

Tabla de contenidos
Introducción
Se ha establecido la importancia de los sistemas de Generación Mejorada por Recuperación (Retrieval-Augmented Generation, también conocidas como RAG) como mejora notable respecto a los Large Language Models (LLM) tradicionales.
Los sistemas RAG mejoran las capacidades de generación mediante la incorporación de datos externos a través de una fase de Recuperación de Información (IR), abordando las limitaciones de los LLM estándar.
Mientras que la mayor parte de la investigación se ha centrado en el aspecto generativo de los LLM dentro de los sistemas RAG, este estudio cubre un vacío al analizar críticamente la influencia de los componentes de IR en los sistemas RAG.
El artículo explora las características que debe poseer un prompt para una formulación eficaz de las peticiones, haciendo hincapié en el tipo de documentos que se van a recuperar.
La evaluación incluye factores como la relevancia del documento, la posición y el tamaño del contexto.Sorprendentemente, los resultados sugieren que la inclusión de documentos irrelevantes puede mejorar el rendimiento en más de un 30% en precisión, desafiando las suposiciones iniciales.
Los resultados ponen en relieve la necesidad de estrategias especializadas para integrar la recuperación con modelos de generación de lenguaje, lo que allana el camino para futuras investigaciones en este campo.
En esencia, los sistemas RAG constan de dos componentes fundamentales: el recuperador y el generador.
El componente de IR se encarga de obtener información externa para enriquecer la entrada del módulo de generación.
Por su parte, el componente de generación aprovecha la potencia de los LLM para producir textos coherentes y contextualmente relevantes.
Premisa fundamental en los sistemas RAG
El estudio observó que, en los sistemas RAG, los documentos asociados resultan más perjudiciales que los no relacionados.
Lo que resulta aún más inesperado es la revelación de que la incorporación de documentos ruidosos puede resultar ventajosa, lo que se traduce en una mejora de la precisión de hasta el 35%.
Estos resultados contrastan con la aplicación convencional de los sistemas de recuperación de información (IR) de cara al cliente, en la que los documentos relacionados suelen considerarse más aceptables que los no relacionados.
Un LLM puede dar una respuesta errónea debido a un recuperador que recupera datos relevantes y relacionados. Esto deja al LLM con la tarea de desambiguar para establecer el contexto correcto y los datos que coinciden con la tarea, y crea el riesgo de que el LLM responda a la pregunta de forma contextualmente correcta, pero objetivamente incorrecta.
Introducir ruido aleatorio puede corregir al LLM y ayudarle a responder más correctamente. Por supuesto, es necesario alcanzar un equilibrio óptimo.
Ejemplos prácticos
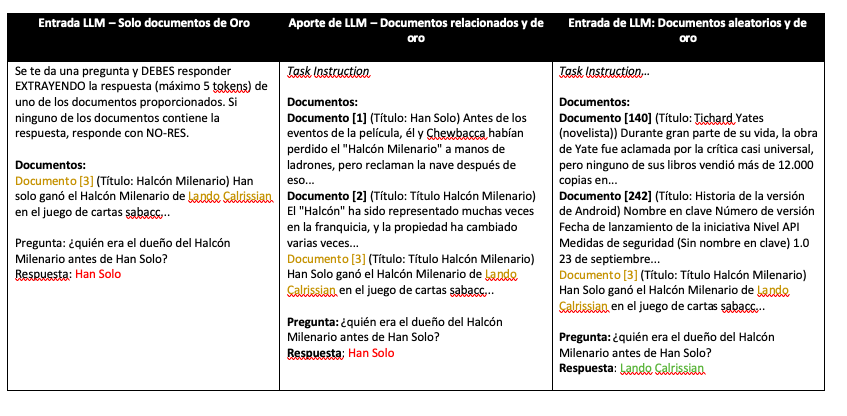
Entrada LLM – Sólo documentos de oro
Considerando la imagen anterior, el ejemplo de la izquierda muestra una entrada LLM con una salida errónea, en rojo. La entrada LLM incluye una instrucción de tarea, seguida del contexto / documento. Y finalmente la consulta.
La respuesta del LLM está marcada como Respuesta. El color dorado resalta tanto el documento dorado como la respuesta correcta, Lando Calrissian, indicando la fuente esperada y el contenido de la respuesta correcta.
Entrada LLM – Documentos relacionados y de oro
El ejemplo del medio; entrada LLM con una salida errónea, resaltada en rojo. El contexto de la pregunta se compone de documentos relacionados y del documento de referencia cercano a la consulta.
Entrada LLM – Documentos aleatorios y de oro
El ejemplo de la derecha, ejemplo de entrada LLM con una salida correcta, resaltada en verde. El contexto de la consulta se compone de documentos aleatorios y el documento de referencia cercano a la consulta.
Para terminar
Este artículo presenta el primer estudio exhaustivo que examina cómo influyen los documentos recuperados en los marcos de generación mejorada por recuperación (Retrieval-Augmented Generation, RAG). El objetivo es comprender los rasgos necesarios en un recuperador para optimizar la construcción de consultas para sistemas RAG.
Colocar la información relevante cerca de la consulta es crucial para que el modelo la atienda eficazmente; de lo contrario, el modelo tiene dificultades.
Sorprendentemente, los documentos relacionados pueden ser muy perjudiciales para los sistemas RAG, mientras que los documentos irrelevantes y ruidosos, cuando se colocan correctamente, pueden mejorar la precisión del sistema.
La investigación aporta valiosas ideas sobre la dinámica de la recuperación de documentos en los marcos de la RAG, destacando la importancia de optimizar la colocación de los documentos pertinentes e irrelevantes para la precisión del sistema.
⭐️ Sígueme en LinkedIn para estar al día sobre la IA conversacional ⭐️
Actualmente soy el Evangelista Jefe @ HumanFirst. Exploro y escribo sobre todas las cosas en la intersección de la IA y el lenguaje; que van desde LLMs, Chatbots, Voicebots, marcos de desarrollo, espacios latentes centrados en datos y más.