ControlNet. Tiene un rendimiento sólido y se entrenó en una cantidad significativamente mayor de fotografías posteriores al entrenamiento que otros ControlNets.
Perspectivas
- La revolución de la comunicación de la IA: ahora todos hablamos con las computadoras. El modelo de IA más reciente de OpenAI, GPT-4o, permite la comunicación en tiempo real entre personas y máquinas agregando visión y audio a sus capacidades basadas en texto. La revolución de la IA trae consigo una nueva ola de interacciones entre los humanos y la IA y, finalmente, la propia IA. Estas interacciones probablemente tendrán un impacto en nuestros hábitos sociales y estructuras comerciales. El impacto de esta tecnología en la comunicación humana se desarrollará a medida que avance, posiblemente estimulando el desarrollo de negocios y software creativos.
- No quiero pasar mi única y preciosa vida lidiando con la búsqueda de inteligencia artificial de Google. El retraso no deseado de tres segundos que la herramienta de búsqueda de inteligencia artificial de Google agrega a los resultados de búsqueda está volviendo locos a los usuarios al interferir con su experiencia y mostrar contenido irrelevante.
- Los LLM no son adecuados para la lluvia de ideas (avanzada). Cuando se trata de una lluvia de ideas verdaderamente creativa, los grandes modelos lingüísticos suelen terminar produciendo ideas basadas en el consenso en lugar de nociones originales.
- ¿Podría la IA ayudar a curar la “espiral descendente” de la soledad humana? Un informático dice que deberíamos adoptar las relaciones entre humanos y máquinas, pero otros expertos son más cautelosos
- El choque con OpenAI de Scarlett Johansson es solo el comienzo de disputas legales sobre inteligencia artificial. La afirmación de la estrella de Hollywood sobre la actualización ChatGPT utilizó una imitación de su voz resalta las tensiones sobre la tecnología que se acelera rápidamente

- TechScape: Lo que aprendimos de la cumbre mundial de IA en Corea del Sur. Un día y seis (muy largos) acuerdos después, ¿podemos considerar un éxito la reunión para definir el futuro de la regulación de la IA?
- El enfrentamiento con OpenAI de Scarlett Johansson es sólo el comienzo de disputas legales sobre la inteligencia artificial. La afirmación de la estrella de Hollywood de que la actualización ChatGPT utilizó una imitación de su voz resalta las tensiones sobre la rápida aceleración de la tecnología
- Tratando de domesticar la IA: la cumbre de Seúl señala obstáculos para la regulación. El Reino Unido promociona el “efecto Bletchley” de los institutos de seguridad, pero persiste la división sobre si limitar las capacidades de la IA
- Cómo crear una startup de IA que defina una categoría. Las empresas de IA deben adoptar una estrategia basada en el marketing para destacarse de la competencia y establecerse como líderes de categoría a medida que el campo de la IA cambia rápidamente. Las nuevas empresas de IA pueden acelerar la aceptación del mercado, remodelar la narrativa de la industria y posicionarse como líderes visionarios en su campo mediante la adopción de una estrategia basada en el marketing.

- Maneras de pensar sobre AGI. El consenso no es claro porque no existe un modelo teórico bien desarrollado de inteligencia general ni una explicación clara de por qué o cómo los LLM funcionan tan bien, a pesar de que algunos expertos piensan que la AGI puede lograrse. La conversación destaca la enorme cantidad de preguntas sin respuesta que rodean a AGI, reconociendo tanto sus posibles ventajas como desventajas al mismo tiempo que establece comparaciones entre la teología y la metodología empírica del Programa Apolo.
- La revolución de la IA llega a los robots: ¿cómo los cambiará? La combinación de inteligencia artificial y robótica podría catapultar a ambas a nuevas alturas.
- Lo que ilustra GPT-4o sobre la regulación de la IA. Este artículo compara y contrasta los marcos a nivel de modelo, nivel de uso y nivel de conducta para analizar varios enfoques para la regulación de la IA. Sostiene que la regulación a nivel de uso, que puede generar una complejidad innecesaria y limitaciones inviables para el despliegue de la IA, es inferior a la regulación a nivel de conducta, que aplica las leyes actuales a las nuevas tecnologías con una precisión mínima. Un ejemplo de los inconvenientes de un enfoque a nivel de usuario son las limitaciones impuestas a la capacidad de la IA para inferir emociones por la reciente Ley de IA de la UE.
- ¿Cómo “piensa” ChatGPT? La psicología y la neurociencia abren grandes modelos de lenguaje de IA. Los investigadores se esfuerzan por aplicar ingeniería inversa a la inteligencia artificial y escanear los “cerebros” de los LLM para ver qué están haciendo, cómo y por qué.
- El sesgo angloamericano podría hacer de la IA generativa una jaula intelectual invisible. Los estudios muestran que las aplicaciones de inteligencia artificial (IA) generativa, como ChatGPT y otros grandes modelos lingüísticos, funcionan notablemente bien en inglés, pero no son tan competentes en otros idiomas. Esto enmascara un problema más insidioso.
- La IA no se comerá tu trabajo, pero sí tu salario. La IA plantea un peligro para la prima de habilidades asociada con las tareas, así como para la existencia de los empleos en sí, lo que podría resultar en una menor remuneración para los trabajadores calificados. La IA tiene el potencial de reorganizar las tareas laborales y reducir los obstáculos para completar las tareas, lo que resultaría en una mercantilización y una reducción en la capacidad de exigir un salario superior. Las ventajas gerenciales también pueden desaparecer a medida que se desarrolla la IA, particularmente a través de agentes de IA, lo que pondría a prueba la ventaja del ser humano en el circuito y erosionaría aún más las primas de habilidades.
- “Todos los ojos puestos en Rafah”: cómo las imágenes generadas por IA se extendieron por las redes sociales. Las publicaciones de celebridades sobre gráficos posteriores al ataque de las FDI ayudan a que se encuentre entre el contenido más compartido de la guerra entre Israel y Gaza.